


一、固定半径近邻搜索
a. 定义
固定半径近邻搜索(Fixed-radius Neighbor Search)是一种邻居搜索算法,旨在查找数据集中距离指定目标在一固定半径范围内的所有对象。具体来说,它不仅要查找距离最近的邻居,还需要找到指定半径内的所有邻居对象(如r图1,左侧)。
查询到的邻居信息会以临近表(Neighbor List)的形式进行保存(如r图1,右侧)。通常,它会按照原子序号进行排布,并依次存储各粒子的邻居信息。
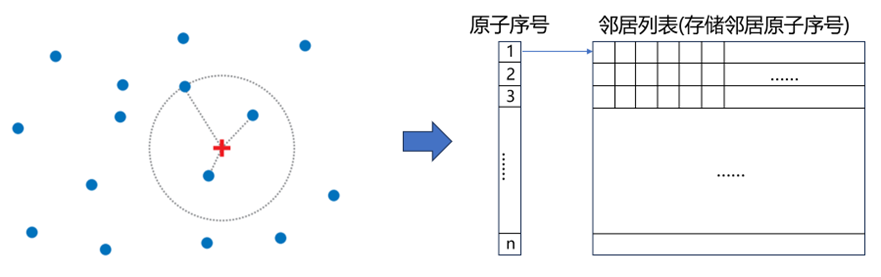
图1 固定半径邻居搜索及邻居表。其中左侧为一示例系统,红色十字为目标对象,圆形范围内的粒子即为其固定半径内近邻。
b. 应用场景
该算法在诸多领域中均有广泛使用,例如分子动力学模拟(MD),离散元方法(DEM),蒙特卡罗方法(MCS)和地理信息系统(GIS)等。 一个典型的应用是在MD之中,用于计算某特定粒子的邻居,并以此计算对应的相互作用力,形成相应的动力学行为。
在这些使用场景中,涉及的空间类型各异,但大致可以分为三类,即稠密空间、稀疏空间和非均一空间。稠密空间通常指是在特定区域内,对象之间的距离较小,对象数量相对较多,密集地堆积在一起形成连续的分布的空间;稀疏空间则指的是在特定区域内,对象之间的距离较大,对象数量相对较少的空间。此外,还存在一类具有不同大小对象的空间即非均一空间,通过一些技术,如stencil模板、动态调整等,可以将其归类为前两种空间类型之一。

图2 主要空间类型
从应用角度而言,建立一个适用于多种场景、跨平台、高效的通用固定半径邻居搜索算法库,可以为不同领域的研究人员提供一种统一的工具,不仅能够降低开发和维护成本,还可以促进知识交流和跨领域合作,为科学和工程的创新提供便利。为此我们开发了DP-NBLIST。
二、DP_NBLIST
a. Motivation
该library旨在提供一种高性能、跨平台的固定半径近邻搜索算法实现。它包含三种适用于不同空间类型的搜索算法,支持CPU和GPU两种类型的运算。它对于输入输出格式进行了特别规约,以适配绝大多数仿真框架。
b. 结构设计
DP-NBLIST由三大模块构成(如图3):
(a)域模块:处理与仿真空间(域)的相关信息,包括空间的几何尺寸(size)和形状(angle),以及输入坐标的周期性规约(Warp函数)以及距离计算(calDistance)。
(b)邻近表模块:辅助邻近信息的构建和管理,包括它的构建(Build),更新(Update)和重置(Reset)。
(c)搜索算法模块:主要包含三种邻近搜索(Neighbor Search)的算法的CPU和GPU实现。

图3 DP-NBLIST的三大主要模块
c. 三类算法实现
下面将对DP-NBLIST包含的三种算法进行简要说明,更多算法细节可参考我们的后续论文 。
在正式介绍算法细节之前,让我们设想一下最直觉的Neighbor Search算法:对于一个粒子系统,构建系统中每个粒子的固定半径邻居关系,需要遍历其所有潜在邻居粒子(即剩余的所有粒子),然后检验两者间的特征距离是否满足在指定半径之内(截断半径,cut-off radius - rc),以此为基准构建Neighbor List。
上述过程主要包含两步:(1)查找潜在邻居粒子,(2)判断潜在邻居粒子是否为真正邻居。显然上述算法具有的时间复杂度,并不适于大规模场景。对此,各类高效率Neighbor Search算法应运而生。这些算法在结构上具有相似性,即在步骤(1)中进行拓展优化,使用各种方法来提高查找潜在邻居粒子的效率。
1. The Linked Cell Method
Linked Cell方法是一种基于网格(Cell)的近邻搜索方法。它包含三个步骤(如图4):(1)使用Cell进行空间划分,(2)基于Cell进行潜在邻居粒子的查找,(3)判断潜在邻居粒子是否为真正邻居。
该方法可以将特定粒子的潜在邻居,有效的高效地缩减为其所在Cell的邻近Cell中的粒子(2D为9个邻接Cells,3D则为27个邻接Cells,如图4, b)。
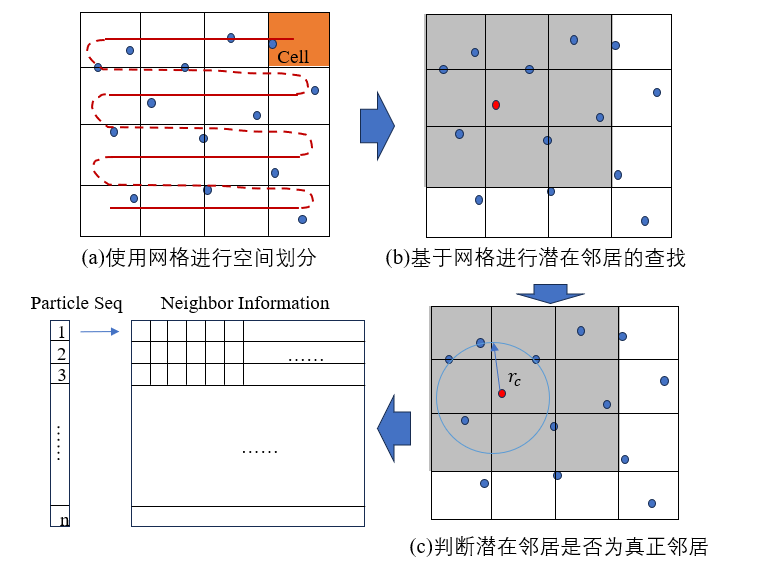
局限:在稀疏空间(存在对于大量空网格的随机读取)和rc较小(划分Cell过多,以[50,50,50]空间大小、rc = 1为例,需要划分125000个Cell)的场景下,性能表现不佳。
图4 Cell List近邻搜索算法
2. The Octree Method
Octree方法在步骤上与Linked Cell类似,区别主要在于空间划分。Octree方法使用了八叉树数据结构对系统中的粒子进行重组,以实现对于空间的划分。如图5 (a),此处以4个粒子一组构建八叉树,然后以层次地构建划分空间,然后相邻距离进行潜在邻居的查找。

图5 基于Octree的近邻搜索算法
局限:在中等稠密空间和rc居中的场景下(此时建树较为昂贵,而树结构带来的潜在邻居查找效率优势不明显),性能表现不佳。
3. The Hash-based Method
Hash-based方法也是一种基于Cell的搜索算法。与Linked Cell不同,它使用Morton码对空间进行划分(如图5,a)。Morton码是一种空间填充曲线,能够将多维空间中的点交错相邻的映射到一维空间,常用于近似邻居搜索算法。这种划分方式能够使多维空间中相邻的数据在低维编码中也相对接近,使得数据在存储时处于相邻或连续的内存地址上,充分利用硬件缓存(Cache)和顺序读取的优势,显著提高总体效率。

图5 基于Hash关系的近邻搜索算法
此外,我们对存储的数据结构也进行了优化。如图6 (a),我们在构建空间划分时,并不存储Cell中的所有粒子,而是在排序的基础上,仅存储每个Cell中起始和末尾粒子的序号,以进一步加强数据的关联性。在读取时(如图6 b),则使用顺序填充的方法,准确读取所有粒子。

图6 基于Hash关系近邻搜索算法的数据结构
局限:在稀疏空间和rc较小的场景下(包含附加的数据排序和处理步骤),性能表现不佳。
d. 应用案例
此处将通过一个实例,来说明如何使用DP-NBLIST。
此处的模块编译于Github Link,模块使用pybind11进行封装,python环境版本3.10。
初步文档可见于Link。
模块包含六种可选算法:"Linked_Cell-CPU", "Linked_Cell-GPU", "Octree-CPU", "Octree-GPU", "Hash-CPU"以及"Hash-GPU"。
注意GPU算法需要在包含GPU的环境中运行,且需要安装相关支持包(详见文档)。
CPU information: x86_64 Current CPU frequency: 2.5000080000000007 GHz Python version: 3.10.13 (main, Sep 11 2023, 13:21:10) [GCC 11.2.0] 10 ['Box', 'NeighborList', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'get_max_threads', 'set_num_threads']

搜索结果:[[ 1 289] [ 8 499] [ 16 402] [ 99 220] [155 848] [164 939] [220 99] [228 892] [243 912] [260 950] [289 1] [321 959] [370 884] [402 16] [403 455] [416 500] [455 403] [499 8] [500 416] [780 819] [819 780] [848 155] [884 370] [892 228] [912 243] [919 932] [932 919] [939 164] [950 260] [959 321]]
三、分析测试
a. 准确率测试
此处的准确率计算基于Asap3进行。
Run a accuracy test on dataset of particle number = 1000 and rc = 2.1 Pass the accuracy test of rc-2.1!
b. 效率测试
此处的效率测试以Freud为基准,并涵盖稠密和稀疏两种空间类型。
Freud是一种主要用于分子动力学模拟计算库,它提供了一系列强大的工具以辅助相关研究,其中就包括Fixed-radius Neighbor Search的算法实现,也是目前的SOTA方法。
它主要部署了两种算法:AABB Tree和Cell List方法。
1. 线程调整
开发中,我们发现对于性能影响较大的因素除编译模式外,还有模块的多线程设置。在cpp源码中,我们使用了OpenMP进行多线程计算,但在Python平台计算时,由于Python全局解释器锁(GIL)的存在,需要进行线程数量的人工指定。
(GIL 是一种用于管理对 Python 对象访问的互斥锁,确保任何时候只有一个线程执行 Python 字节码。这意味着,即使在多核处理器上,Python也是以一种类似串行的方式运行。)
一个恰当的线程数量设置,可以带来更为优越的性能。但线程数量的设置与运行平台关系很大,运行前建议进行试算和调整,以获得更好的性能。
博弈过程:线程创建、同步额外开销 vs 并行计算的效能提升
epoch: 1, time: 7.6224009195963545 epoch: 2, time: 7.0485273996988935 epoch: 3, time: 5.719423294067383 epoch: 4, time: 5.661487579345703 epoch: 5, time: 5.644400914510091 epoch: 6, time: 5.661567052205403 epoch: 7, time: 5.756855010986328 epoch: 8, time: 5.588213602701823 epoch: 9, time: 5.665938059488933 epoch: 10, time: 5.683501561482747 epoch: 11, time: 5.616346995035808 epoch: 12, time: 5.667289098103841 epoch: 13, time: 5.662361780802409 epoch: 14, time: 5.961418151855469 epoch: 15, time: 5.690654118855794 epoch: 16, time: 5.549828211466472 epoch: 17, time: 5.64726193745931 epoch: 18, time: 5.6391557057698565 epoch: 19, time: 5.764166514078776 epoch: 20, time: 5.968888600667317 epoch: 21, time: 5.892594655354817 epoch: 22, time: 5.648215611775716 epoch: 23, time: 5.618651707967122 epoch: 24, time: 5.572875340779622 epoch: 25, time: 5.557854970296224 epoch: 26, time: 5.539735158284505 epoch: 27, time: 5.762815475463867 epoch: 28, time: 5.634784698486328 epoch: 29, time: 5.601088205973308

epoch: 1, time: 106.46494229634602 epoch: 2, time: 106.50801658630371 epoch: 3, time: 106.63461685180664 epoch: 4, time: 106.78823788960774 epoch: 5, time: 102.97695795694987 epoch: 6, time: 85.02689997355144 epoch: 7, time: 85.13522148132324 epoch: 8, time: 85.45891443888347 epoch: 9, time: 85.18775304158528 epoch: 10, time: 84.90331967671712 epoch: 11, time: 84.94432767232259 epoch: 12, time: 84.75025494893391 epoch: 13, time: 84.91404851277669 epoch: 14, time: 84.74000295003255 epoch: 15, time: 85.09000142415364 epoch: 16, time: 85.0232442220052 epoch: 17, time: 85.7243537902832 epoch: 18, time: 84.98080571492513 epoch: 19, time: 84.96157328287761 epoch: 20, time: 85.42386690775554 epoch: 21, time: 86.12314860026042 epoch: 22, time: 85.00051498413086 epoch: 23, time: 85.3746732076009 epoch: 24, time: 85.5705738067627 epoch: 25, time: 85.98144849141438 epoch: 26, time: 85.3716532389323 epoch: 27, time: 85.78769365946452 epoch: 28, time: 85.4945182800293 epoch: 29, time: 86.08635266621907

epoch: 1, time: 2.3003419240315757 epoch: 2, time: 2.275705337524414 epoch: 3, time: 2.766291300455729 epoch: 4, time: 2.420186996459961 epoch: 5, time: 2.2532145182291665 epoch: 6, time: 2.2998650868733725 epoch: 7, time: 2.2036234537760415 epoch: 8, time: 2.196788787841797 epoch: 9, time: 2.2010008494059243 epoch: 10, time: 2.187331517537435 epoch: 11, time: 2.2036234537760415 epoch: 12, time: 2.220789591471354 epoch: 13, time: 2.212683359781901 epoch: 14, time: 2.1785100301106772 epoch: 15, time: 2.19575564066569 epoch: 16, time: 2.199967702229818 epoch: 17, time: 2.185344696044922 epoch: 18, time: 2.2010008494059243 epoch: 19, time: 2.205928166707357 epoch: 20, time: 2.182483673095703 epoch: 21, time: 2.2145907084147134 epoch: 22, time: 2.2121270497639975 epoch: 23, time: 2.1773179372151694 epoch: 24, time: 2.1779537200927734 epoch: 25, time: 2.211491266886393 epoch: 26, time: 2.208550771077474 epoch: 27, time: 2.2079944610595703 epoch: 28, time: 2.2350152333577475 epoch: 29, time: 2.2062460581461587

epoch: 1, time: 61.35058403015137 epoch: 2, time: 61.138153076171875 epoch: 3, time: 61.8128776550293 epoch: 4, time: 62.176148096720375 epoch: 5, time: 61.774253845214844 epoch: 6, time: 61.570326487223305 epoch: 7, time: 61.92262967427572 epoch: 8, time: 61.562697092692055 epoch: 9, time: 62.568108240763344 epoch: 10, time: 61.948299407958984 epoch: 11, time: 61.9958241780599 epoch: 12, time: 62.254746754964195 epoch: 13, time: 61.658382415771484 epoch: 14, time: 61.74055735270182 epoch: 15, time: 62.14229265848795 epoch: 16, time: 62.26706504821777 epoch: 17, time: 62.210400899251304 epoch: 18, time: 62.166452407836914 epoch: 19, time: 61.6606076558431 epoch: 20, time: 62.3627503712972 epoch: 21, time: 62.04636891682943 epoch: 22, time: 62.5459353129069 epoch: 23, time: 62.721967697143555 epoch: 24, time: 61.945438385009766 epoch: 25, time: 62.49467531840006 epoch: 26, time: 62.131802241007485 epoch: 27, time: 63.31189473470052 epoch: 28, time: 62.065442403157554 epoch: 29, time: 62.64797846476237

epoch: 1, time: 3.2788912455240884 epoch: 2, time: 2.3038387298583984 epoch: 3, time: 2.0197232564290366 epoch: 4, time: 1.9659996032714844 epoch: 5, time: 2.0030339558919272 epoch: 6, time: 2.1047592163085938 epoch: 7, time: 2.841790517171224 epoch: 8, time: 2.615849177042643 epoch: 9, time: 3.9498011271158853 epoch: 10, time: 5.9689680735270185 epoch: 11, time: 5.926926930745442 epoch: 12, time: 2.2862752278645835 epoch: 13, time: 2.2832552591959634 epoch: 14, time: 2.286116282145182 epoch: 15, time: 2.286672592163086 epoch: 16, time: 2.955834070841471 epoch: 17, time: 2.2007624308268228 epoch: 18, time: 1.8773873647054036 epoch: 19, time: 1.8760363260904949 epoch: 20, time: 1.8471876780192058 epoch: 21, time: 1.8825531005859375 epoch: 22, time: 1.8697579701741536 epoch: 23, time: 1.8357435862223308 epoch: 24, time: 1.8857320149739583 epoch: 25, time: 1.9418398539225261 epoch: 26, time: 1.897732416788737 epoch: 27, time: 1.9393761952718098 epoch: 28, time: 1.8698374430338542 epoch: 29, time: 1.8752415974934895

epoch: 1, time: 154.2503833770752 epoch: 2, time: 85.81312497456868 epoch: 3, time: 61.07624371846517 epoch: 4, time: 58.27061335245768 epoch: 5, time: 46.15251223246256 epoch: 6, time: 39.43594296773275 epoch: 7, time: 35.378058751424156 epoch: 8, time: 31.112273534138996 epoch: 9, time: 28.607527414957683 epoch: 10, time: 28.553009033203125 epoch: 11, time: 28.713305791219074 epoch: 12, time: 27.41392453511556 epoch: 13, time: 26.867389678955078 epoch: 14, time: 26.93343162536621 epoch: 15, time: 26.742855707804363 epoch: 16, time: 27.05041567484538 epoch: 17, time: 26.12908681233724 epoch: 18, time: 26.77575747172038 epoch: 19, time: 26.439587275187176 epoch: 20, time: 26.034196217854817 epoch: 21, time: 26.292721430460613 epoch: 22, time: 25.912364323933918 epoch: 23, time: 26.218096415201824 epoch: 24, time: 26.148637135823567 epoch: 25, time: 25.941133499145508 epoch: 26, time: 26.525259017944336 epoch: 27, time: 26.21634801228841 epoch: 28, time: 26.480674743652344 epoch: 29, time: 25.890429814656574

2. 性能趋势对比
我们首先横向比较DP-NBLIST的各算法实现的表现。此处,选用了一个简化场景以避免过多计算,几何形态为[50, 50, 50]的正方体空间,粒子数量为10000,cut-off radius范围为[2, 8, 15],主要使用三类CPU架构算法。
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple Requirement already satisfied: freud-analysis in /opt/mamba/lib/python3.10/site-packages (3.0.0) Requirement already satisfied: scipy>=1.1 in /opt/mamba/lib/python3.10/site-packages (from freud-analysis) (1.11.4) Requirement already satisfied: numpy>=1.14 in /opt/mamba/lib/python3.10/site-packages (from freud-analysis) (1.26.4) Requirement already satisfied: rowan>=1.2.1 in /opt/mamba/lib/python3.10/site-packages (from freud-analysis) (1.3.0.post1) WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv np-500, rc-2 np-500, rc-8 np-500, rc-15 np-1000, rc-2 np-1000, rc-8 np-1000, rc-15 np-5000, rc-2 np-5000, rc-8 np-5000, rc-15 np-10000, rc-2 np-10000, rc-8 np-10000, rc-15 Succesfully get the result of Freud AABB! np-500, rc-2 np-500, rc-8 np-500, rc-15 np-1000, rc-2 np-1000, rc-8 np-1000, rc-15 np-5000, rc-2 np-5000, rc-8 np-5000, rc-15 np-10000, rc-2 np-10000, rc-8 np-10000, rc-15 Succesfully get the result of Freud Cell List!
np-500, rc-2 np-500, rc-8 np-500, rc-15 np-1000, rc-2 np-1000, rc-8 np-1000, rc-15 np-5000, rc-2 np-5000, rc-8 np-5000, rc-15 np-10000, rc-2 np-10000, rc-8 np-10000, rc-15 Succesfully get the result of DP_NBLIST Hash!
np-500, rc-2 np-500, rc-8 np-500, rc-15 np-1000, rc-2 np-1000, rc-8 np-1000, rc-15 np-5000, rc-2 np-5000, rc-8 np-5000, rc-15 np-10000, rc-2 np-10000, rc-8 np-10000, rc-15 Succesfully get the result of DP_NBLIST Cell List!
np-500, rc-2 np-500, rc-8 np-500, rc-15 np-1000, rc-2 np-1000, rc-8 np-1000, rc-15 np-5000, rc-2 np-5000, rc-8 np-5000, rc-15 np-10000, rc-2 np-10000, rc-8 np-10000, rc-15 Succesfully get the result of DP_NBLIST Octree!


此处直接给出三类算法,在颗粒数量为50000,cut-off radius更为密集场景结果,包含CPU和GPU架构。运行平台为CPU: i5-13600kf, GPU: RTX4090, RAM: 64G。

图7 基于Octree近邻搜索算法的性能表现
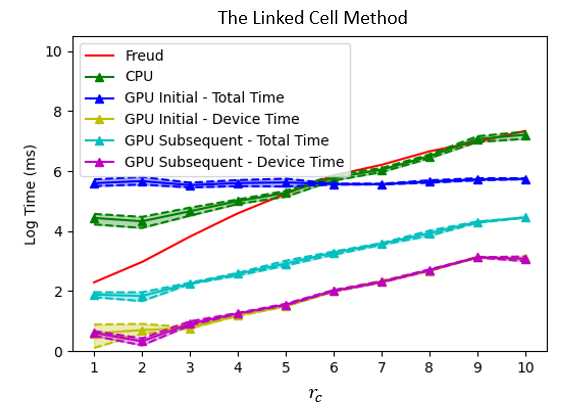
图8 基于Cell List近邻搜索算法的性能表现

图9 基于Hash近邻搜索算法的性能表现
值得注意的是,基于网格的两类方法在较为rc较小时表现不佳,因为此时两类方法均分割了过多的网格(截断半径为1时,网格数量为125000个),对应的处理时间也更长,造成了性能的下降,在计算能力较弱的平台尤为明显。
3. Heatmap对比
我们随后更为详细的比较DP-NBLIST的各算法实现的表现。此处选用场景与之前相同,但粒子数量拓展为[500, 1000, 5000, 10000],比较基准为Freud-AABBTree。


由于Linked Cell算法的表现与Freud-AABBTree近似,我们这里主要给出Octree和Hash算法在更多场景的heatmap结果,包含CPU和GPU架构,以进行进一步分析。此处的heatmap表示各算法实现与Freud-AABBTree算法的性能差异,红色表示相对较慢,蓝色表示相对较快,数值表示相对程度的大小。

图10 基于Octree近邻搜索算法的heatmap

图11 基于Hash近邻搜索算法的heatmap
c. 与DMFF的耦合
此处我们给出一个使用DP_NBLIST辅助DMFF进行水分子模型计算的例子,从准确率和效率两个方面来展示相关结果。
MM Reference Energy: neighbor start cov_map shape: 10000 cov_map shape: 10000 neighbor pair: 0.3018181324005127 秒 (3294600, 2) (1647300, 2) pairs shape: (1647300, 3) neighbor pair: 0.2598240375518799 秒 pairs shape: (1647300, 3)
四、规律总结
基于上述结果,我们给出如下使用准则:
a. CPU架构计算
对于CPU架构,当场景较为稀疏,截断半径较小时,建议使用Octree方法;当场景较为稠密,截断半径较大时,建议使用Hash方法;对于介于前两者的场景,也就是目前大部分仿真问题涉及的场景,建议使用Linked Cell方法。
b. GPU架构计算
对于GPU架构,由于各类算法的时间复杂度均为O(n),各实现的表现非常类似,选择任意算法均可满足需求。
c. 异构计算
对于异构计算,规模较小的问题,适于使用CPU架构及对应的使用准则;对于规模较大的问题,则更适于使用GPU架构及对应准则。
(注意上述总结受到平台计算能力的影响,为各类情况的趋势性总结,更为准确的表现需要进行试算才能确定。)
