


【初稿】浅探听上去神奇又神秘的对比学习(Contrastive Learning)
©️ Copyright 2023 @ Authors
作者:
liutao@dp.tech 📨
日期:2023-07-12
共享协议:本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
快速开始:点击上方的 开始连接 按钮,选择 bohrium-notebook:2023-05-31镜像 和任意配置机型即可开始。

笔者按:这篇notebook的目的是“解密”对比学习(Contrastive Leanring, CL),因而刻意没有放很多数学公式,而是希望通过一些 例子,给予读者直观的理解。我想象的受众是对机器学习有基础了解,比如知道clustering和classification的大致区别,同时对于对比学习知之甚少但是十分好奇,想要获得大框架的理解,尤其是“对比”是如何实现的。不追求在这一篇文章里读到所有与对比学习相关的知识点,但是如果有兴趣可以通过文末的参考文献进一步深挖。
1. 简单的背景介绍
有关对比学习最早的工作之一可以追溯到1992年的一篇Nature文章:Becker & Hinton。相信不用笔者多提,稍微关注近几年计算机视觉和自然语言方向的朋友多少都听闻过对比学习,例如:图片分类算法CLIP里的C指的正是对比学习。不过,光听名字“对比学习”似乎有些抽象,把什么和什么作对比?和“对比”这个修辞手法也许有啥联系吗?不妨先看笔者准备的一个小例子,有点感觉。
2. 从一个生活里的例子出发
假设你买了一些西红柿🍅、茄子🍆、辣椒🌶、黄瓜🥒和龙虾🦞,回到家不小心掉在地上散落了一地。但你并不打算把它们混在一起一锅炖了……而是要用来做不同的菜(此处可以自行脑补🍅🍆🌶🥒🦞分别可以用来做什么菜,想饿了笔者不负责哈哈)。这时候你家的智慧猫咪踮着脚走了过来,看了看地上这一摊,抬起爪子把🍆和🥒扒拉到了一起,同时把🦞往远处推了推,接着抬头看向了你。目光交汇之际,你读懂了猫咪的想法:🍆和🥒都是长条形,放在一起储存比较方便,🦞不仅形状奇怪一点,而且不是蔬菜,适合分开储存。想到这里后,你于是很快根据“形状”和“荤素”将这一地的东西各自归纳。收拾完后走到客厅,你还发现你的7只一套、彩虹色的方形抱枕被扔的乱七八糟。狗狗旺财蹲在一旁傻乎乎地摇着尾巴,吐着舌头朝你笑。你话不多说,把抱枕根据它们的颜色重新排列整齐~
有的小伙伴可能已经发现,这个两个过程其实是做了聚类(clustering)操作。而这个操作的出发点,是注意到了形状”、“荤素”和“颜色”这些有区分力的特征。在更加复杂的问题里,这样有区分力的特征很可能不是那么一目了然。在那些问题里,我们往往需要一类方法可以帮我们找到这类“有区分力的”特征。这也是对比学习的用武之地。换句话说,我们在上面的例子里可以说:“根据形状和荤素可以把这些菜区分开”。在其他的问题中我们也想说:“这些数据点可以通过 _____ 区分开”,而使用对比学习的目的是正是帮我们把句子里的空白给填上。
谚语说:物以类聚。训练CL模型的过程,正是实现让相似的数据相互吸引靠近,不相似的数据相互排斥远离的过程。最终得到一个有聚类功能的模型。需要注意的是,这里的模型和聚类(clustering)模型并不相同。因为CL模型,至少对于基于简单损失函数(loss function)的CL模型,不会自动生成一个个簇群(clusters)。CL模型仿佛是在推箱子一般,把相似的箱子们推得靠近,但不会给推过的箱子们打上诸如1,2,3,4的标记。不过显而易见,对用CL模型处理后的数据进行clustering是再自然不过的操作了~ 事实上,当训练数据里包含了标记时,一个常用的评价CL模型的方法正是把CL模型的输出进行clustering,然后与数据标记比较。以此来评估训练后的CL模型是否能够正确地将“物以类聚”。文末的代码实例里的最后一步正是对训练后的模型做了这样的评估 :)
作为表征学习(Representation Learning)家族的一员,对比学习的应用当然不仅仅局限于聚类,也可以用于分类(classification)、自然语言处理等等不同的领域。它的本质上可以被理解为将输入数据进行“预处理”后,更加方便下游任务的实现。
3. 了解对比学习中常见的两个损失函数和十分重要的操作:数据增强
再来看一个例子,想象有三张照片:猫咪,猎豹,和香蕉。它们的表征(representation)并不是以同等间隔分布的:猫咪和猎豹的表示靠得更近,因为它们的外形更加接近。有趣的彩蛋:据称香蕉和人类的基因相似度超过60%(知乎帖)。要进行对比学习,我们需要解决两个问题:(1)如何描述数据之间的相似度?(2)被认定为不相似的一堆数据,应该将他们之间推开多远?被认定为相似的一对数据又应该被拉得多近?
第一个问题很好解决,一个简单的办法是利用两个向量之间的距离(cosine distance)。第二个问题是关于模型训练过程如何进行,因此自然地,取决于用以训练的损失函数如何定义。在有监督学习里使用的Contrastive loss直截了当地缩短相似数据的距离,同时增加不同数据间距至一个最小值 :
上面的第二个问题其实假设了我们已经知道哪些数据之间是相似或者不相似的,即:已知数据标记(也就是公式里的 )。不过CL也可以被用于无监督学习。那么当我们不知道每个数据的标记,CL又是如何工作的呢?有句老话叫:“没有困难创造困难也要上”。在这里,我们则是“既然没有现成的相似数据,那么我们就创造一些相似的!” 对于每个原始数据点 ,如果我们都创造一个相似数据(正数据 )和不相似数据(反数据 ),则可以定义如下损失函数,名为Triplet loss:
如何产生这些正数据呢?我们可以利用数据增强(data augmentation):比如把图片换个底色、旋转、切割、掩盖。在AI4S的范式里,同一个家族的蛋白质、SMILES码相似的小分子可以作为正数据。反数据则可以由数据集里的其他数据来充当。当然,有时候正和反的定义是主观的,猫咪和狗狗可以被认为是相似的数据(哺乳类宠物),也可以被认为是相反的数据(猫咪一般不拆家)。
训练一个CL模型的过程,就是不断地更新公式里的函数使得损失函数不断降低,最终收敛到的会将输入数据映射到另一个空间(embedding space)。理想的情况下,在这个新空间内,数据之间的相似度变得更加一目了然:相似的数据聚在一起,不同的数据彼此远离,即“物以类聚”。也正因此,在新空间内进行下游任务,比如聚类clustering,将变得无比轻松。从某个角度看,CL有点像给输入数据做了一个“精华提取”的预处理。
“空间变换”可以理解成坐标系变换,比如从方方正正的笛卡尔坐标系变换成另一个九曲十八弯的坐标系。而新空间里的每个维度(每个坐标轴)也正是对比学习算法所学习到的“有区分力”的特征 :)
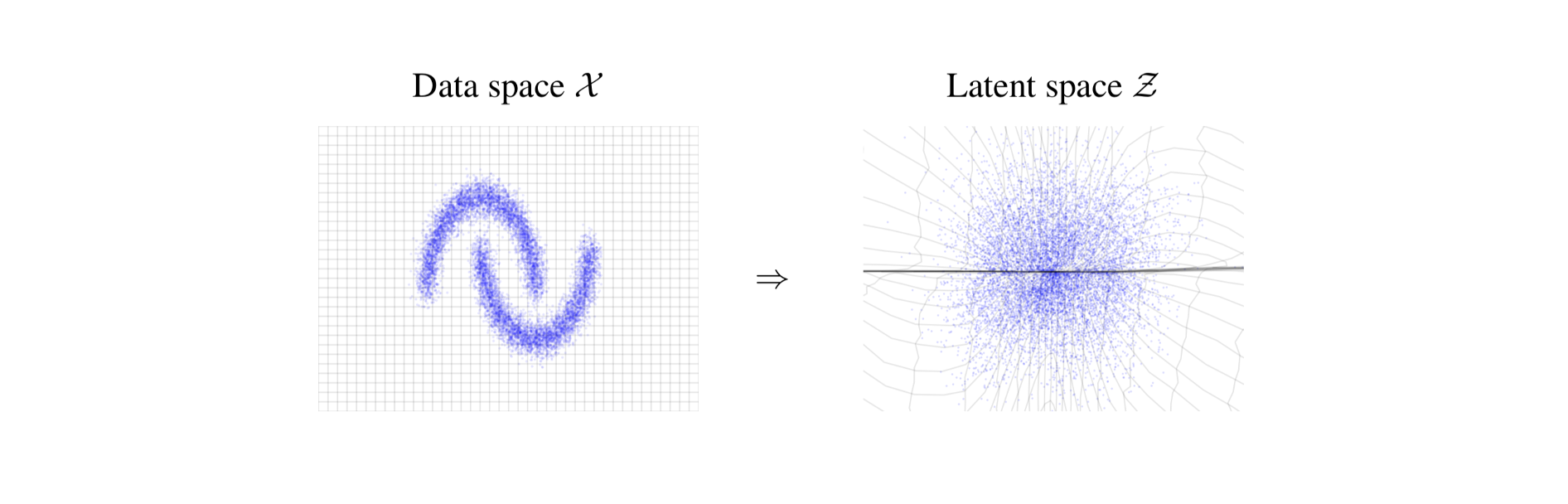
往远处想,如果可以将生物或化学分子的初始表征,比如三维点阵,结合化学和物理信息通过CL处理,获得更便于下游任务的表征,那么下游任务会被更好地解决。这些信息可以是溶解度等物理化学性质、分子内对称性、或者是针对某个问题的具体性质。接下来笔者也会通过一个可以跑的实例来进一步解密对比学习,例子中的输入数据正是一个个三维点阵 :)
4. 结语:
第一次学习对比学习的时候,有种“新瓶装旧酒”的感觉,特别是因为“对比学习”有个听着十分酷的名字,却似乎是个十分简单的想法,和无监督学习算法聚类clustering也有千丝万缕的联系。因而,笔者个人觉得在学习对比学习的过程中,可以注重这个算法在模型优化的部分做了哪些有趣的尝试,特别是产生正反数据的数据增强。在细读的时候可以思考其中有哪些成分可以被运用到解决我们关心的问题里。
更多的细节请见文末参考内容,以及Bohrium广场里其他关于对比学习的notebook ;)
5. 使用PyTorch对三维点阵进行对比学习
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 10.2/10.2 MB 38.7 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 4.8/4.8 MB 45.5 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3.3/3.3 MB 46.9 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 884.9/884.9 kB 21.3 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 661.6/661.6 kB 11.8 MB/s eta 0:00:00 Installing build dependencies ... done Getting requirements to build wheel ... done Preparing metadata (pyproject.toml) ... done Building wheel for torch-geometric (pyproject.toml) ... done
数据集
- 点阵 = 一群未连接的端点 --> 交给Pytorch Geometric来处理
- 数据集来源:ShapeNet Dataset
- 我们只选500个数据点做演示。若载入完整数据集需要比较大的内存
- 下载和解压数据集大约要花费七八分钟,如果能把数据提前下载保存在自己的服务器上就会更快了。
Downloading https://shapenet.cs.stanford.edu/media/shapenetcore_partanno_segmentation_benchmark_v0_normal.zip Extracting ./shapenetcore_partanno_segmentation_benchmark_v0_normal.zip Processing... Done!
Number of Samples: 500 Sample dimension: Data(x=[1652, 3], y=[1652], pos=[1652, 3], category=[1])
| dataset属性名 | 描述 |
|---|---|
| pos | 点阵点的三维坐标 |
| y | 数据分类标记(label) |
- 我们仅仅使用三维坐标来作为训练集。
- 暂时忽略数据的分类标记(y),这些标记会在最后评估经过训练后的模型的时候会用到
让我们看看训练用的点阵数据长什么样子
['Table', 'Lamp', 'Guitar', 'Motorbike']
{'Table': 353, 'Lamp': 95, 'Guitar': 45, 'Motorbike': 7}(笔者按:plotly.express的三维散点图未能顺利显示)
Number of data points: 2848
每个数据点都应该是 ["Table", "Lamp", "Guitar", "Motorbike"] 这四种东西中的一类。如果看着不像,可以试着旋转换换角度。如果依然不怎么像,可以重新选另一个数据点看看。有些数据点有点奇形怪状,确实比较难辨别 :)
利用Pytorch Geometric里提供的数据增强功能
我们来比较一些数据在增强前后的差别:
DataBatch(x=[82639, 3], y=[82639], pos=[82639, 3], category=[32], batch=[82639], ptr=[33])
Number of data points: 1960
Number of data points: 1960
注意到增强的数据与原数据相比有一点点不同。在对比学习中,这些增强的数据将被作为此原始数据的”正数据“。
模型初始化
模型训练
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 113.9/113.9 kB 4.6 MB/s eta 0:00:00
100%|██████████| 20/20 [06:36<00:00, 19.85s/it] Epoch 001, Loss: 1.9440 100%|██████████| 20/20 [06:37<00:00, 19.89s/it]Epoch 002, Loss: 1.4215
这里我们为了节约时间,仅仅训练2个epoch,有兴趣的朋友可以设置更多的训练时间,或者将模型变大,比如MLP的超参数。
评估经过训练后的模型
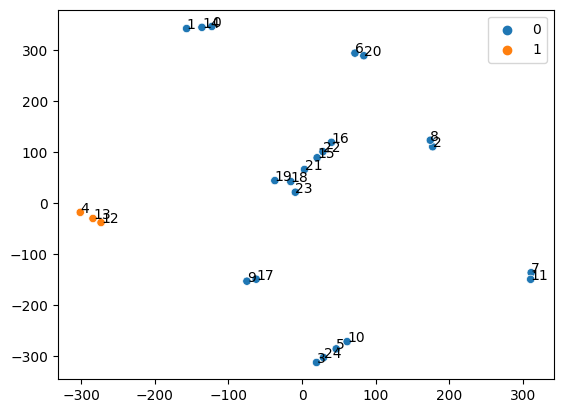
图例里显示此batch里的数据属于哪个类别 ["Table", "Lamp", "Guitar", "Motorbike"]。可以想象,因为batch比较小,有些batch里的数据点没有涉及到全部四个类别。
对于在此batch里的每个数据点,我们可以找出与其最相似的数据点
Most similar data point in the embedding space for 8 is 2
Number of data points: 2816
Number of data points: 2721
- 可以看到,在这个新空间(embedding space)里,8号数据和离它靠得最近的数据(2号)属于同一个类型。
- 当然,如果显示出来的”最相似的数据点”看着并不相似,可以尝试多训练一些epoch,看看结果是不是变好了 :)
6. 更多阅读
- Contrastive loss: https://ieeexplore.ieee.org/document/1467314
- Triplet loss: https://arxiv.org/abs/1503.03832
- Colab notebook来源:https://deepfindr.github.io/
- Lilian Wen博客: very technical and comprehensive: https://lilianweng.github.io/posts/2021-05-31-contrastive/
- 空间变换示意图:https://arxiv.org/abs/1605.08803
- 关于对比学习的损失函数的一篇不错的综述文: https://arxiv.org/abs/2010.05113

octoescaper
octoescaper