
 AllanKay
AllanKay
Abstract
电化学阻抗谱(EIS)作为一种测试方法和表征手段,包含着丰富的电池动力学和老化信息,可被用作监测电池状态(如拟合等效电路模型和预测剩余寿命)。然而,其收集成本高、时间久和车载收集困难限制了广泛了应用。目前,已有一些工作通过脉冲电流、充放电信号等预测EIS。同时,由于EIS测试过程中扫频的特点,使得使用部分频率下的阻抗,预测全频率阻抗成为了一个自然的思路。在这种情况下,测试的时间将大大缩短。本文基于这种思路,使用在几个特征频率下测量的阻抗作为输入。 根据弛豫时间分布中接触极化和固体电解质相间生长过程的特征峰和谷对应的时间常数来确定特征频率。使用两种模型(基于卷积神经网络和注意力模型)对公开数据集[1]中同一温度下的7个电池进行了实验,结果显示,两种模型在使用4个特征频率数据的情况下,预测的平均RMSE均小于10mΩ,其中基于注意力的模型比基于CNN的模型精度提高了40%。
本文分为两个部分,第一个部分为背景介绍和关于EIS的DRT分析,第二个部分为两个模型的代码实现,第一个模型为参考文章中的CNN模型,第二个模型为一个Transformer encoder模型。 完整运行代码只需要几分钟。
关于几个特征频率点下的阻抗预测全EIS谱的文章参考:Journal of Power Sources
Introduction
关于EIS以及使用特征频率下阻抗预测全谱EIS有以下背景需要了解:
电化学阻抗谱(EIS)是一种常用于表征电池的非破坏性方法,它揭示了LiB内部的动态电极动力学过程。基于不同电化学过程表现出的时间常数,可以通过将阻抗谱的变化与固体电解质界面(SEI)生长、电荷转移和锂离子扩散等内部机制联系起来来表征电池性能。辅助研究工具包括等效电路模型(ECM)、弛豫时间分布(DRT)、阻抗机制模型等。 可以区分和量化多时间尺度特征,以更好地了解电池状态。已有工作显示2,借助机器学习方法,在电芯筛选和老化监测这两种情况下,根据阻抗可以可靠地量化关键的物理化学参数。 结果表明,电芯筛选时可以EIS准确估算电池电极的弯曲度、孔隙率和活性物质含量,误差小于2%;在老化监测方面,SEI电阻和电荷转移电阻可以准确估计,误差小于5% 。 上述应用表明EIS提供了对电池更全面的理解。
DRT可以实现频域EIS的解释并区分不同时间常数的电化学过程。与 ECM 的预建模不同,DRT 方法的思想是将阻抗响应表示为无限个差分 RC 分量。如下图所示,EIS的DRT结果可以通过DRTtools基于Tikhonov正则化来计算:
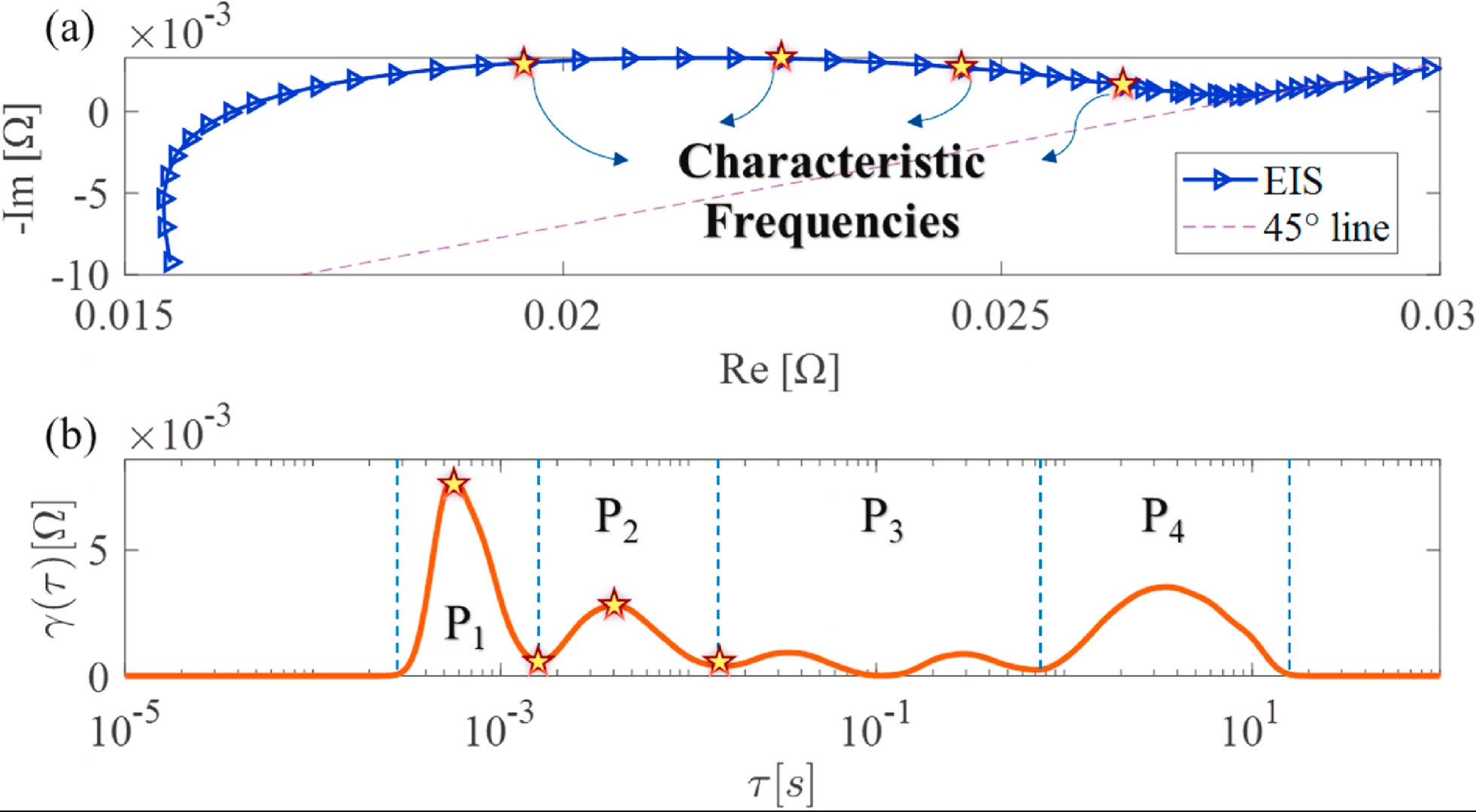
上图来自参考文章
可以注意到,在不同的时间常数下可以清楚地识别出四个动力学过程 P1∼P4。 过程P1表示由于集电器腐蚀而导致的接触极化。 过程P2表明SEI的生长。 同时,P1和P2与电池SOC无关。 过程P3和P4表示电荷转移和扩散,它们都与锂离子浓度即SOC有关。在实际应用中,电池工作条件和状态的变化使得阻抗谱的实时测量变得困难。阻抗谱随电池内部状态的变化而显着变化。 为了保证测量的有效性而不影响电池在充放电过程中的正常工作状态,测量需要在很短的时间内完成。 因此,特征频率由中频和高频区域确定,对应于 DRT 曲线中 P1(接触极化)和 P2(SEI 生长)的波峰和波谷。 得到时间常数τ后,可以计算出相应的频率f。值得注意的是,参考文章中提到:“当电池类型或温度发生变化时,需要重新确定特征频率。 在电池老化过程中,特征频率对应的时间常数没有明显变化,但特征频率处的峰、谷和峰面积有所不同,这使得基于电池老化过程中特征频率的预测方法具有可行性。”
下图是在我们使用的公开数据集中,1号电池在25°C不同循环下SOC=0时EIS的DRT结果:
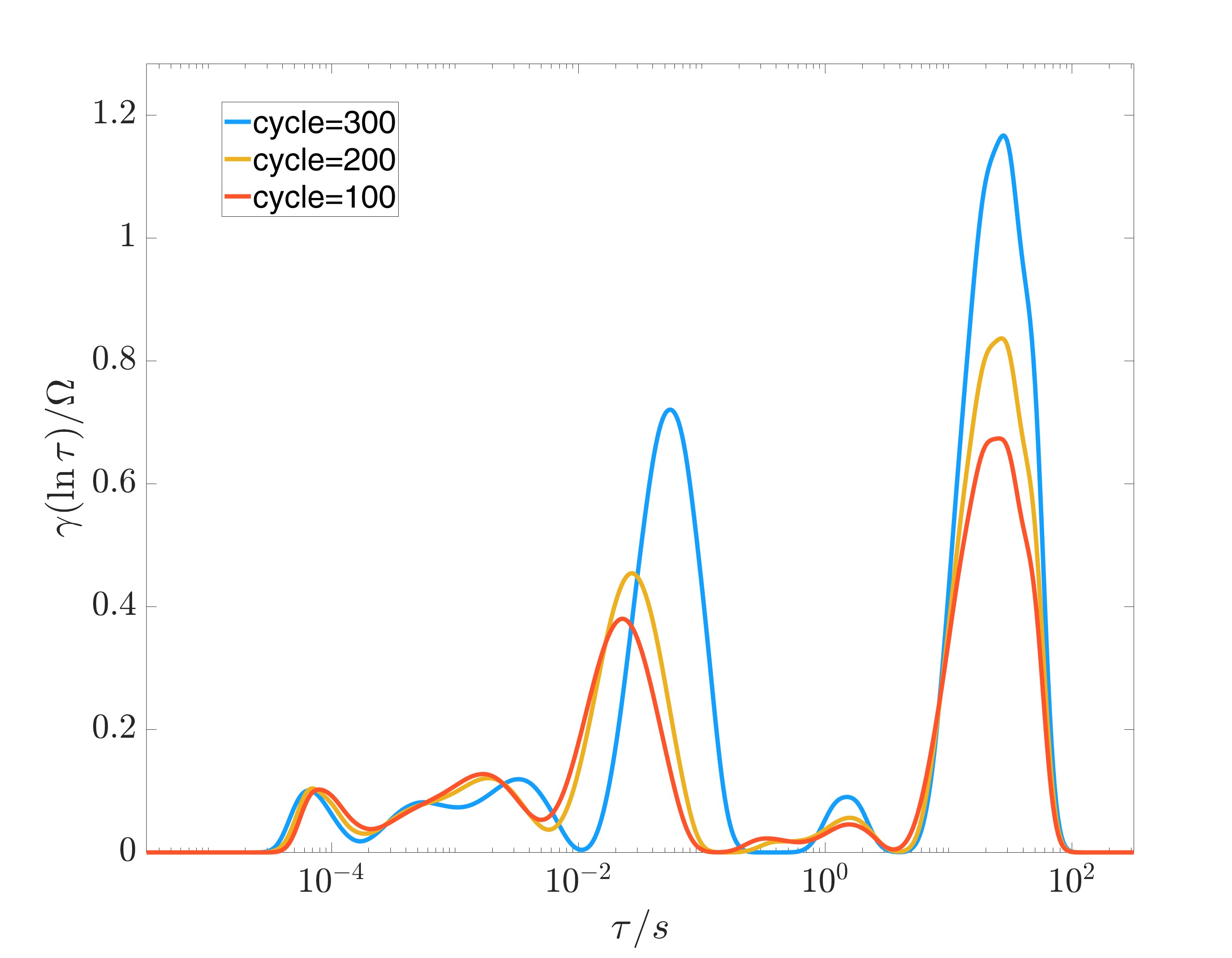 |
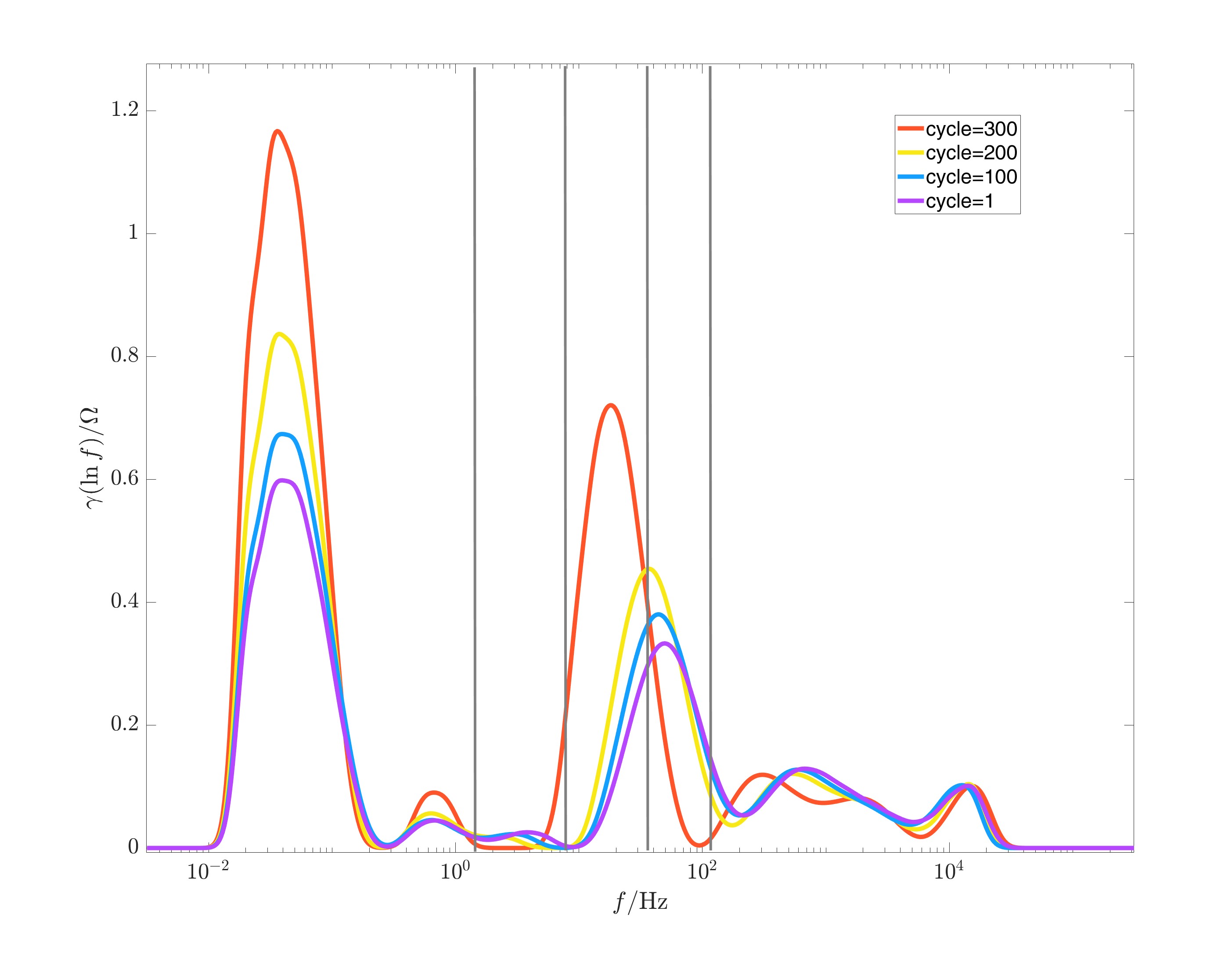 |
其中左图横轴为时间常数,右图横轴为频率。从两张图中我们都可以发现,随着电池的老化,P1和P2阶段对应波峰波谷的特征频率和时间常数是会出现一些偏移的。关于这一点,笔者也与参考文章的作者确认过。因此,虽然在我们后续的建模计算中,使用初始特征频率的预测精度很高,但关于如何处理EIS数据、选择特征,还是一个值得思考和研究的问题。
注:
- 为了与参考文章中的结果比对,本文选择的四个特征频率与参考文章中提取的公开数据集特征频率相同。上右图中的灰线对应着四个特征频率的位置。
- DRTtools: https://github.com/ciuccislab/pyDRTtools
Data Load and Process
这里我们使用公开数据集中,测试温度为25℃下的七颗电池,使用的SOC状态为0%。测试电池为LCO体系纽扣电池,循环次数从几十到三百不等,共1350个循环。
Total samples: 1350
Data Sample Name: 25C01-cyc67 Data Sample Shape: 60
将数据集随机划分为训练集验证集。比例为8/2.
Train samples: 1080 Valid samples: 270
这里列出参考文章中给出的特征频率[115.78, 35.93, 7.76, 1.42] Hz。可以发现,和参考文章中NMC数据集相比,公开数据集选择的频率集中在中频段甚至靠近低频段。
从数据集中取出输入数据,即四个特征频率下的阻抗实虚部。
Shape of Input: torch.Size([4, 2]) Shape of Output: torch.Size([60, 2])
CNN Model
复现参考文章中的CNN模型。注意这里输入给模型的Channels是2,对应是阻抗的实部与虚部,可以看作输入的两个feature。而频率维度为4,对应序列长度4。这种设计还是比较make sense的。
考虑到文章中最后有一步flatten的操作,因此这里把target的数据拉平,和模型输出保持一致。
CNN Model: EISConvNet( (conv1): Conv1d(2, 16, kernel_size=(2,), stride=(1,), padding=(1,)) (pool1): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (conv2): Conv1d(16, 32, kernel_size=(2,), stride=(1,), padding=(1,)) (pool2): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (conv3): Conv1d(32, 16, kernel_size=(2,), stride=(1,), padding=(1,)) (global_pool): AdaptiveMaxPool1d(output_size=1) (fc1): Linear(in_features=16, out_features=120, bias=True) (dropout): Dropout(p=0.1, inplace=False) (fc2): Linear(in_features=120, out_features=120, bias=True) (relu): ReLU() )
Epoch [50/1000], Train Loss: 0.002566, Valid Loss: 0.001118, Valid RMSE: 0.0334, Valid RMSPE: 327.7141 Epoch [100/1000], Train Loss: 0.001779, Valid Loss: 0.000514, Valid RMSE: 0.0226, Valid RMSPE: 303.3098 Epoch [150/1000], Train Loss: 0.001389, Valid Loss: 0.000342, Valid RMSE: 0.0184, Valid RMSPE: 231.8471 Epoch [200/1000], Train Loss: 0.001012, Valid Loss: 0.000220, Valid RMSE: 0.0148, Valid RMSPE: 94.6247 Epoch [250/1000], Train Loss: 0.000777, Valid Loss: 0.000263, Valid RMSE: 0.0162, Valid RMSPE: 175.4135 Epoch [300/1000], Train Loss: 0.000573, Valid Loss: 0.000098, Valid RMSE: 0.0099, Valid RMSPE: 109.1139 Epoch [350/1000], Train Loss: 0.000424, Valid Loss: 0.000238, Valid RMSE: 0.0154, Valid RMSPE: 156.2194 Epoch [400/1000], Train Loss: 0.000296, Valid Loss: 0.000057, Valid RMSE: 0.0076, Valid RMSPE: 262.2552 Epoch [450/1000], Train Loss: 0.000241, Valid Loss: 0.000101, Valid RMSE: 0.0101, Valid RMSPE: 138.3200 Epoch 00491: reducing learning rate of group 0 to 4.0000e-04. Epoch [500/1000], Train Loss: 0.000178, Valid Loss: 0.000044, Valid RMSE: 0.0066, Valid RMSPE: 149.5567 Epoch [550/1000], Train Loss: 0.000170, Valid Loss: 0.000034, Valid RMSE: 0.0058, Valid RMSPE: 158.9250 Epoch [600/1000], Train Loss: 0.000162, Valid Loss: 0.000043, Valid RMSE: 0.0065, Valid RMSPE: 141.0107 Epoch [650/1000], Train Loss: 0.000147, Valid Loss: 0.000038, Valid RMSE: 0.0061, Valid RMSPE: 113.0676 Epoch 00660: reducing learning rate of group 0 to 1.6000e-04. Epoch [700/1000], Train Loss: 0.000149, Valid Loss: 0.000030, Valid RMSE: 0.0055, Valid RMSPE: 105.8248 Epoch 00719: reducing learning rate of group 0 to 6.4000e-05. Epoch [750/1000], Train Loss: 0.000154, Valid Loss: 0.000036, Valid RMSE: 0.0060, Valid RMSPE: 122.7888 Epoch 00754: reducing learning rate of group 0 to 2.5600e-05. Epoch 00785: reducing learning rate of group 0 to 1.0240e-05. Epoch [800/1000], Train Loss: 0.000142, Valid Loss: 0.000028, Valid RMSE: 0.0053, Valid RMSPE: 113.3180 Epoch 00816: reducing learning rate of group 0 to 4.0960e-06. Epoch 00847: reducing learning rate of group 0 to 1.6384e-06. Epoch [850/1000], Train Loss: 0.000141, Valid Loss: 0.000028, Valid RMSE: 0.0053, Valid RMSPE: 114.5932 Epoch 00878: reducing learning rate of group 0 to 6.5536e-07. Epoch [900/1000], Train Loss: 0.000146, Valid Loss: 0.000028, Valid RMSE: 0.0053, Valid RMSPE: 114.6356 Epoch 00909: reducing learning rate of group 0 to 2.6214e-07. Epoch 00940: reducing learning rate of group 0 to 1.0486e-07. Epoch [950/1000], Train Loss: 0.000132, Valid Loss: 0.000028, Valid RMSE: 0.0053, Valid RMSPE: 115.2389 Epoch 00971: reducing learning rate of group 0 to 4.1943e-08. Epoch [1000/1000], Train Loss: 0.000132, Valid Loss: 0.000028, Valid RMSE: 0.0053, Valid RMSPE: 115.0621
笔者尝试了多个随机数种子,CNN模型的结果均在6~7mΩ左右,这个结果略好于参考文章中公开数据集的最优结果。考虑到参考文章是在第一个数据集上预训练后transfer learning到公开数据集,这样的结果也还算合理。值得一提的是RMSPE的值,由于EIS虚部在高频段可能非常接近与0,所以百分比误差在这里会出现爆炸的情况,着也是为什么用百分比误差衡量EIS预测不太合理的地方。

选择几个验证集中的数据绘图展示。可以看到,拟合的精度还是很好的。
<Figure size 1000x1200 with 0 Axes>


0, 25C07-cyc100 - RMSE: 0.0061, RMSPE: 2.51% 1, 25C01-cyc17 - RMSE: 0.0148, RMSPE: 13.71% 2, 25C06-cyc26 - RMSE: 0.0059, RMSPE: 2.81% 3, 25C07-cyc89 - RMSE: 0.0059, RMSPE: 8.55% 4, 25C03-cyc199 - RMSE: 0.0040, RMSPE: 130.09% 5, 25C03-cyc160 - RMSE: 0.0038, RMSPE: 10.90% 6, 25C01-cyc249 - RMSE: 0.0046, RMSPE: 2.89% 7, 25C01-cyc141 - RMSE: 0.0062, RMSPE: 18.11% 8, 25C02-cyc153 - RMSE: 0.0046, RMSPE: 4.52% 9, 25C03-cyc9 - RMSE: 0.0040, RMSPE: 2.06% 10, 25C03-cyc75 - RMSE: 0.0034, RMSPE: 1.09% 11, 25C01-cyc176 - RMSE: 0.0043, RMSPE: 13.92% 12, 25C07-cyc25 - RMSE: 0.0029, RMSPE: 3.48% 13, 25C02-cyc75 - RMSE: 0.0042, RMSPE: 7.93% 14, 25C01-cyc267 - RMSE: 0.0045, RMSPE: 3.71% 15, 25C02-cyc97 - RMSE: 0.0052, RMSPE: 6.19% 16, 25C02-cyc220 - RMSE: 0.0038, RMSPE: 3.69% 17, 25C04-cyc17 - RMSE: 0.0041, RMSPE: 8.22% 18, 25C04-cyc10 - RMSE: 0.0038, RMSPE: 5.42% 19, 25C06-cyc198 - RMSE: 0.0067, RMSPE: 18.91% 20, 25C03-cyc173 - RMSE: 0.0036, RMSPE: 31.04% 21, 25C01-cyc25 - RMSE: 0.0065, RMSPE: 2.05% 22, 25C02-cyc206 - RMSE: 0.0040, RMSPE: 3.03% 23, 25C01-cyc197 - RMSE: 0.0035, RMSPE: 5.91% 24, 25C01-cyc204 - RMSE: 0.0047, RMSPE: 143.97% 25, 25C01-cyc277 - RMSE: 0.0057, RMSPE: 3.24% 26, 25C04-cyc5 - RMSE: 0.0048, RMSPE: 5.97% 27, 25C06-cyc79 - RMSE: 0.0033, RMSPE: 59.19% 28, 25C02-cyc40 - RMSE: 0.0062, RMSPE: 14.31% 29, 25C02-cyc126 - RMSE: 0.0046, RMSPE: 5.45% 30, 25C02-cyc146 - RMSE: 0.0047, RMSPE: 4.05% 31, 25C07-cyc121 - RMSE: 0.0075, RMSPE: 2.48% 32, 25C03-cyc191 - RMSE: 0.0047, RMSPE: 8.89% 33, 25C01-cyc151 - RMSE: 0.0047, RMSPE: 12.86% 34, 25C03-cyc62 - RMSE: 0.0036, RMSPE: 1.82% 35, 25C03-cyc223 - RMSE: 0.0047, RMSPE: 8.13% 36, 25C02-cyc222 - RMSE: 0.0049, RMSPE: 4.15% 37, 25C03-cyc90 - RMSE: 0.0039, RMSPE: 6.06% 38, 25C04-cyc1 - RMSE: 0.0083, RMSPE: 13.86% 39, 25C01-cyc69 - RMSE: 0.0049, RMSPE: 5.50% 40, 25C02-cyc151 - RMSE: 0.0042, RMSPE: 3.70% 41, 25C02-cyc184 - RMSE: 0.0043, RMSPE: 4.26% 42, 25C08-cyc11 - RMSE: 0.0052, RMSPE: 2.30% 43, 25C03-cyc23 - RMSE: 0.0038, RMSPE: 1.47% 44, 25C02-cyc136 - RMSE: 0.0047, RMSPE: 5.38% 45, 25C01-cyc51 - RMSE: 0.0050, RMSPE: 2.58% 46, 25C03-cyc22 - RMSE: 0.0035, RMSPE: 1.34% 47, 25C01-cyc263 - RMSE: 0.0047, RMSPE: 4.43% 48, 25C06-cyc19 - RMSE: 0.0061, RMSPE: 2.53% 49, 25C01-cyc293 - RMSE: 0.0043, RMSPE: 1.59% 50, 25C01-cyc145 - RMSE: 0.0058, RMSPE: 14.14% 51, 25C01-cyc118 - RMSE: 0.0047, RMSPE: 15.51% 52, 25C06-cyc45 - RMSE: 0.0034, RMSPE: 6.63% 53, 25C08-cyc35 - RMSE: 0.0073, RMSPE: 4.05% 54, 25C03-cyc228 - RMSE: 0.0076, RMSPE: 13.25% 55, 25C02-cyc190 - RMSE: 0.0046, RMSPE: 3.65% 56, 25C06-cyc97 - RMSE: 0.0029, RMSPE: 145.00% 57, 25C01-cyc65 - RMSE: 0.0053, RMSPE: 5.81% 58, 25C07-cyc31 - RMSE: 0.0025, RMSPE: 3.01% 59, 25C03-cyc78 - RMSE: 0.0037, RMSPE: 1.58% 60, 25C03-cyc118 - RMSE: 0.0038, RMSPE: 1.72% 61, 25C01-cyc137 - RMSE: 0.0052, RMSPE: 18.57% 62, 25C07-cyc58 - RMSE: 0.0037, RMSPE: 4.90% 63, 25C07-cyc1 - RMSE: 0.0095, RMSPE: 5.20% 64, 25C06-cyc65 - RMSE: 0.0031, RMSPE: 18.05% 65, 25C01-cyc77 - RMSE: 0.0033, RMSPE: 6.54% 66, 25C01-cyc296 - RMSE: 0.0055, RMSPE: 2.48% 67, 25C01-cyc72 - RMSE: 0.0043, RMSPE: 4.97% 68, 25C07-cyc98 - RMSE: 0.0060, RMSPE: 3.29% 69, 25C07-cyc117 - RMSE: 0.0066, RMSPE: 3.29% 70, 25C03-cyc103 - RMSE: 0.0043, RMSPE: 3.11% 71, 25C03-cyc101 - RMSE: 0.0040, RMSPE: 4.62% 72, 25C07-cyc45 - RMSE: 0.0023, RMSPE: 3.72% 73, 25C02-cyc119 - RMSE: 0.0044, RMSPE: 5.36% 74, 25C02-cyc48 - RMSE: 0.0056, RMSPE: 12.51% 75, 25C06-cyc31 - RMSE: 0.0046, RMSPE: 5.39% 76, 25C01-cyc199 - RMSE: 0.0038, RMSPE: 15.32% 77, 25C01-cyc89 - RMSE: 0.0035, RMSPE: 7.73% 78, 25C06-cyc86 - RMSE: 0.0034, RMSPE: 20.51% 79, 25C06-cyc122 - RMSE: 0.0027, RMSPE: 57.11% 80, 25C02-cyc141 - RMSE: 0.0038, RMSPE: 4.17% 81, 25C04-cyc61 - RMSE: 0.0044, RMSPE: 49.55% 82, 25C04-cyc65 - RMSE: 0.0051, RMSPE: 667.71% 83, 25C02-cyc232 - RMSE: 0.0039, RMSPE: 4.21% 84, 25C08-cyc14 - RMSE: 0.0053, RMSPE: 3.47% 85, 25C06-cyc124 - RMSE: 0.0025, RMSPE: 6.43% 86, 25C04-cyc82 - RMSE: 0.0058, RMSPE: 23.82% 87, 25C01-cyc282 - RMSE: 0.0046, RMSPE: 2.23% 88, 25C08-cyc17 - RMSE: 0.0059, RMSPE: 3.77% 89, 25C04-cyc62 - RMSE: 0.0044, RMSPE: 16.75% 90, 25C03-cyc119 - RMSE: 0.0044, RMSPE: 1.51% 91, 25C01-cyc217 - RMSE: 0.0044, RMSPE: 3.79% 92, 25C01-cyc254 - RMSE: 0.0053, RMSPE: 5.89% 93, 25C03-cyc11 - RMSE: 0.0038, RMSPE: 1.48% 94, 25C06-cyc155 - RMSE: 0.0043, RMSPE: 111.68% 95, 25C01-cyc227 - RMSE: 0.0034, RMSPE: 7.31% 96, 25C08-cyc19 - RMSE: 0.0052, RMSPE: 3.34% 97, 25C06-cyc147 - RMSE: 0.0039, RMSPE: 957.51% 98, 25C03-cyc121 - RMSE: 0.0040, RMSPE: 4.37% 99, 25C04-cyc45 - RMSE: 0.0038, RMSPE: 35.74% 100, 25C04-cyc26 - RMSE: 0.0044, RMSPE: 13.36% 101, 25C08-cyc13 - RMSE: 0.0056, RMSPE: 2.99% 102, 25C06-cyc93 - RMSE: 0.0026, RMSPE: 60.00% 103, 25C08-cyc66 - RMSE: 0.0115, RMSPE: 5.97% 104, 25C01-cyc19 - RMSE: 0.0096, RMSPE: 3.48% 105, 25C06-cyc70 - RMSE: 0.0037, RMSPE: 20.33% 106, 25C01-cyc192 - RMSE: 0.0035, RMSPE: 6.88% 107, 25C04-cyc38 - RMSE: 0.0049, RMSPE: 21.84% 108, 25C07-cyc94 - RMSE: 0.0067, RMSPE: 7.26% 109, 25C02-cyc242 - RMSE: 0.0039, RMSPE: 3.96% 110, 25C01-cyc10 - RMSE: 0.0127, RMSPE: 15.50% 111, 25C02-cyc55 - RMSE: 0.0048, RMSPE: 11.22% 112, 25C03-cyc67 - RMSE: 0.0037, RMSPE: 1.29% 113, 25C03-cyc53 - RMSE: 0.0035, RMSPE: 1.42% 114, 25C02-cyc182 - RMSE: 0.0042, RMSPE: 5.59% 115, 25C02-cyc113 - RMSE: 0.0047, RMSPE: 6.88% 116, 25C03-cyc66 - RMSE: 0.0038, RMSPE: 1.24% 117, 25C07-cyc13 - RMSE: 0.0033, RMSPE: 3.63% 118, 25C02-cyc66 - RMSE: 0.0051, RMSPE: 9.19% 119, 25C01-cyc46 - RMSE: 0.0046, RMSPE: 1.77% 120, 25C02-cyc244 - RMSE: 0.0040, RMSPE: 3.31% 121, 25C01-cyc344 - RMSE: 0.0071, RMSPE: 3.32% 122, 25C02-cyc164 - RMSE: 0.0042, RMSPE: 5.56% 123, 25C02-cyc192 - RMSE: 0.0045, RMSPE: 4.06% 124, 25C06-cyc62 - RMSE: 0.0037, RMSPE: 13.18% 125, 25C01-cyc280 - RMSE: 0.0057, RMSPE: 13.87% 126, 25C06-cyc185 - RMSE: 0.0040, RMSPE: 64.41% 127, 25C06-cyc13 - RMSE: 0.0069, RMSPE: 3.61% 128, 25C06-cyc144 - RMSE: 0.0039, RMSPE: 36.15% 129, 25C03-cyc55 - RMSE: 0.0033, RMSPE: 1.76% 130, 25C06-cyc47 - RMSE: 0.0034, RMSPE: 8.33% 131, 25C01-cyc68 - RMSE: 0.0057, RMSPE: 5.22% 132, 25C01-cyc15 - RMSE: 0.0144, RMSPE: 13.39% 133, 25C01-cyc129 - RMSE: 0.0054, RMSPE: 19.80% 134, 25C03-cyc48 - RMSE: 0.0036, RMSPE: 1.23% 135, 25C06-cyc75 - RMSE: 0.0039, RMSPE: 21.59% 136, 25C01-cyc309 - RMSE: 0.0052, RMSPE: 1.45% 137, 25C04-cyc27 - RMSE: 0.0045, RMSPE: 12.22% 138, 25C01-cyc319 - RMSE: 0.0046, RMSPE: 2.98% 139, 25C02-cyc5 - RMSE: 0.0067, RMSPE: 186.86% 140, 25C08-cyc39 - RMSE: 0.0077, RMSPE: 5.92% 141, 25C04-cyc72 - RMSE: 0.0054, RMSPE: 39.18% 142, 25C04-cyc44 - RMSE: 0.0046, RMSPE: 11.52% 143, 25C06-cyc10 - RMSE: 0.0077, RMSPE: 3.34% 144, 25C02-cyc106 - RMSE: 0.0050, RMSPE: 6.90% 145, 25C02-cyc234 - RMSE: 0.0042, RMSPE: 3.64% 146, 25C02-cyc147 - RMSE: 0.0042, RMSPE: 4.00% 147, 25C01-cyc147 - RMSE: 0.0057, RMSPE: 19.90% 148, 25C01-cyc243 - RMSE: 0.0042, RMSPE: 2.49% 149, 25C07-cyc66 - RMSE: 0.0032, RMSPE: 3.55% 150, 25C06-cyc91 - RMSE: 0.0025, RMSPE: 53.47% 151, 25C01-cyc125 - RMSE: 0.0041, RMSPE: 18.33% 152, 25C07-cyc5 - RMSE: 0.0041, RMSPE: 4.35% 153, 25C01-cyc112 - RMSE: 0.0043, RMSPE: 12.88% 154, 25C03-cyc185 - RMSE: 0.0040, RMSPE: 12.65% 155, 25C01-cyc166 - RMSE: 0.0057, RMSPE: 24.52% 156, 25C03-cyc102 - RMSE: 0.0036, RMSPE: 4.68% 157, 25C01-cyc142 - RMSE: 0.0055, RMSPE: 22.37% 158, 25C03-cyc203 - RMSE: 0.0045, RMSPE: 64.15% 159, 25C06-cyc101 - RMSE: 0.0031, RMSPE: 2652.01% 160, 25C01-cyc306 - RMSE: 0.0057, RMSPE: 2.84% 161, 25C02-cyc105 - RMSE: 0.0049, RMSPE: 6.16% 162, 25C03-cyc98 - RMSE: 0.0048, RMSPE: 2.81% 163, 25C06-cyc48 - RMSE: 0.0033, RMSPE: 8.57% 164, 25C03-cyc209 - RMSE: 0.0042, RMSPE: 5.19% 165, 25C07-cyc7 - RMSE: 0.0037, RMSPE: 2.96% 166, 25C01-cyc114 - RMSE: 0.0043, RMSPE: 12.60% 167, 25C02-cyc157 - RMSE: 0.0048, RMSPE: 4.98% 168, 25C07-cyc11 - RMSE: 0.0034, RMSPE: 3.38% 169, 25C06-cyc33 - RMSE: 0.0040, RMSPE: 4.21% 170, 25C01-cyc231 - RMSE: 0.0042, RMSPE: 1.68% 171, 25C01-cyc122 - RMSE: 0.0057, RMSPE: 15.58% 172, 25C06-cyc56 - RMSE: 0.0038, RMSPE: 11.03% 173, 25C06-cyc6 - RMSE: 0.0075, RMSPE: 2.67% 174, 25C02-cyc58 - RMSE: 0.0046, RMSPE: 10.65% 175, 25C01-cyc226 - RMSE: 0.0045, RMSPE: 2.42% 176, 25C01-cyc107 - RMSE: 0.0041, RMSPE: 12.19% 177, 25C03-cyc155 - RMSE: 0.0031, RMSPE: 6.67% 178, 25C02-cyc236 - RMSE: 0.0044, RMSPE: 3.78% 179, 25C07-cyc68 - RMSE: 0.0029, RMSPE: 5.64% 180, 25C01-cyc255 - RMSE: 0.0048, RMSPE: 2.85% 181, 25C06-cyc114 - RMSE: 0.0028, RMSPE: 628.74% 182, 25C07-cyc62 - RMSE: 0.0027, RMSPE: 3.43% 183, 25C02-cyc69 - RMSE: 0.0044, RMSPE: 9.04% 184, 25C07-cyc91 - RMSE: 0.0050, RMSPE: 7.09% 185, 25C01-cyc203 - RMSE: 0.0057, RMSPE: 16.58% 186, 25C08-cyc29 - RMSE: 0.0078, RMSPE: 5.98% 187, 25C04-cyc49 - RMSE: 0.0048, RMSPE: 38.95% 188, 25C01-cyc2 - RMSE: 0.0105, RMSPE: 13.01% 189, 25C07-cyc105 - RMSE: 0.0080, RMSPE: 1.91% 190, 25C03-cyc18 - RMSE: 0.0037, RMSPE: 1.80% 191, 25C03-cyc17 - RMSE: 0.0042, RMSPE: 1.77% 192, 25C01-cyc336 - RMSE: 0.0061, RMSPE: 5.95% 193, 25C02-cyc43 - RMSE: 0.0056, RMSPE: 13.68% 194, 25C03-cyc206 - RMSE: 0.0048, RMSPE: 3.39% 195, 25C01-cyc74 - RMSE: 0.0041, RMSPE: 6.52% 196, 25C08-cyc80 - RMSE: 0.0084, RMSPE: 2.62% 197, 25C01-cyc304 - RMSE: 0.0056, RMSPE: 5.05% 198, 25C02-cyc72 - RMSE: 0.0045, RMSPE: 8.19% 199, 25C01-cyc138 - RMSE: 0.0047, RMSPE: 18.93% 200, 25C03-cyc45 - RMSE: 0.0037, RMSPE: 2.57% 201, 25C02-cyc123 - RMSE: 0.0043, RMSPE: 5.84% 202, 25C01-cyc338 - RMSE: 0.0060, RMSPE: 3.25% 203, 25C03-cyc148 - RMSE: 0.0039, RMSPE: 6.00% 204, 25C02-cyc27 - RMSE: 0.0062, RMSPE: 19.04% 205, 25C03-cyc163 - RMSE: 0.0036, RMSPE: 4.83% 206, 25C01-cyc152 - RMSE: 0.0060, RMSPE: 16.45% 207, 25C03-cyc104 - RMSE: 0.0039, RMSPE: 5.06% 208, 25C04-cyc20 - RMSE: 0.0037, RMSPE: 8.74% 209, 25C08-cyc25 - RMSE: 0.0073, RMSPE: 5.19% 210, 25C08-cyc51 - RMSE: 0.0089, RMSPE: 5.31% 211, 25C07-cyc96 - RMSE: 0.0069, RMSPE: 4.70% 212, 25C06-cyc16 - RMSE: 0.0062, RMSPE: 2.79% 213, 25C02-cyc129 - RMSE: 0.0036, RMSPE: 5.49% 214, 25C01-cyc99 - RMSE: 0.0032, RMSPE: 9.94% 215, 25C08-cyc63 - RMSE: 0.0100, RMSPE: 5.87% 216, 25C01-cyc135 - RMSE: 0.0059, RMSPE: 20.98% 217, 25C07-cyc50 - RMSE: 0.0022, RMSPE: 2.04% 218, 25C07-cyc41 - RMSE: 0.0034, RMSPE: 1.92% 219, 25C04-cyc66 - RMSE: 0.0045, RMSPE: 12.69% 220, 25C07-cyc64 - RMSE: 0.0033, RMSPE: 3.96% 221, 25C03-cyc47 - RMSE: 0.0034, RMSPE: 2.52% 222, 25C06-cyc43 - RMSE: 0.0040, RMSPE: 2.82% 223, 25C02-cyc9 - RMSE: 0.0065, RMSPE: 47.66% 224, 25C02-cyc25 - RMSE: 0.0056, RMSPE: 19.69% 225, 25C04-cyc47 - RMSE: 0.0040, RMSPE: 12.07% 226, 25C02-cyc44 - RMSE: 0.0060, RMSPE: 13.63% 227, 25C03-cyc192 - RMSE: 0.0044, RMSPE: 8.57% 228, 25C01-cyc256 - RMSE: 0.0046, RMSPE: 8.81% 229, 25C07-cyc134 - RMSE: 0.0084, RMSPE: 3.49% 230, 25C01-cyc42 - RMSE: 0.0041, RMSPE: 4.66% 231, 25C01-cyc248 - RMSE: 0.0042, RMSPE: 1.38% 232, 25C02-cyc37 - RMSE: 0.0064, RMSPE: 15.68% 233, 25C06-cyc132 - RMSE: 0.0036, RMSPE: 38.66% 234, 25C02-cyc145 - RMSE: 0.0050, RMSPE: 4.53% 235, 25C02-cyc34 - RMSE: 0.0054, RMSPE: 17.41% 236, 25C01-cyc57 - RMSE: 0.0044, RMSPE: 3.99% 237, 25C01-cyc247 - RMSE: 0.0036, RMSPE: 14.41% 238, 25C02-cyc38 - RMSE: 0.0058, RMSPE: 16.86% 239, 25C06-cyc88 - RMSE: 0.0036, RMSPE: 13.88% 240, 25C03-cyc165 - RMSE: 0.0033, RMSPE: 10.08% 241, 25C07-cyc85 - RMSE: 0.0041, RMSPE: 6.20% 242, 25C01-cyc78 - RMSE: 0.0032, RMSPE: 3.91% 243, 25C03-cyc111 - RMSE: 0.0044, RMSPE: 4.54% 244, 25C01-cyc281 - RMSE: 0.0055, RMSPE: 3.74% 245, 25C07-cyc97 - RMSE: 0.0083, RMSPE: 3.68% 246, 25C01-cyc45 - RMSE: 0.0059, RMSPE: 2.74% 247, 25C07-cyc69 - RMSE: 0.0029, RMSPE: 6.05% 248, 25C07-cyc102 - RMSE: 0.0071, RMSPE: 2.38% 249, 25C06-cyc213 - RMSE: 0.0099, RMSPE: 45.86% 250, 25C08-cyc43 - RMSE: 0.0082, RMSPE: 6.63% 251, 25C01-cyc208 - RMSE: 0.0042, RMSPE: 12.45% 252, 25C08-cyc60 - RMSE: 0.0102, RMSPE: 5.85% 253, 25C06-cyc30 - RMSE: 0.0047, RMSPE: 3.59% 254, 25C01-cyc201 - RMSE: 0.0036, RMSPE: 13.51% 255, 25C01-cyc144 - RMSE: 0.0050, RMSPE: 16.35% 256, 25C04-cyc3 - RMSE: 0.0043, RMSPE: 6.55% 257, 25C07-cyc130 - RMSE: 0.0093, RMSPE: 2.12% 258, 25C07-cyc30 - RMSE: 0.0024, RMSPE: 3.49% 259, 25C06-cyc163 - RMSE: 0.0037, RMSPE: 40.92% 260, 25C01-cyc171 - RMSE: 0.0051, RMSPE: 18.65% 261, 25C02-cyc163 - RMSE: 0.0048, RMSPE: 5.09% 262, 25C02-cyc26 - RMSE: 0.0058, RMSPE: 20.15% 263, 25C01-cyc237 - RMSE: 0.0037, RMSPE: 3.80% 264, 25C04-cyc9 - RMSE: 0.0047, RMSPE: 4.42% 265, 25C02-cyc4 - RMSE: 0.0058, RMSPE: 33.19% 266, 25C03-cyc43 - RMSE: 0.0035, RMSPE: 2.20% 267, 25C06-cyc17 - RMSE: 0.0064, RMSPE: 3.04% 268, 25C07-cyc87 - RMSE: 0.0041, RMSPE: 7.27% 269, 25C06-cyc209 - RMSE: 0.0086, RMSPE: 12.99%
Transformer Model
然后是我们的Transformer模型。这里我只使用了Encoder的部分。由于模型对数据处理的不同,这个模型的输入为[batch_size, 4, 2]。从思路上来说,和CNN模型的设计较为类似,都是将频率看作一个序列。只不过Attention会通过自注意力机制捕捉不同位置的依赖关系,同时这些不同频率间的顺序关系可能也并没有那么强,这也是使用注意力模型的一个原因。
注:笔者也尝试使用了包含encoder+decoder结构的transformer。并将频率作为输入。似乎精度并没有前一个模型好。
Epoch [50/1000], Train Loss: 0.000446, Valid Loss: 0.000180, Valid RMSE: 0.0134, Valid RMSPE: 250.8297 Epoch 00094: reducing learning rate of group 0 to 4.0000e-04. Epoch [100/1000], Train Loss: 0.000083, Valid Loss: 0.000032, Valid RMSE: 0.0057, Valid RMSPE: 150.9820 Epoch [150/1000], Train Loss: 0.000072, Valid Loss: 0.000087, Valid RMSE: 0.0093, Valid RMSPE: 85.9713 Epoch 00153: reducing learning rate of group 0 to 1.6000e-04. Epoch [200/1000], Train Loss: 0.000049, Valid Loss: 0.000027, Valid RMSE: 0.0052, Valid RMSPE: 107.9976 Epoch 00203: reducing learning rate of group 0 to 6.4000e-05. Epoch [250/1000], Train Loss: 0.000039, Valid Loss: 0.000025, Valid RMSE: 0.0050, Valid RMSPE: 70.2411 Epoch 00250: reducing learning rate of group 0 to 2.5600e-05. Epoch [300/1000], Train Loss: 0.000034, Valid Loss: 0.000022, Valid RMSE: 0.0047, Valid RMSPE: 76.2402 Epoch 00311: reducing learning rate of group 0 to 1.0240e-05. Epoch [350/1000], Train Loss: 0.000033, Valid Loss: 0.000016, Valid RMSE: 0.0040, Valid RMSPE: 60.8040 Epoch [400/1000], Train Loss: 0.000030, Valid Loss: 0.000015, Valid RMSE: 0.0038, Valid RMSPE: 68.9895 Epoch 00430: reducing learning rate of group 0 to 4.0960e-06. Epoch [450/1000], Train Loss: 0.000029, Valid Loss: 0.000016, Valid RMSE: 0.0040, Valid RMSPE: 47.7553 Epoch 00461: reducing learning rate of group 0 to 1.6384e-06. Epoch 00492: reducing learning rate of group 0 to 6.5536e-07. Epoch [500/1000], Train Loss: 0.000027, Valid Loss: 0.000015, Valid RMSE: 0.0038, Valid RMSPE: 48.0778 Epoch 00523: reducing learning rate of group 0 to 2.6214e-07. Epoch [550/1000], Train Loss: 0.000029, Valid Loss: 0.000015, Valid RMSE: 0.0039, Valid RMSPE: 46.8217 Epoch 00554: reducing learning rate of group 0 to 1.0486e-07. Epoch 00585: reducing learning rate of group 0 to 4.1943e-08. Epoch [600/1000], Train Loss: 0.000027, Valid Loss: 0.000015, Valid RMSE: 0.0038, Valid RMSPE: 44.6569 Epoch 00616: reducing learning rate of group 0 to 1.6777e-08. Epoch 00647: reducing learning rate of group 0 to 6.7109e-09. Epoch [650/1000], Train Loss: 0.000027, Valid Loss: 0.000015, Valid RMSE: 0.0038, Valid RMSPE: 43.4723 Epoch [700/1000], Train Loss: 0.000028, Valid Loss: 0.000015, Valid RMSE: 0.0038, Valid RMSPE: 43.9302 Epoch [750/1000], Train Loss: 0.000028, Valid Loss: 0.000015, Valid RMSE: 0.0038, Valid RMSPE: 43.6970 Epoch [800/1000], Train Loss: 0.000028, Valid Loss: 0.000015, Valid RMSE: 0.0038, Valid RMSPE: 44.2087 Epoch [850/1000], Train Loss: 0.000027, Valid Loss: 0.000015, Valid RMSE: 0.0038, Valid RMSPE: 44.4337 Epoch [900/1000], Train Loss: 0.000027, Valid Loss: 0.000015, Valid RMSE: 0.0038, Valid RMSPE: 44.6080 Epoch [950/1000], Train Loss: 0.000028, Valid Loss: 0.000015, Valid RMSE: 0.0038, Valid RMSPE: 44.1336 Epoch [1000/1000], Train Loss: 0.000027, Valid Loss: 0.000015, Valid RMSE: 0.0038, Valid RMSPE: 43.8952
将RMSE结果与CNN的比较,Attention based模型的精度平均要比CNN模型高40%。


从比较图中我们也可以发现,Valid Sample 2在中频段的预测效果,Transformer模型要明显好于CNN模型。
Conclusion
- 我们在公开数据集上实验了通过特征频率阻抗预测EIS。预测的精度RMSE目前可以低于4mΩ。这代表特征频率下的EIS可以很大程度上包含全频段的EIS信息。
- 关于特征频率的选择依然有研究的空间。

