




AI+分子模拟:从 Score Matching 到 Diffusion Model,从Swiss Roll到Butane(上)

©️ Copyright 2024 @ Authors
作者: 王程玄 📨 王新颜 📨 张林峰 📨
日期:2024-03-12
共享协议:本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
背景介绍
Diffusion Model是基于随机过程的生成模型,在过去几年中,由于其图像生成领域的优秀表现,使其成为广泛瞩目的生成模型之一。此类模型以物理学中的扩散过程为灵感,模仿如何通过逐渐加入噪声将数据样本转化为高斯噪声,并在采样过程中逐渐去除这些噪声以生成新的数据样本。
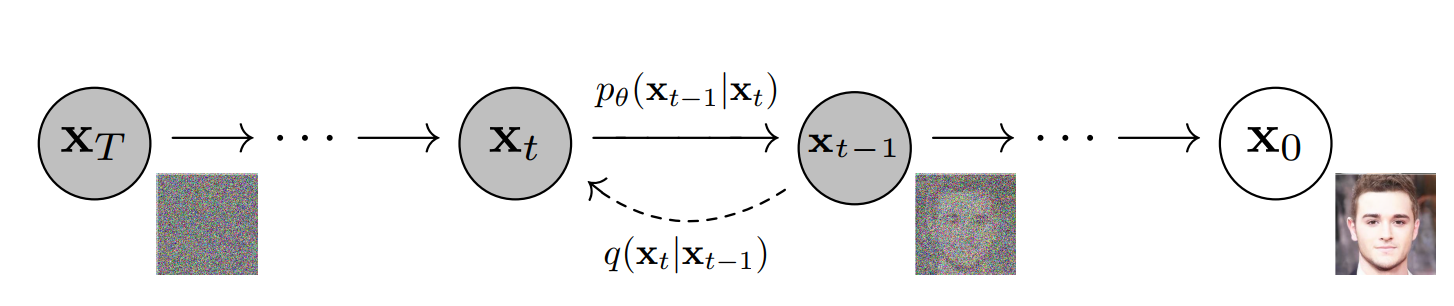
Diffusion Model在图像合成、声音生成乃至分子场景创建等多个领域展示了卓越的性能,因其独特的生成方式在数据生成领域,尤其是在生成复杂数据分布方面成为一个重要研究方向。
与此同时,Diffusion model和物理化学过程有着相似的思想方式,对于我们关注的在势能面上的采样过程而言,即类似于在diffusion model生成的分布模型上进行采样的过程,其中scoring matching的方法即通过神经网络(暴力的函数拟合器)的方法对实际的概率分布中的梯度进行拟合,进而做到对概率分布的描述。类似的相似关系在Al4S和生成模型的关系中也常常可以看到,如中科院物理所王磊教授在深势科技的一个报告。这里将其中两页PPT截图分享如下,阐释了生成模型中的变量和物理化学中的变量关系:

在本notebook当中,我们首先结合一个简单的的二维分布,对scoring matching以及diffusion model的原理进行初步的认识和实现。
目录
- 提前准备:Dataset and Notation
- Score Matching: 一切由此出发
- NeuralODE, flow matching, and Rectified flow
- 说回到consistency models
- 这与AI for Science有什么关系
阅读本文可能需要30分钟以上,边运行边消化可能需要1-2小时。
考虑到读者的时间通常比较碎片化,以下总结出本文要点(篇幅所限较为简略,缩写大多在正文中会被解释):
- 技术路径:对Consistency Model 来说,有一条相对清晰的技术演化路径,从score matching,到跟SDE和非平衡热物理更相关的Diffusion Model等,以及跟ODE更相关的NeuralODE和flow matching等;
- 理论算法:Probability Flow (PF) ODE是SDE和ODE的一个桥梁(进而是Consistency Model被蒸馏训练的基础)
- 技术细节:尽管我们会看到很多formulation(model arch./loss function/training scheme等)之间的等价性,但实际效果可能会千差万别。在本系列代码中,我们会看到,哪怕是一个二维的简单例子,对于很多算法来说。也需要很多微妙的细节处理,例如噪音大小、时间步长策略、采样策略等。这些细节也体现在了consistency models的很多“迷之操作”中。
- 行业影响:这可能对AIGC有啥影响呢?简单来说,如果效果真的好,基本就是能更快、更低成本、更大规模地出图(当然,这里有待验证)。
- 这跟AI for Science(AI4S)又有什么关系呢? 这是本文作者最最兴奋的地方。卖个关子,没时间跑代码的同学,也欢迎你划过去看一看。那里也会讨论“consistency model”是否意味着扩散模型的终结。
📖 上手指南
本文档可在 Bohrium Notebook 上直接运行。你可以点击界面上方按钮 开始连接,选择 bohrium-notebook 推荐镜像。由于涉及到少量机器学习训练任务,推荐使用任意GPU节点配置,稍等片刻即可运行。
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple Collecting matplotlib Downloading https://pypi.tuna.tsinghua.edu.cn/packages/c1/f2/325897d6c498278b0f8b460d44b516f5db865ddb4ba9018e9fe58a3e4633/matplotlib-3.8.3-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (11.6 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 11.6/11.6 MB 3.0 MB/s eta 0:00:0000:0100:01 Collecting scikit-learn Downloading https://pypi.tuna.tsinghua.edu.cn/packages/bc/b9/6a637668d69de04b7f8b917e837aff282950601f09998a5f6c9f23f6642d/scikit_learn-1.4.1.post1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (12.1 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 12.1/12.1 MB 1.3 MB/s eta 0:00:0000:0100:01 Collecting cycler>=0.10 Downloading https://pypi.tuna.tsinghua.edu.cn/packages/e7/05/c19819d5e3d95294a6f5947fb9b9629efb316b96de511b418c53d245aae6/cycler-0.12.1-py3-none-any.whl (8.3 kB) Requirement already satisfied: numpy<2,>=1.21 in /opt/mamba/lib/python3.10/site-packages (from matplotlib) (1.24.2) Collecting kiwisolver>=1.3.1 Downloading https://pypi.tuna.tsinghua.edu.cn/packages/6f/40/4ab1fdb57fced80ce5903f04ae1aed7c1d5939dda4fd0c0aa526c12fe28a/kiwisolver-1.4.5-cp310-cp310-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (1.6 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.6/1.6 MB 1.3 MB/s eta 0:00:00a 0:00:010m Collecting fonttools>=4.22.0 Downloading https://pypi.tuna.tsinghua.edu.cn/packages/f1/64/9be0559ad8651c9b1cd5ba9aabc9f9b59a8618e931d33ceb40297056445e/fonttools-4.50.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (4.6 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 4.6/4.6 MB 1.5 MB/s eta 0:00:0000:0100:01 Collecting pyparsing>=2.3.1 Downloading https://pypi.tuna.tsinghua.edu.cn/packages/9d/ea/6d76df31432a0e6fdf81681a895f009a4bb47b3c39036db3e1b528191d52/pyparsing-3.1.2-py3-none-any.whl (103 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 103.2/103.2 kB 330.0 kB/s eta 0:00:00a 0:00:01 Collecting pillow>=8 Downloading https://pypi.tuna.tsinghua.edu.cn/packages/cb/c3/98faa3e92cf866b9446c4842f1fe847e672b2f54e000cb984157b8095797/pillow-10.2.0-cp310-cp310-manylinux_2_28_x86_64.whl (4.5 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 4.5/4.5 MB 1.4 MB/s eta 0:00:0000:0100:01 Collecting contourpy>=1.0.1 Downloading https://pypi.tuna.tsinghua.edu.cn/packages/58/56/e2c43dcfa1f9c7db4d5e3d6f5134b24ed953f4e2133a4b12f0062148db58/contourpy-1.2.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (310 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 310.7/310.7 kB 1.5 MB/s eta 0:00:00a 0:00:01 Requirement already satisfied: python-dateutil>=2.7 in /opt/mamba/lib/python3.10/site-packages (from matplotlib) (2.8.2) Requirement already satisfied: packaging>=20.0 in /opt/mamba/lib/python3.10/site-packages (from matplotlib) (23.0) Collecting joblib>=1.2.0 Downloading https://pypi.tuna.tsinghua.edu.cn/packages/10/40/d551139c85db202f1f384ba8bcf96aca2f329440a844f924c8a0040b6d02/joblib-1.3.2-py3-none-any.whl (302 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 302.2/302.2 kB 2.3 MB/s eta 0:00:00a 0:00:01 Collecting threadpoolctl>=2.0.0 Downloading https://pypi.tuna.tsinghua.edu.cn/packages/1e/84/ccd9b08653022b7785b6e3ee070ffb2825841e0dc119be22f0840b2b35cb/threadpoolctl-3.4.0-py3-none-any.whl (17 kB) Requirement already satisfied: scipy>=1.6.0 in /opt/mamba/lib/python3.10/site-packages (from scikit-learn) (1.10.1) Requirement already satisfied: six>=1.5 in /opt/mamba/lib/python3.10/site-packages (from python-dateutil>=2.7->matplotlib) (1.16.0) Installing collected packages: threadpoolctl, pyparsing, pillow, kiwisolver, joblib, fonttools, cycler, contourpy, scikit-learn, matplotlib Successfully installed contourpy-1.2.0 cycler-0.12.1 fonttools-4.50.0 joblib-1.3.2 kiwisolver-1.4.5 matplotlib-3.8.3 pillow-10.2.0 pyparsing-3.1.2 scikit-learn-1.4.1.post1 threadpoolctl-3.4.0 WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv

关于Notation
我们将尽量follow下面的Notation:
用表示数据的真实分布; 表示数据的经验分布; 表示用来给每个数据点做光滑化的Gaussian Kernel。
进一步,表示与的联合分布,对其中进行积分,可得到所谓Parzen density,
Explicit Score Matching (ESM)
Score该怎么学?一个最直观的损失函数是Explicit Score Matching (ESM)损失函数: 这个损失函数看起来自然,但不具有可操作性。原因是未知,那么自然也无法评估。
Implicit Score Matching (ISM)
由于ESM存在的问题,早在2005年,Hyvärinen 便提出了所谓Implicit Score Matching (ISM)的方式:
不难得出,在对数据分布的合理假设要求下,与之间只差一个与参数无关的常数。(具体的证明需要展开的表达式,考虑其中相关的项,并进行分部积分。)
进而,从数据的经验分布出发,对的优化可以进一步转化为对的优化,而后者是完全可操作的。
下面,我们通过Swiss Roll数据集来说明这点。
首先,我们用一个神经网络模型来表示.
注意这里我们没有用一个能量对输入的导数来表示,而是用了一个有两个输出的函数。这有可能会使得不是一个梯度场。
接下来,我们将需要通过如下函数求出雅可比项(Jacobian)
更近一步,我们可以定义ISM的损失函数:
接下来就可以训练了!
[Training step, loss value] [0, 0.1868923008441925] [500, -60.2452278137207] [1000, -110.15348815917969] [1500, -112.88984680175781] [2000, -134.59991455078125] [2500, -112.07180786132812] [3000, -152.19956970214844] [3500, -150.8235626220703] [4000, -165.9660186767578] [4500, -175.6434783935547]
画出损失函数随着训练步数的变化,可以看出在一段简短的平滑期后,损失函数会迅速下降,并最终收敛至-160左右。

下面,我们可以画出这一矢量场在不同取值时的方向和幅度。

Langevin dynamics
单从梯度场的指向可能很难推断实际效果。接下来,我们可以根据在分子动力学课程上学到的内容,通过(这里是over-damped) Langevin dynamics等方式来实现密度分布下的采样: 这里。我们知道,从一个合理的初始分布出发,当的时候,的分布收敛至。
这里我们从 出发,通过逐步减小 来得到 。以下为一种实现。

小结: 结合这个表达式以及上面的运行结果,我们可以畅想一下diffusion model在分子动力学模拟当中的应用场景。如果我们能够建立一个相对完善的势函数,那么对于任何的,我们都能找到对应的完整的势能面。相较于传统的分子动力学采样过程成本会随之降低,并能提高计算的效率。同时也能更容易的跨过较高的能垒,进而简化在传统的采样过程中的增强采样过程。
Sliced score matching(SSM)
上述ISM的方法尽管相对直观,但是很难推广至高维。其原因在于,计算对应的雅可比矩阵计算的复杂度是。
为此,本文讨论的consistency model的一作同学 Yang Song等人提出了Sliced score matching的方法,将ISM的优化问题转化为优化 其中表示一组高维随机向量。这可以通过前向自动微分得到,进而有较高的效率。
在此我们不对SSM做展开,而是直接进入下一个与后面的方法关联性更大的部分,Denoising score matching。
Denoising score matching (DSM)
接下来介绍一篇非常经典的文章, Vincent, P. (2011). A connection between score matching and denoising autoencoders. Neural computation, 23(7), 1661-1674.。
该文章在讨论denoising autoencoders的过程中,介绍了一个比较适合推广至高维做优化的损失函数。首先,考虑对输入的一个边缘分布。以下损失函数 在的条件下也可以用来优化。
进一步,令 ,则有 。
这里我们需要令足够小。直觉上来看,这里在做的事情事实上就是在附近产生幅度为的偏离噪音时,利用来修正这一噪音。
如下我们实现DSM Loss,并做相应的优化。
在这个优化的过程当中,的选择要慎重。。。太大了近似不成立,太小了噪音可能太大。
下面做了一个非常简单的改动后(let , instead of 0.01),会得到比较好的效果。
[Training step, loss value] [0, 100.5608139038086] [500, 81.25548553466797] [1000, 68.4693374633789] [1500, 64.5993881225586] [2000, 64.75675964355469] [2500, 63.39436721801758] [3000, 65.86219024658203] [3500, 62.052799224853516] [4000, 63.11859893798828] [4500, 62.59592056274414]
值得注意的是,这里的噪音并没有下降。 如下图所示。当然,这也是可以预期的,因为DSM的损失函数本身是带有较大的噪音项的。

那么,学到的score 做langevin dynamics的结果如何呢?

值得注意的是,这里其实涉及到一个权衡取舍。过小的时候训练噪音大、过大的时候难以保障数值近似的要求——我们后面会看到,在分子动力学的一些地方也有着类似的现象。感兴趣的读者不妨尝试,如果令或者,效果也挺差的。。
总结
我们再来看一下以下几个损失函数。它们在原则上(不考虑实际的统计收敛性、计算复杂度、模型表示能力和优化效率)均能给出理想的矢量场。
但是,ESM是不直接可用的;ISM效果很好、但因为对Jacobian的需求,面临维数灾难;SSM和DSM看起来没有直接的维数灾难,但当数据维数变高时,直接使用它们也带来了一些进一步的挑战——既包括学习分布(或者score)的挑战、也包括学好score后生成样本带来的挑战。例如,在学好数据里的能量函数后需要用本文所介绍的Langevin Dynamics做采样。熟悉分子模拟的同学会清楚,如果相应的energy landscape比较崎岖、或者有能量或熵带来的能垒,那么这样的dynamics就会受到rare event的影响。这在数据科学中也是可以预期的(这也与mode collapse这一问题有很强的相关性)。
最后,值得一提的是,如果你能掌握推导这些损失函数相互等价性所需要的技巧,那么推导diffusion model、consistency model等对应的算法原理也不成问题。因为score matching所对应的原理和技巧恰好也是后续算法发展的基础。
Scoring Matching遇到的问题
在笔者理解上述的数学过程以及代码实现的过程当中,尝试了一些其他数据集在scoring matching方法中的实现。偶然间发现,scoring matching对于对称性较高的数据集的表现效果明显不如上面的Swiss roll数据集。下面我们将通过一个简单的同心圆模型来说明这个问题。在这个圆的周长上,散点以高斯函数分布,使得整个空间中的函数可导,符合scoring matching的要求。
同时如上所述,scoring matching对空间中不连续可导的分布情况无法做到很好的预测,相较于对称性,在以前尝试的数据集当中遇到的问题更多可能集中于此。
定义两个同心圆,半径分别为1和2.此处采用极坐标的方式建模,由于要求的是在面积上均匀分布,因此半径需要平方再开方以达到在指定面积上均匀采样的目的。
生成样本数据,并可视化样本数据图形分布。

定义神经网络并训练。
[Training step, loss value] [0, 0.31529828906059265] [1000, -50.432655334472656] [2000, -52.342926025390625] [3000, -53.0850944519043] [4000, -52.825721740722656]

小结: 从上面的结果中可以看出,对于该对称性较高的体系,scoring matching的效果只能说是差强人意。
在后面的尝试当中,笔者尝试将坐标的输入改为距离的输入,并在应用时逐步更新每个点的距离,再逐步输入。呈现的效果类似于落入局部最小值的情况(在圆的某一段周长上表现的比较好),尝试增大learning rate的值,效果稍微改善但也没有出现很好的结果。出现这样的原因需要进一步的问题探索。
Diffusion model的正向加噪和反向去噪过程
**简述:**Diffusion model可以理解为将原本的样本分布使用Markov过程不断的加入噪音,然后使用神经网络的这一工具作为去除噪音的函数,并构造相关的损失函数进行训练。此处构造损失函数的方式可以使用加噪之前的训练集作为label样本,使用model神经网络预测出的结果作为函数值,同时使用均方根误差作为损失函数(hint: 类似于scoring matching中的ESM构建方式)。但是聪明的数学家显然不想使用这样简单粗暴的方法,结合加噪过程的实现,将这个过程中的每个转变都简单地定义为条件高斯。 因此,在学习过程中,只需要训练高斯扩散核的均值和协方差,并能构建出更为多样可控的损失函数。
正向加噪过程的实现
正向加噪过程可以理解为一个累积的马尔科夫过程,在实际的实现过程中,我们使用逐渐加入高斯噪声的手段,则对应的为:
其中意为在给定时间时刻的状态的条件下,时间时刻状态的概率分布。则对于最终的时刻其分布和初始状态下的分布的关系如下:
对加噪比例进行实现,并计算与之对应的,同时计算和该两者相关的诸多常数

反向去噪过程以及scoring matching
如上述所言,正向加噪过程使用了高斯噪声的逐渐如作为实现,那么去噪过程也是类似的条件高斯过程,则对应的表达式为: 在某些情况下,diffusion model的训练过程可以被看作是一种scoring matching过程。在扩散模型的训练中,模型学习的目标是估计条件分布的分数函数,这与scoring matching的目标相似。在具体的实现步骤方面,扩散模型中的逆向过程需要估计在每一步去噪过程中数据的梯度,这与scoring matching中估计数据分布梯度的目标是一致的。
DDPM
结合上面介绍的diffusion model整体思路,Ho等人提出了一种数值处理方法,整体思想是改变均值函数以及协方差方程的表达方式,进而,我们得到对应时间下一时间间隔的分布和对应时间的分布之间的关系,其中为神经网络的所构建的函数:
这里的表达式的推导应用了scoring matching以及Lagevin Dynamics,因此表达式和直接使用梯度场推导出的有着相当的相似性。
此后,我们对这一过程进行代码实现并查看其训练效果
首先,建立合适的神经网络,即上述公式当中的
在此基础之上构建损失函数并简化,得到最终的表达结果为:
对采样过程进行函数化表达,在后续的流程当中只需要输入原本的样本以及训练出的神经网络即可得到下一时间间隔的样本分布。
实现训练过程,并在训练过程中监控损失函数的输出。同时,打印出随着神经网络的训练得到的在diffusion model的反向去噪过程中的表现结果。
tensor(0.6897, device='cuda:0', grad_fn=<MeanBackward0>) tensor(0.7497, device='cuda:0', grad_fn=<MeanBackward0>) tensor(0.5545, device='cuda:0', grad_fn=<MeanBackward0>) tensor(0.7291, device='cuda:0', grad_fn=<MeanBackward0>) tensor(0.8634, device='cuda:0', grad_fn=<MeanBackward0>) tensor(0.8667, device='cuda:0', grad_fn=<MeanBackward0>) tensor(0.6347, device='cuda:0', grad_fn=<MeanBackward0>) tensor(0.8130, device='cuda:0', grad_fn=<MeanBackward0>) tensor(0.7264, device='cuda:0', grad_fn=<MeanBackward0>) tensor(0.6310, device='cuda:0', grad_fn=<MeanBackward0>)










从结果可以看出,随着神经网络的不断训练,其从高斯分布的散点到我们期待的swiss_roll分布的反响去噪过程的结果越来越接近,说明该神经网络能够做到学习并生成简单的二维分布。
同时,我们测试对称性较高的样本在单纯使用scoring matching和diffusion model的生成效果,发现其在相同的训练步数的条件下,diffusion model具有相对更好的表现,不会出现scoring matching的明显发生和原数据的偏移现象。
和scoring matching以及Langevin Dynamic的联系
对于分子模拟的过程来说,我们常常关心使用的力场以及分子在不同状态下的受力情况。而对于上面提到的Diffusion model来说,貌似并没有看到和实际的物理意义相关联的地方,而是单纯的数学处理来使得神经网络更加完善。实际上,对于优化出来的,其和scoring matching中的有着以下的关系: With: We can derive: 有了这样的关系,我们就可以在Langevin Dynamic中对其中的一阶导项进行描述,并对理想分布进行采样。

可以看到,随着时间步数的推进,最终的分布倾向于我们势函数训练所使用的数据集。相较于diffusion model的反向denoising过程,这个过程中的力场是一个更为可衡量的物理量,我们在这个过程中也可以获得更多的信息。
值得注意的是,和scoring matching中相同,langevin动力学的结果在第三象限出现了概率偏差,同样不是在圆的均匀分布,这可能是一个值得探究的问题。
这跟AI for Science(AI4S)又有什么关系呢?
上述讨论跟AI for Science(AI4S)又有什么关系呢?这里就三个方面进行讨论:整体理论、具体技术、类似场景。
整体理论
从整体理论而言,统计机器学习和统计物理本身就有着极为密切的联系——无论是平衡态的、还是非平衡态的,因此它们往往有着类似的解决方案和难点、也经常可以互相启发。有些时候,熟悉统计物理的同学可能会觉得有很多地方在重复造轮子,例如刘维尔方程似乎被重新发明了很多次;但这也是可以理解的,另一些时候我们则会发现一些地方相互启发很多,尤其是在非平衡热力学中, Jarzynski Equality、Annealed Importance Sampling等都是密切相关的(这里有篇很好的科普文章),这也启发DeepMind来了篇Annealed Importance Sampling meets Score Matching。
当然,在本文作者看来,在统计机器学习中,samples are there;但是在统计物理(及其对应的一系列分子模拟等应用)中,samples need to be sampled in the first place。后者因此会面临更多的问题。
具体技术
本文介绍的一系列手段都能在分子模拟中找到影子。例如,熟悉分子模拟和统计物理的同学不难看出,score matching中的score本质上和原子体系的受力、或者粗粒化自由度所对应的平均力(mean force)是相对应的。甚至在粗粒化模型的构建过程中,人们也经常采用类似技巧(拟合受力),但不同于score matching,这里面的受力是可以作为label给出的。有趣的是,计算mean force的restrained formulation与上面介绍的DSM中噪音加的大小面临的问题很类似。在restrained formulation,restrain强度过高会带来数值问题、restrain强度过低又难以对体系进行有效控制。具体可参考DeePCG和RiD两篇文章。
跳出来看,就consistency model本身而言,有太多AI4S需要考虑的模型某种意义上也算是“consistency model”了,例如电子结构模型、有限元模型等。这里consistency distillation蒸馏出更高效方案的思路也值得借鉴。
类似场景
类似场景很多,主要还是因为有太多生成类或者优化类的任务。总体来说,GPT里面的三个字,Generative(生成型任务)、Pre-trained(预训练策略)、Transformer(统一模型框架)在科学领域也有很多的应用。这里篇幅所限,只给出两个:



wangxy@dp.tech
Linfeng Zhang
pignoi