
 Weipeng Xu
Weipeng Xu
Refrence: https://pytorch.org/tutorials/beginner/basics/autogradqs_tutorial.html
The back propagation algorithm is usually used in training nerual networks, in which the parameters are adjusted according to the gradient of the loss function with respect to the given parameter. This process can be impelmented in PyTorch with torch.autograd for any computaional graph.
Tensors, Functions and Computational graph
w: tensor([[-0.6828, 0.3332, -1.9763],
[-0.1963, 0.8592, 0.4308],
[ 0.0557, -2.1140, -0.9972],
[ 1.3912, -0.5062, 1.6108],
[ 0.5042, -0.6462, -0.2771]], requires_grad=True)
b: tensor([-0.4456, -1.4925, 0.9890], requires_grad=True)
z: tensor([ 0.6264, -3.5665, -0.2200], grad_fn=<AddBackward0>)
loss: 0.5572206974029541
The above codes define the following computational graph. The tensor w and b are the parameters to be optimized, so we set requires_grad=True.
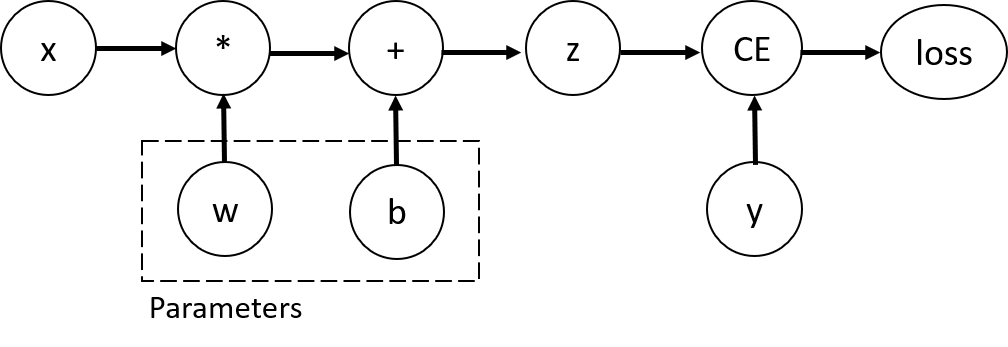
The tensors use Function object to constrcut the computational graph. This object knows how to compute the function in the forward and how to compute the derivatives in the backward propagation. The latter is stored in the grad_fn of a tensor. Also see Function.
Gradient function for x: None Gradient function for y: None Gradient function for w: None Gradient function for b: None Gradient function for z: <AddBackward0 object at 0x7f18b82b8820> Gradient function for loss: <BinaryCrossEntropyWithLogitsBackward0 object at 0x7f18b855f250>
Computing Gradients
To compute the derivatives
we can use
tensor([[2.3895, 0.1008, 1.6324],
[2.3895, 0.1008, 1.6324],
[2.3895, 0.1008, 1.6324],
[2.3895, 0.1008, 1.6324],
[2.3895, 0.1008, 1.6324]])
tensor([2.3895, 0.1008, 1.6324])
The gradient information will
None None None /tmp/ipykernel_61/3184559473.py:7: UserWarning: The .grad attribute of a Tensor that is not a leaf Tensor is being accessed. Its .grad attribute won't be populated during autograd.backward(). If you indeed want the .grad field to be populated for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-leaf Tensor by mistake, make sure you access the leaf Tensor instead. See github.com/pytorch/pytorch/pull/30531 for more informations. (Triggered internally at aten/src/ATen/core/TensorBody.h:489.) print(z.grad)
Disable Gradient Tracking
Somtimes we don't want to do the gradient tracking, for example
mark some paramters in NN as forzen paramters
speed up computations when you only need to do the forward pass
At thsi time, we can stop gradient trackling by
True False True False
More on Computational Graphs
Conceptually, autograd keeps a record of data (tensors) and all executed operations (along with the resulting new tensors) in a directed acyclic graph (DAG) consisting of Function objects. In this DAG, leaves are the input tensors, roots are the output tensors. By tracing this graph from roots to leaves, you can automatically compute the gradients using the chain rule.
In the forward pass, autograd does two things simultaneously:
run the requested operation to compute a resulting tensor
maintain the operation's gradient function in the DAG
The backward pass begins after the .backward() being called on the DAG root. Then autograd
computes the gradients from each
.grad_fnaccumulates them in the respective tensor's
.gradattributeusing the chain rule, propagates all the way to the leaf tensors
The DAGs in PyTorch are dynamic, which means that after each backward call, autograd will starts populating a new graph.
Tensor Gradients and Jacobian Products
When the loss function not a scalar but an arbitary tensor, PyTorch allows us to compute the Jacobian product but not the actual gradient.
With the input and the output we have the following Jacobian marix Then we can calculated the Jacobian Product for a given vector by
First call
tensor([[4., 2., 2., 2., 2.],
[2., 4., 2., 2., 2.],
[2., 2., 4., 2., 2.],
[2., 2., 2., 4., 2.]])
Second call
tensor([[8., 4., 4., 4., 4.],
[4., 8., 4., 4., 4.],
[4., 4., 8., 4., 4.],
[4., 4., 4., 8., 4.]])
Call after zeroing gradients
tensor([[4., 2., 2., 2., 2.],
[2., 4., 2., 2., 2.],
[2., 2., 4., 2., 2.],
[2., 2., 2., 4., 2.]])
Further Reading
See Automatic Mechanics.


