


©️ Copyright 2023 @ Authors
作者:浙江大学&西湖大学M3 Lab 赵益峰 📨
最后更新日期:2023-09-28
AI4Science 第三届Hackathon挑战 硬核软件开发赛道
共享协议:本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
📖 上手指南
本文档可在 Bohrium Notebook 上直接运行。你可以点击界面上方按钮
开始连接,选择 bohrium-notebook:2023-04-07 镜像及 c2_m4_cpu 节点配置,稍等片刻即可运行。
一、介绍
临近表介绍
在计算科学和工程领域,临近表(Neighbor List, NBL)是一种重要的数据结构和算法,用于解决各种与空间关联和邻近性有关的问题。 临近表的核心概念涉及到一个目标对象的集合(例如,在分子模拟中,这可能是一组分子的坐标集合),以及从这些对象中抽象而来的邻居关系对应关系。
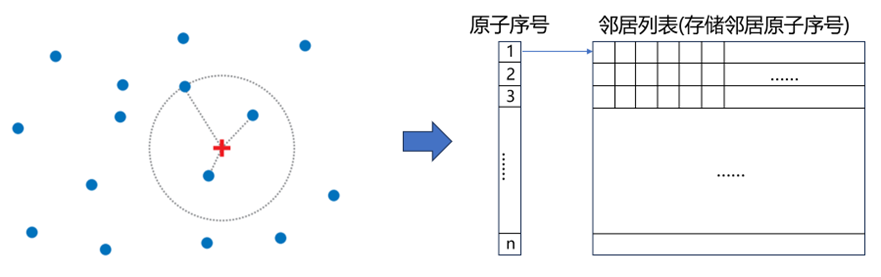
图1 示例点集及临近表提供的对应关系
直观上,临近表可以通过循环遍历目标对象集合来实现,以检查每个对象与其他对象之间的空间关系。然而,随着目标对象数量的增加,这种简单的循环遍历会导致时间复杂度指数爆炸,从而使计算变得非常耗时和低效。因此,为了提高效率,临近表的实现通常会采用更复杂的数据结构和算法。
从应用角度而言,临近表在分子模拟、流体动力学、颗粒模拟、计算机图形学等领域中扮演着至关重要的角色,建立一个跨平台的高效通用架构以为不同领域的研究人员提供统一的工具,促进知识交流和跨领域合作,同时也降低了开发和维护多个专门架构的成本,为科学和工程的创新提供便利。
主要应用场景和解决方案
在临近表的主要应用场景中,我们面临着不同类型的空间。首先是稠密空间,它涉及到在特定区域内,对象或实体之间的距离较小,相对于空间的总体范围,对象数量相对较多,它们密集地堆积在一起,形成连续的分布。其次是稀疏空间,指的是在特定区域内,对象或实体之间的距离较大,相对于空间的总体范围,对象数量相对较少。此外,还存在一类具有不同大小颗粒的空间,通过一些技术,如stencil模板、动态调整等,可以将其归类为前两种空间类型之一。

图2 主要应用场景
二、 算法细节
基于网格实现的临近表 - Grid-based NBL
在介绍Grid-based NBL之前,让我们设想一下最直觉的NBL实现: 考虑一个二维平面上的粒子系统,其中有许多粒子散布在空间中,构建邻居关系,只需要遍历邻居粒子,此时也就是所有粒子,然后检验特征距离,判断是否满足邻居关系的条件,例如欧式距离等。显然,该直觉的NBL实现具有O(n^2)时间复杂度,随着粒子数量的增加,计算成本将急剧增加。
在此基础上,理解Grid-based NBL其实简单了。它的核心思想就是将空间划分为网格单元,并将每个粒子被放置在对应的网格单元中,然后在遍历邻居粒子时,我们只需遍历粒子所在网格单元的邻居单元中的粒子即可,之后检验特征距离的过程是相同的。这样可以大大减少所需遍历的邻居粒子,实现效率的提升。

图3 通过对空间的划分,实现计算效率的显著提升
具体步骤如下图所示,包含三个主要步骤:划分网格,构建颗粒-网格关系,基于网格的相邻关系的颗粒临近表构建。

图4 Grid-based NBL的构建方法
基于八叉树实现的临近表 - Octree NBL
在上述的Grid-based NBL中,通过Grid空间划分可以显著减少处理大规模粒子系统时计算成本,但它仍然存在一些限制,尤其在处理稀疏空间的情况下。在稀疏空间中,粒子的分布可能不均匀,均匀的Grid空间划分,会导致某些网格单元中有很少或没有粒子,而其他网格单元可能非常拥挤,这会导致了计算效率的浪费,特别是对于高维度或大规模的粒子系统,Grid-based NBL需要大量的内存来存储网格单元数据结构,进而影响性能。

图5 两种空间划分的示意图
为了克服Grid-based NBL的限制,Octree NBL应运而生。它与Grid NBL的主要区别在于空间划分的形式以及邻居粒子的遍历方法。Octree NBL的空间划分不仅仅与颗粒的位置有关,还与颗粒的数量密切相关。在具体的实现中,我们以四个颗粒为基准,构建多个耦合体,递归地形成一个树状结构。同时,这个树结构的构建会根据颗粒的位置和聚集密度动态地进行调整。这种划分策略会根据颗粒的分布情况,在颗粒数量较密集的区域增加划分的网格密度,而在稀疏的区域进行相应的调整。此外,Octree NBL的邻居粒子遍历也充分考虑了树结构的特点。通过适当的减枝策略,Octree NBL可以忽略掉一些不想关子树对应的空间,更快速地定位具有相近空间位置的颗粒,从而提高搜索效率。
Octree NBL的具体构建过程如下图所示:

图6 Octree NBL的构建方法
基于Hash实现的临近表 - Hash NBL
通过以上两种临近表的介绍,我们可以注意到它们的核心思想都是通过空间划分或树结构的构建等映射方法,来建立目标对象之间的相邻关系。随后,利用这种相邻关系,减少所需遍历的邻居颗粒,从而实现了邻近表的高效构建。基于该思路,我们尝试构建了一个函数,来直接计算对象的相邻关系,并以此来构建临近表。以三维问题为例,这个函数具有以下三个特征:1. 维度变换:能够把三维空间点映射为能够容易操作的一维线性数据。2. 保持相邻关系:映射后的一维数据保有与三维空间相同的邻居关系。3. 计算廉价。
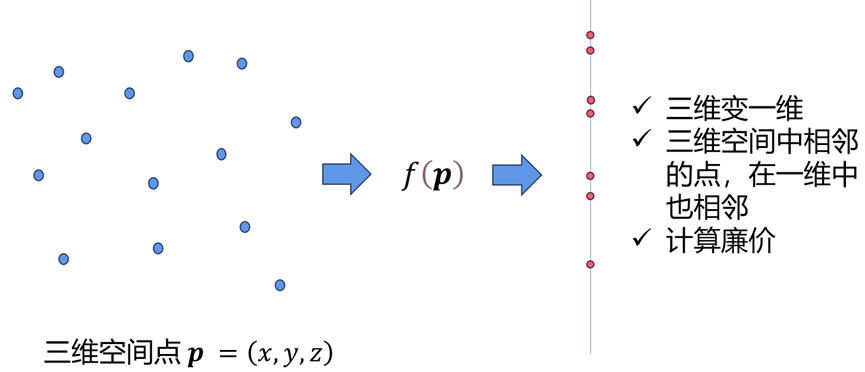
图7 Hash NBL的设想
由于在Hash NBL中,邻居关系可以通过Hash函数直接计算得到,无需依赖空间划分,因此从理论上来说,它具备最高的计算效率。
三、 基于Python的实现示例
为方便大家更好地理解上述三种临近表,此处提供了基于Python的实现。
Grid-based NBL
OCtree NBL
Hash NBL
四、测试
通过随机生成随机数,我们对上述python示例实现进行了测试
五、结论
可以发现这三种NBL在不同的系统中表现各异,Grid NBL在稠密系统中表现良好,但由于在稀疏系统中会划分较多的空网格,造成了性能下降;Octree NBL的表现恰与此相反;而Hash NBL则在两类系统中都保持了较好且稳定的表现,基本实现了设计目的。




