


UMAP降维算法
UMPA(Uniform Manifold Approximation and Projection)是一种基于流形学习技术和拓扑数据分析思想的降维算法。它为流形学习和降维提供了一个非常通用的框架,同时也能提供具体的实现方法。本文将讨论该算法在实践中是如何工作的。虽然有更深层次的数学基础,但为了普通读者的可读性,这些基础只是参考和链接。如果您想了解数学描述,请参阅 UMAP 论文。
UMAP的名称涵盖了其主要原理和设计思想:
Uniform(均匀):UMAP假设数据样本均匀分布在流形上,但实际情况往往是不均匀的。这引入了距离可变性的概念,即空间在不同位置会扭曲,根据数据的密度而变化。UMAP的设计目标是尽可能减小这种均匀性假设的影响,以便更好地保留数据的全局结构
Manifold(流形):流形是一种数学概念,用于描述在每个点附近局部类似于欧几里得空间的拓扑空间。UMAP旨在在低维空间中保留数据流形的结构,以便更好地捕捉数据的内在关系。
Projection(投影):UMAP通过将高维数据投影到低维空间来实现降维。这意味着它将高维数据点映射到一个较低维度的空间,以便更好地可视化和分析数据。
Approximation(近似):UMAP算法使用有限的数据样本来近似表示数据流形,而不是考虑整个流形。这意味着它基于样本数据来构建流形的估计,以在低维空间中准确地再现数据的结构。
即假设可用数据样本均匀(Uniform)分布在流形(Manifold)上,可以从这些有限数据样本中近似(Approximation)并投影(Projection)到低维空间。
1.拓扑数据分析
单纯形(Simplex)是用简单组合成分构建拓扑空间的一种方法。,我们就可以把处理拓扑空间连续几何的复杂性简化为相对简单的组合和计数任务。这种处理几何和拓扑学的方法将是我们进行拓扑数据分析以及维度缩减的基础。
0-simplex是一个点,1-simplex是线段(在两个0-simplex之间),2-simplex是三角形(以三个1-simplex作为面),而 3-simplex是四面体(以四个2-simplex作为面)。这样简单结构可以轻松泛化到任意尺寸。
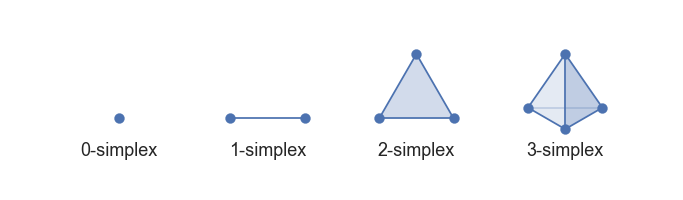
对于任意长度的数据,我们可以构造k-simplex,其有k+1个面构成。所以,我们始终可以通过几何形状实现对这个抽象集描述,方法是构造相应的几何单纯形。
以一个噪声正弦波的测试数据集为例
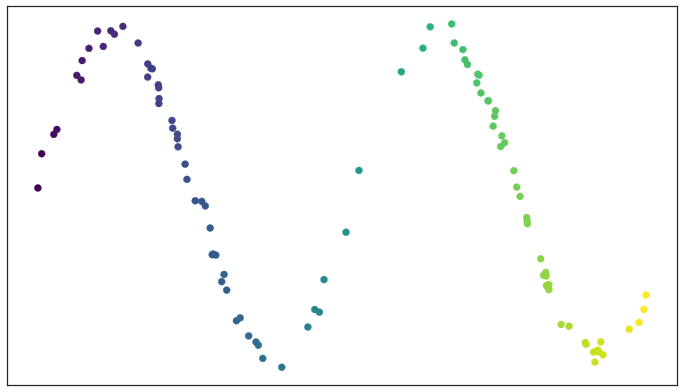
UMAP 首先使用 Nearest-Neighbor-Descent 算法找到最近的邻居。我们可以通过调整 UMAP 的 n_neighbors 超参数来指定我们想要使用多少个近邻点。
试验 n_neighbors 的数量很重要,因为它控制 UMAP 如何平衡数据中的局部和全局结构。它通过在尝试学习流形结构时限制局部邻域的大小来实现。
本质上,一个小的n_neighbors 值意味着我们需要一个非常局部的解释,准确地捕捉结构的细节。而较大的 n_neighbors 值意味着我们的估计将基于更大的区域,因此在整个流形中更广泛地准确。

接下来,我们要确保试图学习的流形结构不会导致许多不连通点。所以需要使用另一个超参数local_connectivity(默认值= 1)来解决这个潜在的问题
当我们设置local_connectivity=1 时,我们告诉高维空间中的每一个点都与另一个点相关联。
Local_connectivity(默认值为1):100%确定每个点至少连接到另一个点(连接数量的下限)。
n_neighbors(默认值为15):一个点直接连接到第 16 个以上的邻居的可能性为 0%,因为它在构建图时落在 UMAP 使用的局部区域之外。
2 到 15 : 有一定程度的确定性(>0% 但 <100%)一个点连接到它的第 2 个到第 15 个邻居。
由于我们采用了不同距离的方法,因此从每个点的角度来看,我们不可避免地会遇到边缘权重不对齐的情况。 例如,点 A→B 的边权重与 B→A 的边权重不同。

如果我们想将权重为 a 和 b 的两条不同的边合并在一起,那么我们应该有一个权重为 + − ⋅ 的单边。 考虑这一点的方法是,权重实际上是边(1-simplex)存在的概率。 组合权重就是至少存在一条边的概率。
最后,我们得到一个连接的邻域图

2.寻找低维表示
从高维空间学习近似流形后,UMAP 的下一步是将其投影(映射)到低维空间。
与第一步不同,我们不希望在低维空间表示中改变距离。相反,我们希望流形上的距离是相对于全局坐标系的标准欧几里得距离。
从可变距离到标准距离的转换的转换也会影响与最近邻居的距离。因此,我们必须传递另一个名为 min_dist(默认值=0.1)的超参数来定义嵌入点之间的最小距离。
本质上,我们可以控制点的最小分布,避免在低维嵌入中许多点相互重叠的情况。
指定最小距离后,该算法可以开始寻找较好的低维流形表示。 UMAP 通过最小化交叉熵 (CE)来实现。
最终目标是在低维表示中找到边的最优权值。这些最优权值随着上述交叉熵函数的最小化而出现,这个过程是可以通过随机梯度下降法来进行优化的
现在UMAP的工作完成了,我们得到了一个数组,其中包含了指定的低维空间中每个数据点的坐标。
3.Python中使用UMAP
上面我们已经介绍UMAP的知识点,现在我们在Python中进行实践。
我们将在MNIST数据集(手写数字的集合)上应用UMAP,以说明我们如何成功地分离数字并在低维空间中显示它们。
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple, https://pypi.ngc.nvidia.com Requirement already satisfied: umap-learn in /opt/conda/lib/python3.8/site-packages (0.5.4) Requirement already satisfied: numba>=0.51.2 in /opt/conda/lib/python3.8/site-packages (from umap-learn) (0.53.1) Requirement already satisfied: scikit-learn>=0.22 in /opt/conda/lib/python3.8/site-packages (from umap-learn) (0.24.2) Requirement already satisfied: numpy>=1.17 in /opt/conda/lib/python3.8/site-packages (from umap-learn) (1.22.4) Requirement already satisfied: pynndescent>=0.5 in /opt/conda/lib/python3.8/site-packages (from umap-learn) (0.5.10) Requirement already satisfied: scipy>=1.3.1 in /opt/conda/lib/python3.8/site-packages (from umap-learn) (1.6.3) Requirement already satisfied: tqdm in /opt/conda/lib/python3.8/site-packages (from umap-learn) (4.64.0) Requirement already satisfied: tbb>=2019.0 in /opt/conda/lib/python3.8/site-packages (from umap-learn) (2021.10.0) Requirement already satisfied: llvmlite<0.37,>=0.36.0rc1 in /opt/conda/lib/python3.8/site-packages (from numba>=0.51.2->umap-learn) (0.36.0) Requirement already satisfied: setuptools in /opt/conda/lib/python3.8/site-packages (from numba>=0.51.2->umap-learn) (59.5.0) Requirement already satisfied: joblib>=0.11 in /opt/conda/lib/python3.8/site-packages (from pynndescent>=0.5->umap-learn) (1.1.0) Requirement already satisfied: threadpoolctl>=2.0.0 in /opt/conda/lib/python3.8/site-packages (from scikit-learn>=0.22->umap-learn) (3.1.0) WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
/opt/conda/lib/python3.8/site-packages/tqdm/auto.py:22: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdm
接下来,我们加载MNIST数据并显示前10个手写数字的图像。

现在,我们将之前加载到X中的MNIST数字数据。X(1797,64)的形状告诉我们我们有1797个数字,每个数字由64个维度组成。
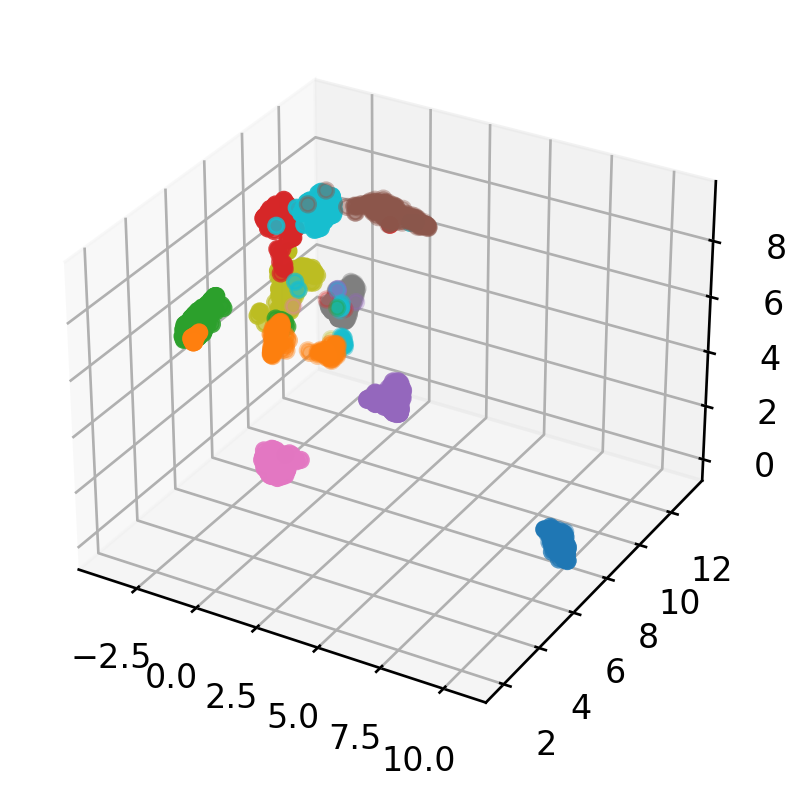
我们将使用UMAP将维数从64降到3,并打印转换后的数组的形状。
/opt/conda/lib/python3.8/site-packages/umap/umap_.py:1943: UserWarning: n_jobs value -1 overridden to 1 by setting random_state. Use no seed for parallelism.
warn(f"n_jobs value {self.n_jobs} overridden to 1 by setting random_state. Use no seed for parallelism.")
Shape of X_trans: (1797, 3)
接下来,我们将创建一个用于绘制3D散点图的函数,我们可以多次重用该函数来显示UMAP降维的结果。
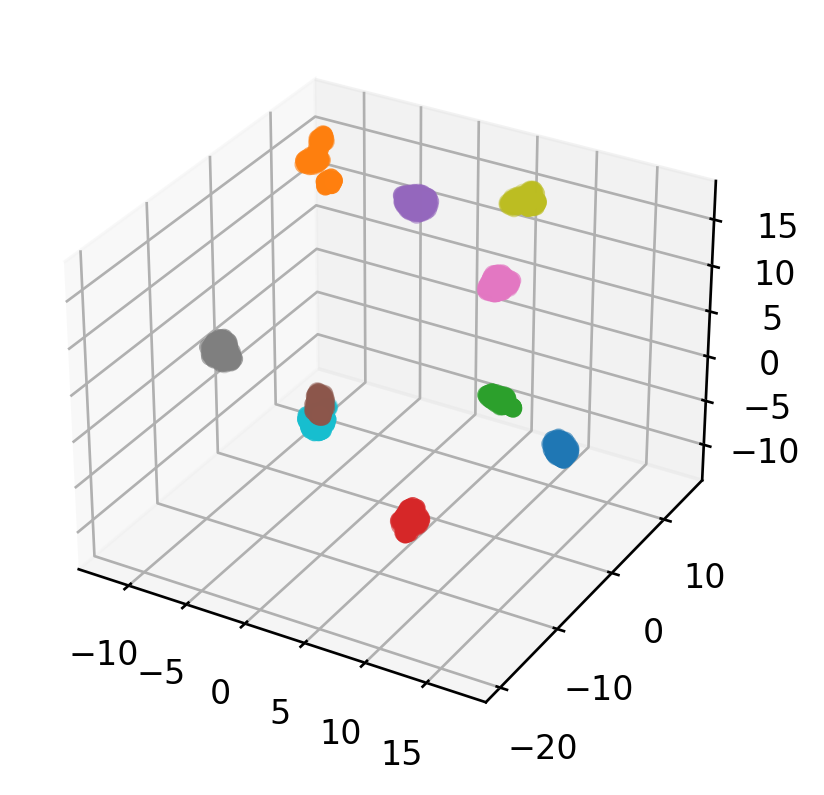
我们还可以以监督的方式使用UMAP来帮助减少数据的维数。
/opt/conda/lib/python3.8/site-packages/umap/umap_.py:1943: UserWarning: n_jobs value -1 overridden to 1 by setting random_state. Use no seed for parallelism.
warn(f"n_jobs value {self.n_jobs} overridden to 1 by setting random_state. Use no seed for parallelism.")
Shape of X_train_res: (1347, 3)
Shape of X_test_res: (450, 3)
4.总结
感谢您阅读这篇长文,我希望它的每一部分都能让您更深入地了解这个伟大的算法是如何运行的。
一般来说,UMAP具有坚实的数学基础,它通常比t-SNE等类似的降维算法做得更好。
UMAP的秘诀在于保持低维空间中相对全局距离的同时推断局部和全局结构的能力。
