


Geometry-Aware Fourier Neural Operator (Geo-FNO)
Abstract
深度学习代理模型在求解偏微分方程(PDEs)方面显示出了良好的前景。其中,傅里叶神经算子(FNO)在各种PDEs(如流体流动)上实现了良好的精度,并且与数值求解器相比速度显著加快。然而,FNO使用快速傅里叶变换(FFT),仅限于具有均匀网格的矩形域。在这项工作中,作者提出了一个新的框架,即Geo-FNO,用于求解任意几何形状上的PDEs。Geo-FNO学习将输入(物理)域(可能是不规则的)变形为具有均匀网格的潜在空间。在latent space中应用了带有FFT的FNO模型。由此产生的Geo-FNO模型既具有FFT的计算效率,又具有处理任意几何形状的灵活性。这样的Geo-FNO在输入格式方面也很灵活,即点云、网格和设计参数都是有效的输入。考虑了多种PDEs, 如弹性方程、塑性方程、欧拉方程和纳维-斯托克斯方程,以及正向建模和逆向设计问题。与标准数值求解器相比,Geo-FNO的速度提高了105倍,与现有的基于机器学习的PDE求解器(如标准FNO)相比,精度提高了两倍。
本文为边看边学系列,即笔者一边看paper一边学😂。notebook的前半部分为笔记,后半部分为示例代码。 完整运行代码只需要几分钟。
Paper: https://arxiv.org/abs/2207.
Paper Notes
Questions & Motivations
由于求解PDE在整个问题域上经常遇到的网格非均匀性,不管是自适应网格细化或者是动网格都无法解决传统数据方法在复杂几何上计算速度很慢的问题。
神经算子(Neural Operator)旨在以网格不变的方式直接学习偏微分方程的解算子,它对于离散化具有不变性,因此更适合求解偏微分方程†。然而FNO是通过FFT实现的,因此它只能用于具有均匀网格的矩形域。当将其应用于不规则域形状时,以前的工作通常将域嵌入到更大的矩形域中。然而,这种嵌入效率较低且浪费,特别是对于高度不规则的几何形状。先前在均匀与非均匀网格之间的插值方法,也可能会导致比较大的插值误差。
Propositions
- 一种感知的FNO框架(Geo-FNO),适用于任意几何形状。
- Geo-FNO 将不规则输入域变形为可以应用 FFT 的均匀潜在网格。 这种变形可以通过 FNO 架构以端到端的方式学习。用一个神经网络对变形进行建模。
- 在正向建模和逆向设计任务中对弹性、塑性、欧拉和纳维-斯托克斯方程的不同几何形状进行实验。 与数值求解器相比,Geo-FNO 的加速比高达105,并且与之前基于插值的方法相比,误差降低了一半。
原则上,这个Geo-FNO框架可以直接拓展到一般拓扑。即对复杂的输入拓扑分解为规则的子域。此外,也可以拓展到包括PDE约束的PINO(physics-informed neural operator)。
†:关于FNO的更多内容可以参考Notebook。FNO具有优越的成本精度权衡,它通过快速傅里叶变换 (FFT) 实现一系列计算全局卷积算子的层,然后混合频域权重和傅里叶逆变换。 这些全局卷积算子中散布着诸如 GeLU 之类的非线性变换。 通过组合全局卷积算子和非线性激活,FNO 可以逼近高度非线性和非局部解算子。 FNO 及其变体能够模拟许多偏微分方程,例如纳维-斯托克斯方程和地震波,进行高分辨率天气预报,并以前所未有的成本精度权衡来预测二氧化碳迁移。
下图为Geo-FNO的模型框架:
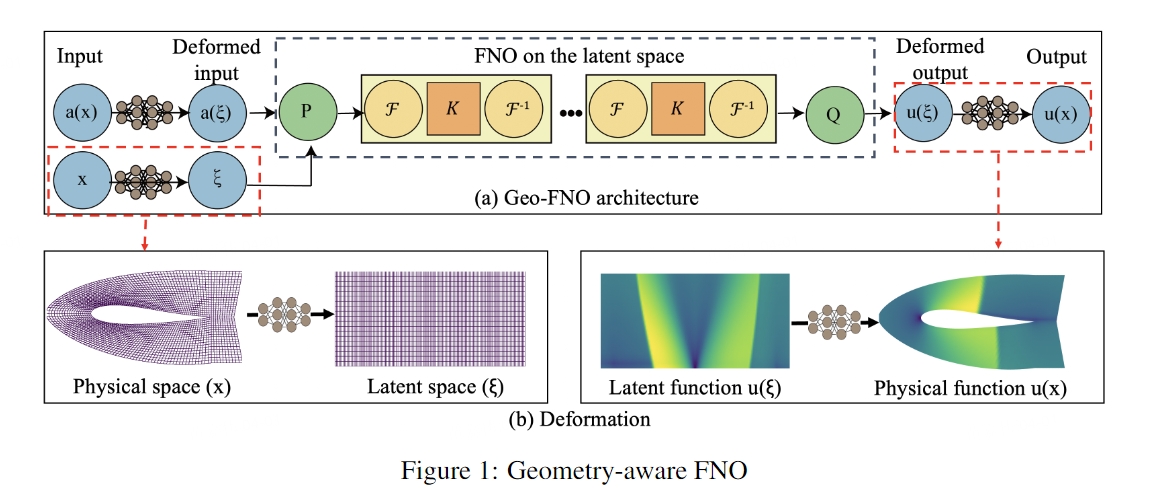
Preliminaries
为了简化和约束问题,一些假设:
- 假设所有域都是嵌入在某些背景欧几里得空间 Ω(例如 R3)中的有界可定向流形。
- 假设初始条件和边界条件都是固定的。
- 只考虑稳态解。
计算域或者几何的形状可以通过网格、函数和设计参数等多种方式给出。最常见的形式就是网格(点云)。函数的例子比如2D表面的边界函数,或者是SDF。设计参数可以是高、宽、体积、角度和半径等,这种形式适合一些设计问题。
Model: Geometry-Aware Fourier Neural Operator
核心思想:将物理空间变形为规则的计算空间,以便在其上进行FFT。
形式上,需要找到输入域 Da和单位环面 Dc=[0,1]d之间的微分同胚变形 φa(映射)。计算空间网格 Dc在所有输入域 Da之间共享,它满足均匀网格和标准傅里叶基。一旦确定了映射 φa,就可以在物理空间上产生自适应网格和变形傅里叶基。这样的映射可作用于函数、方程组和系统。
关于将物理空间上的函数变换到计算域谱空间上的推导,读者可以阅读原文章3.2节的内容。
值得注意的是,如果输入是规则的结构化网格,那么Geo-FNO简化为标准FNO。而对于哪些输入域具有不规则拓扑,与环面不同胚的PDEs问题,需要首先将输入域嵌入到更大的规则域中。这种嵌入对应于传统谱求解器中使用的傅里叶连续技术(Fourier continuation)。
Results
文中将Geo-FNO与其他机器学习模型在多种不同几何形状的PDEs进行了比较。这里我们以流体力学的NS方程为例,结果如下:
翼型流场和管流场结果绘图:
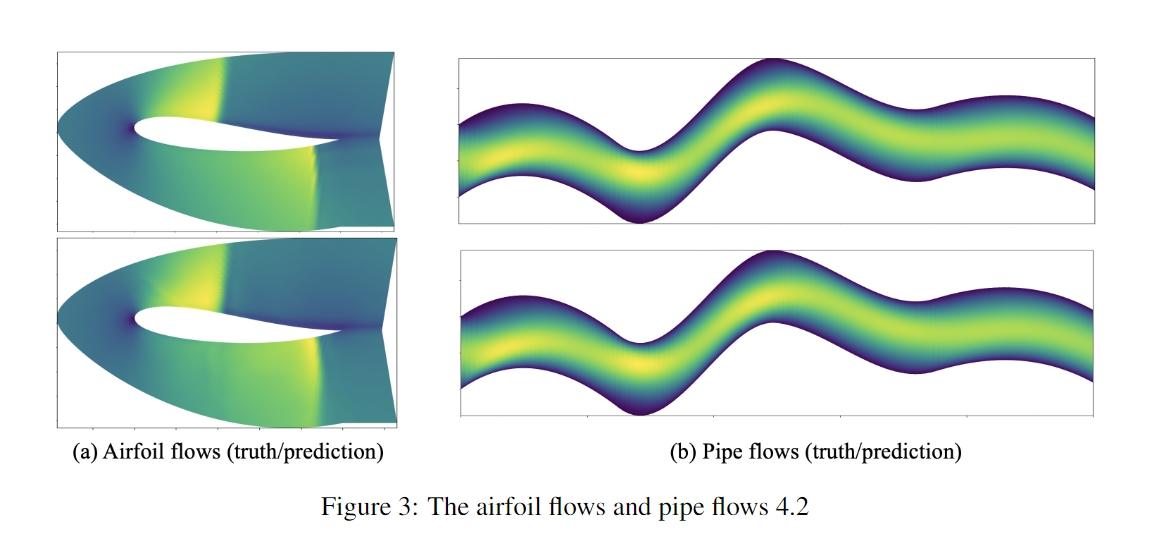
Geo-FNO可以应用于不规则域和非均匀网格。 它比现有基于 ML 的 PDE 求解器(例如标准 FNO 和 UNet)以及无网格方法(例如图神经算子 (GNO) 和 DeepONet)上的直接插值更准确。 同时,Geo-FNO 保持了标准 FNO 的速度,在所有实验中每个实例的推理时间约为 0.01 秒,它可以将机翼问题的数值求解器加速高达 105 倍。 下表为在机翼问题上各种模型的比较:
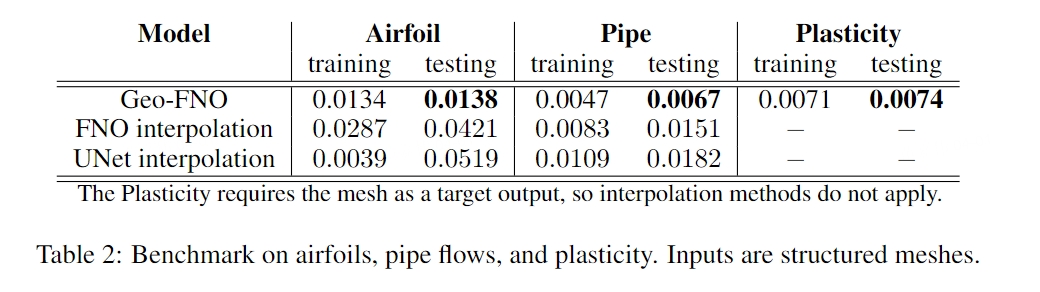
值得注意的是,作者在文章中提到:与具有固定启发式变形(R 网格)和(O 网格)的 Geo-FNO 相比,具有学习变形的 Geo-FNO 具有更好的精度。当然,这种结论针对的是非结构化网格。
Inverse design
关于反问题,这里主要指逆向设计。当 Geo-FNO 模型训练完成后,可以通过直接优化设计参数来达到设计目标。下图就是一个反问题的例子:
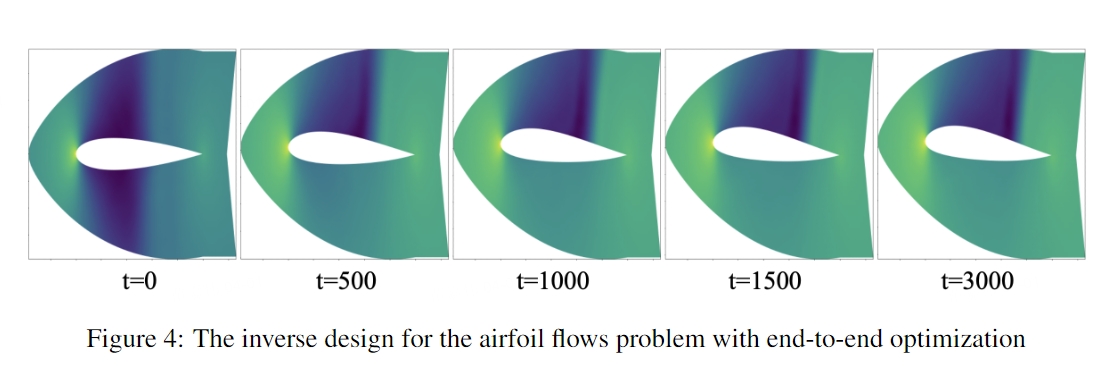
这里设定的设计目标是最小化阻力和最大化升力。首先训练从输入网格到输出压力场的模型映射,并以端到端的方式优化样条节点。从图中可以看出,经过优化迭代,得到的翼型变得不对称,上弯度更大,这增加了升力系数,符合物理直觉。数值求解器的模拟与预测相符,阻力为 0.04,升力为 0.29。
所有实验均在单个Nvidia 3090 GPU上执行。 如无特别提及,均用 500 个epoch训练所有模型,初始学习率为 0.001,每 100 个epoch衰减一半。 使用相对 L2 误差进行训练和测试。
Codes
下面我们以Elasticity (弹性问题)为例,展示Geo-FNO模型的框架和训练过程。
在 Bohrium Notebook 界面,你可以点击界面上方蓝色按钮 开始连接,选择 bohrium-notebook:2023-03-26 镜像及 c12_m92_1 * NVIDIA V100 节点配置,稍等片刻即可运行。
Code from Github
Fourier layer
FNO
Geometric Fourier Transform
Configs
load data and data normalization
torch.Size([1000, 42]) torch.Size([1000, 972, 1]) torch.Size([1000, 972, 2])
Training and evaluation
1482657 47234 Epoch:0 Time:1.135 Train loss:0.463, Test loss:0.290 Epoch:50 Time:1.128 Train loss:0.027, Test loss:0.033 Epoch:100 Time:1.135 Train loss:0.018, Test loss:0.028 Epoch:150 Time:1.136 Train loss:0.013, Test loss:0.025 Epoch:200 Time:1.139 Train loss:0.012, Test loss:0.025






