


Dropout是万能的吗?unimol_tools中molecule arch 与 oled arch效果对比
Molecule Arch和OLED Arch对比
本次比赛的baseline是基于Uni-mol来做的,官方给出unimol tools中包含两组预训练模型的权重(Molecule和OLED)两组,下面为两组权重对应的模型架构。Molecule版本预训练阶段包括两个任务,3D position recovery 以及 masked atom prediction。而OLED版本则是在原本的基础上加上了homo lumo supervised task。(竞赛讨论群里听到的,如有错误,恳请更正。)
def molecule_architecture():
args = argparse.ArgumentParser()
args.encoder_layers = getattr(args, "encoder_layers", 15)
args.encoder_embed_dim = getattr(args, "encoder_embed_dim", 512)
args.encoder_ffn_embed_dim = getattr(args, "encoder_ffn_embed_dim", 2048)
args.encoder_attention_heads = getattr(args, "encoder_attention_heads", 64)
args.dropout = getattr(args, "dropout", 0.1)
args.emb_dropout = getattr(args, "emb_dropout", 0.1)
args.attention_dropout = getattr(args, "attention_dropout", 0.1)
args.activation_dropout = getattr(args, "activation_dropout", 0.0)
args.pooler_dropout = getattr(args, "pooler_dropout", 0.2)
args.max_seq_len = getattr(args, "max_seq_len", 512)
args.activation_fn = getattr(args, "activation_fn", "gelu")
args.pooler_activation_fn = getattr(args, "pooler_activation_fn", "tanh")
args.post_ln = getattr(args, "post_ln", False)
args.backbone = getattr(args, "backbone", "transformer")
args.kernel = getattr(args, "kernel", "gaussian")
args.delta_pair_repr_norm_loss = getattr(args, "delta_pair_repr_norm_loss", -1.0)
return args
def oled_architecture():
args = argparse.ArgumentParser()
args.encoder_layers = getattr(args, "encoder_layers", 8)
args.encoder_embed_dim = getattr(args, "encoder_embed_dim", 512)
args.encoder_ffn_embed_dim = getattr(args, "encoder_ffn_embed_dim", 2048)
args.encoder_attention_heads = getattr(args, "encoder_attention_heads", 64)
args.dropout = getattr(args, "dropout", 0.1)
args.emb_dropout = getattr(args, "emb_dropout", 0.1)
args.attention_dropout = getattr(args, "attention_dropout", 0.1)
args.activation_dropout = getattr(args, "activation_dropout", 0.0)
args.pooler_dropout = getattr(args, "pooler_dropout", 0.0)
args.max_seq_len = getattr(args, "max_seq_len", 1024)
args.activation_fn = getattr(args, "activation_fn", "gelu")
args.pooler_activation_fn = getattr(args, "pooler_activation_fn", "tanh")
args.post_ln = getattr(args, "post_ln", False)
args.backbone = getattr(args, "backbone", "transformer")
args.kernel = getattr(args, "kernel", "linear")
args.delta_pair_repr_norm_loss = getattr(args, "delta_pair_repr_norm_loss", -1.0)
return args
实验结果比较
显而易见,这两组有着两个显著的差别(其余差别暂不阐述):
- 参数量,molecule encoder layer有15层,而oled encoder layer只有8层。
- pooler layer dropout
考虑到这两者的差异,我便做了三组实验,分别是使用oled,使用+dropout molecule以及-dropout molecule,同时查看他们在, 以及,上的效果。实验结果是我在训练集中分出一部分作为测试集来做的,因此如果你做之后结果有出入,就怪随机之神吧(逃)。最终结果如下:
| OLED | Molecule+pd | Molecule-pd | |
|---|---|---|---|
| 0.6310 | 0.6421 | 0.6695 | |
| 0.7065 | 0.7055 | 0.7406 | |
| 0.8603 | 0.8268 | 0.8810 | |
| 0.7436 | 0.7256 | 0.7800 |
从结果来看,在存在pooler dropout的情况下,OLED的和于Molecule接近,然而却小于Molecule,同时homo,lumo的确实明显大于Molecule,去除dropout后全线指标提升。说明三件事:
- 关于homo lumo的有监督预训练是有效的
- 因为模型规模的差异,在其他的指标上拟合效果,OLED不如Molecule。
- pooler层使用dropout会影响模型性能(这个指regression任务中)。
Dropout对Regression任务的影响
训练过程中,经过dropout后输出的方差发生了变化,这个方差的变化在经过非线性层的映射以后会导致输出发生偏移,同时回归问题的输出是一个绝对值,因此对这种变化就很敏感。当然去除droput后可能也会带来其他的问题,例如过拟合等等,因此出现问题后欢迎交流讨论问题以及解决方案。
关于regression中使用dropout的相关实验
针对dropout的问题,也有一篇文章做了相关阐述[link]。现在我们从这篇文章的思路出发对该问题进行进一步探索。在该文章中,作者通过一个简单的实验,从结果出发,论述了dropout对regression task的影响。(下面有很多图,如果看不到的话及时在评论区说一下,我调整一下)
实验数据准备与模型选择
文中作者做了一个简单的数据集,下图是从数据集中采样的数据。我们的任务也很简单,求圆柱体的体积V,图中的圆就表示圆柱体的底面积,其半径就是圆柱体的底面半径,颜色则是与圆柱体的高度有一个映射关系。这样我们的target也是十分显而易见::

作者使用, 范围内半径和高度均匀分布来生成训练集和测试集,使用MSE作为loss function。为了解决这个问题,作者构建了VGG backbone + Linear head 的网络架构,网络架构如下图所示。
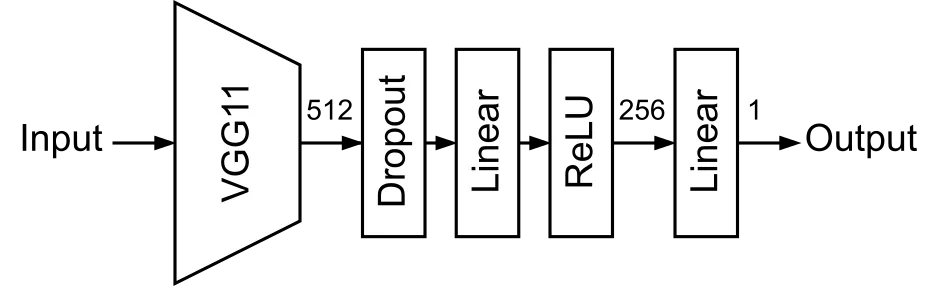
可以看到作者在网络中加上了dropout,然而最终结果如何呢?且看train loss和valid loss的变化如下。
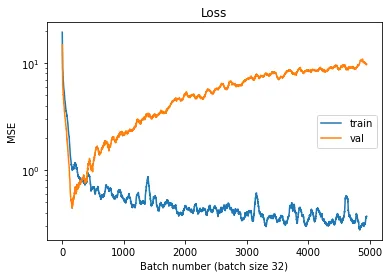
当我们第一眼看到这个loss曲线的时候,我们根据经验,会认为这个是因为模型过拟合了。是的,这个和过拟合的曲线是一样的。但是,我们的训练集和验证集来自于同一分布,怎么可能过拟合呢?那问题出在哪里呢?
Inference结果分析
作者对训练时预测的结果和做inference时预测的结果进行了可视化,如下图所示。从图中我们可以看到Inference过程中,模型对正确答案明显是低估的,为什么会这样呢,train和eval模式下模型发生了什么变化呢?显而易见,eval模式下,模型会关闭dropout。
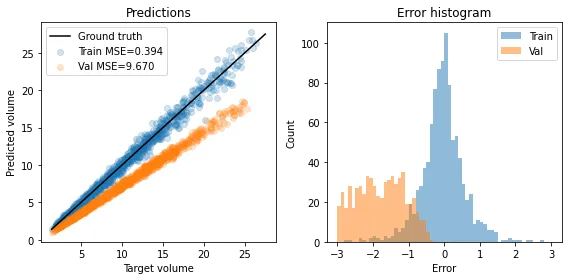
如果我们尝试把dropout给去掉呢?作者去掉dropout之后再对结果进行可视化,结果如下。

Loss曲线也看起来正常多了。
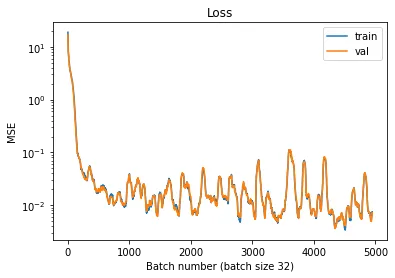
但是为什么会发生这种情况呢?
dropout进一步探究
首先我们回顾一下dropout的用法,dropout在训练的过程中,会以p的概率将隐藏层的神经元置为0,同时会将其他的神经元乘以,以保证输出的期望值的一致(这里所说的是其中一种dropout的实现方式,还有一种实现是在预测的过程中*p,但保持测试阶段直接输出的这种方式似乎更为流行)。为了方便讨论,我们假设dropout为一个单独随机变量,则符合以下分布: 则通过隐藏层后的变化为: 我们假设随机变量,则s: 于是。我们假设的期望和方差分别是和,易得的期望值和方差分别为(独立随机变量乘积与方差计算): 很明显,dropout之后期望没有发生变化,但是方差发生了变化。
也就是说使用了dropout后,在训练时隐藏层的神经元的输出的方差会与验证时输出的方差不一致。这个方差的改变导致在经过非线性层的映射后导致输出值发生偏移,最终导致在验证集上效果不好。regression输出是绝对值,跟classification中的相对不同,regression对这种变化相对更敏感。因此在回归问题上最好不要用dropout。
参考资料






Zhifeng Gao
GG