基于Transformer网络预测锂电池的老化轨迹
©️ Copyright 2023 @ Authors
作者:
杨凯麒📨
苗嘉伟📨
日期:2023-10-17
共享协议:本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
快速开始:点击上方的 开始连接 按钮,选择 bohrium-notebook:2023-04-07镜像及任意GPU节点配置,稍等片刻即可运行。
主要内容
准确预测锂电池的剩余寿命(RUL)在管理电池健康状态和估计电池状态方面发挥着重要作用。随着电动汽车的快速发展,对预测RUL技术的需求与日俱增。为了预测RUL,本案例中设计了一个基于Transformer的神经网络。首先,电池容量数据通常存在大量噪声,特别是在电池充放电再生过程中。为了缓解这个问题,我们对原始数据进行了去噪自动编码器(DAE)的处理。然后,为了捕获时序信息和学习有用的特征,重构后的序列被输入到Transformer网络中。最后,为了统一去噪和预测两个任务,本案例将其组合到一个统一的框架中。在NASA数据集上的大量实验和与一些现有方法的比较结果表明,本案例中提出的方法在预测RUL方面具有更好的表现。
Transformer是一种神经网络架构,主要用于自然语言处理(NLP)任务,如机器翻译、文本摘要等。它是由Vaswani等人在2017年提出的一种基于自注意力(Self-Attention)机制的深度学习模型。Transformer摒弃了传统的循环神经网络(RNN)和长短时记忆网络(LSTM),利用自注意力机制处理输入序列中的长距离依赖关系。这使得Transformer在处理序列数据时具有更高的并行性和计算效率。此外,Transformer引入了位置编码(Positional Encoding)来捕捉序列中单词的顺序信息。
加载相关的工具包
设置设备类型
载入相关数据
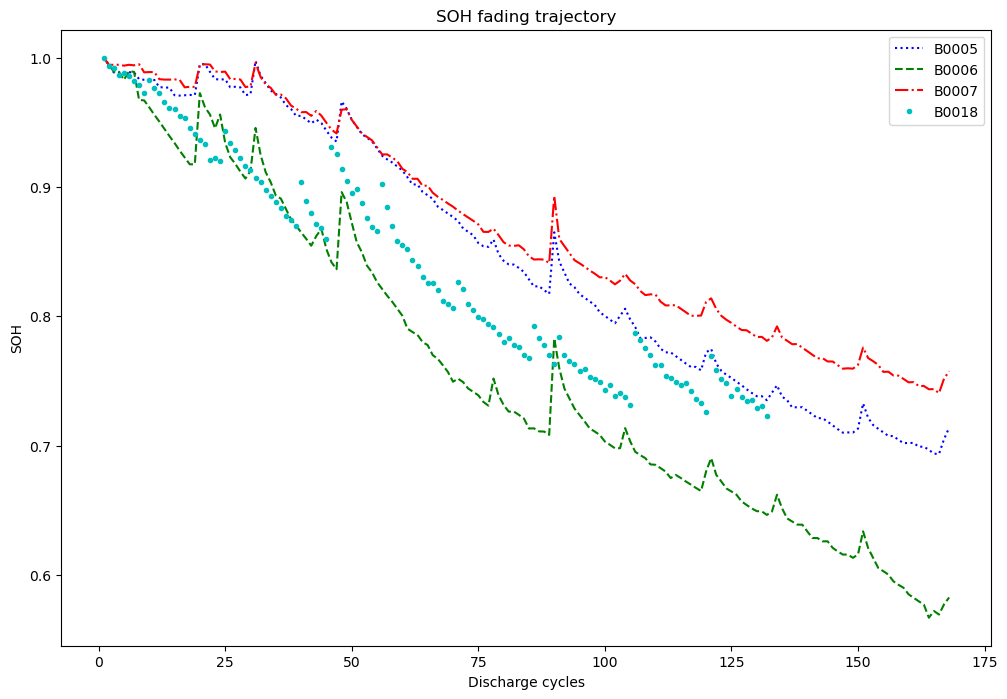
Load Dataset B0005.mat ... 168 Load Dataset B0006.mat ... 168 Load Dataset B0007.mat ... 168 Load Dataset B0018.mat ... 132
绘制四个电池数据的循环-SOH曲线
定义数据处理函数
定义网络结构
定义训练函数
设置超参数并开始训练
seed:0
sample size: 324
Net(
(pos): PositionalEncoding()
(cell): TransformerEncoder(
(layers): ModuleList(
(0): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=24, out_features=24, bias=True)
)
(linear1): Linear(in_features=24, out_features=256, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
(linear2): Linear(in_features=256, out_features=24, bias=True)
(norm1): LayerNorm((24,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((24,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.0, inplace=False)
(dropout2): Dropout(p=0.0, inplace=False)
)
(1): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=24, out_features=24, bias=True)
)
(linear1): Linear(in_features=24, out_features=256, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
(linear2): Linear(in_features=256, out_features=24, bias=True)
(norm1): LayerNorm((24,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((24,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.0, inplace=False)
(dropout2): Dropout(p=0.0, inplace=False)
)
(2): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=24, out_features=24, bias=True)
)
(linear1): Linear(in_features=24, out_features=256, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
(linear2): Linear(in_features=256, out_features=24, bias=True)
(norm1): LayerNorm((24,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((24,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.0, inplace=False)
(dropout2): Dropout(p=0.0, inplace=False)
)
)
)
(linear): Linear(in_features=24, out_features=1, bias=True)
(autoencoder): Autoencoder(
(fc1): Linear(in_features=48, out_features=24, bias=True)
(fc2): Linear(in_features=24, out_features=48, bias=True)
)
)
------------------------------------------------------------------
epoch:200 | loss:0.0072
epoch:400 | loss:0.0012
epoch:600 | loss:0.0008
epoch:800 | loss:0.0007
epoch:1000 | loss:0.0007
epoch:1200 | loss:0.0007
epoch:1400 | loss:0.0007
Epoch 01534: reducing learning rate of group 0 to 4.0000e-04.
epoch:1600 | loss:0.0006
epoch:1800 | loss:0.0006
epoch:2000 | loss:0.0006
Epoch 02081: reducing learning rate of group 0 to 3.2000e-04.
epoch:2200 | loss:0.0006
epoch:2400 | loss:0.0005
epoch:2600 | loss:0.0005
epoch:2800 | loss:0.0005
Epoch 02882: reducing learning rate of group 0 to 2.5600e-04.
epoch:3000 | loss:0.0005
epoch:3200 | loss:0.0005
epoch:3400 | loss:0.0005
Epoch 03491: reducing learning rate of group 0 to 2.0480e-04.
epoch:3600 | loss:0.0005
epoch:3800 | loss:0.0005
Epoch 03847: reducing learning rate of group 0 to 1.6384e-04.
epoch:4000 | loss:0.0005
epoch:4200 | loss:0.0005
epoch:4400 | loss:0.0005
epoch:4600 | loss:0.0004
Epoch 04676: reducing learning rate of group 0 to 1.3107e-04.
epoch:4800 | loss:0.0004
epoch:5000 | loss:0.0004
epoch:5200 | loss:0.0004
epoch:5400 | loss:0.0004
epoch:5600 | loss:0.0004
epoch:5800 | loss:0.0004
epoch:6000 | loss:0.0004
Epoch 06047: reducing learning rate of group 0 to 1.0486e-04.
epoch:6200 | loss:0.0004
epoch:6400 | loss:0.0004
Epoch 06547: reducing learning rate of group 0 to 8.3886e-05.
epoch:6600 | loss:0.0004
epoch:6800 | loss:0.0004
epoch:7000 | loss:0.0004
epoch:7200 | loss:0.0004
epoch:7400 | loss:0.0004
epoch:7600 | loss:0.0004
epoch:7800 | loss:0.0004
epoch:8000 | loss:0.0004
epoch:8200 | loss:0.0004
epoch:8400 | loss:0.0004
epoch:8600 | loss:0.0004
epoch:8800 | loss:0.0004
epoch:9000 | loss:0.0004
epoch:9200 | loss:0.0004
epoch:9400 | loss:0.0004
Epoch 09410: reducing learning rate of group 0 to 6.7109e-05.
epoch:9600 | loss:0.0004
epoch:9800 | loss:0.0004
epoch:10000 | loss:0.0004
epoch:10200 | loss:0.0004
Epoch 10235: reducing learning rate of group 0 to 5.3687e-05.
epoch:10400 | loss:0.0004
epoch:10600 | loss:0.0004
Epoch 10721: reducing learning rate of group 0 to 4.2950e-05.
epoch:10800 | loss:0.0003
epoch:11000 | loss:0.0003
epoch:11200 | loss:0.0003
epoch:11400 | loss:0.0003
epoch:11600 | loss:0.0003
epoch:11800 | loss:0.0003
epoch:12000 | loss:0.0003
epoch:12200 | loss:0.0003
epoch:12400 | loss:0.0003
epoch:12600 | loss:0.0003
epoch:12800 | loss:0.0003
epoch:13000 | loss:0.0003
epoch:13200 | loss:0.0003
epoch:13400 | loss:0.0003
epoch:13600 | loss:0.0003
epoch:13800 | loss:0.0003
epoch:14000 | loss:0.0003
epoch:14200 | loss:0.0003
Epoch 14301: reducing learning rate of group 0 to 3.4360e-05.
epoch:14400 | loss:0.0003
epoch:14600 | loss:0.0003
epoch:14800 | loss:0.0003
epoch:15000 | loss:0.0003
epoch:15200 | loss:0.0003
epoch:15400 | loss:0.0003
Epoch 15426: reducing learning rate of group 0 to 2.7488e-05.
epoch:15600 | loss:0.0003
epoch:15800 | loss:0.0003
epoch:16000 | loss:0.0003
epoch:16200 | loss:0.0003
epoch:16400 | loss:0.0003
epoch:16600 | loss:0.0003
epoch:16800 | loss:0.0003
epoch:17000 | loss:0.0003
epoch:17200 | loss:0.0003
epoch:17400 | loss:0.0003
epoch:17600 | loss:0.0003
epoch:17800 | loss:0.0003
epoch:18000 | loss:0.0003
epoch:18200 | loss:0.0003
epoch:18400 | loss:0.0003
epoch:18600 | loss:0.0003
epoch:18800 | loss:0.0003
epoch:19000 | loss:0.0003
epoch:19200 | loss:0.0003
epoch:19400 | loss:0.0003
epoch:19600 | loss:0.0003
epoch:19800 | loss:0.0003
epoch:20000 | loss:0.0003
------------------------------------------------------------------
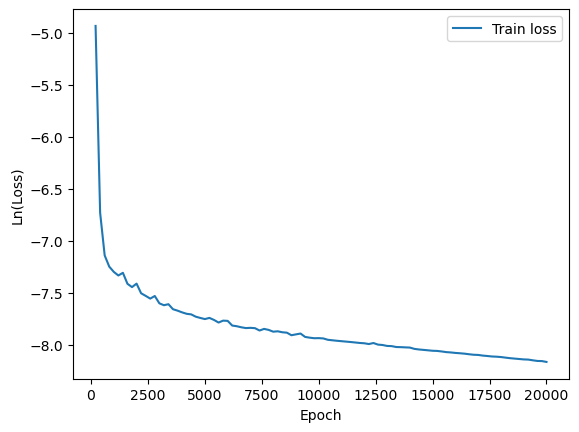
训练误差绘图
对测试集进行预测
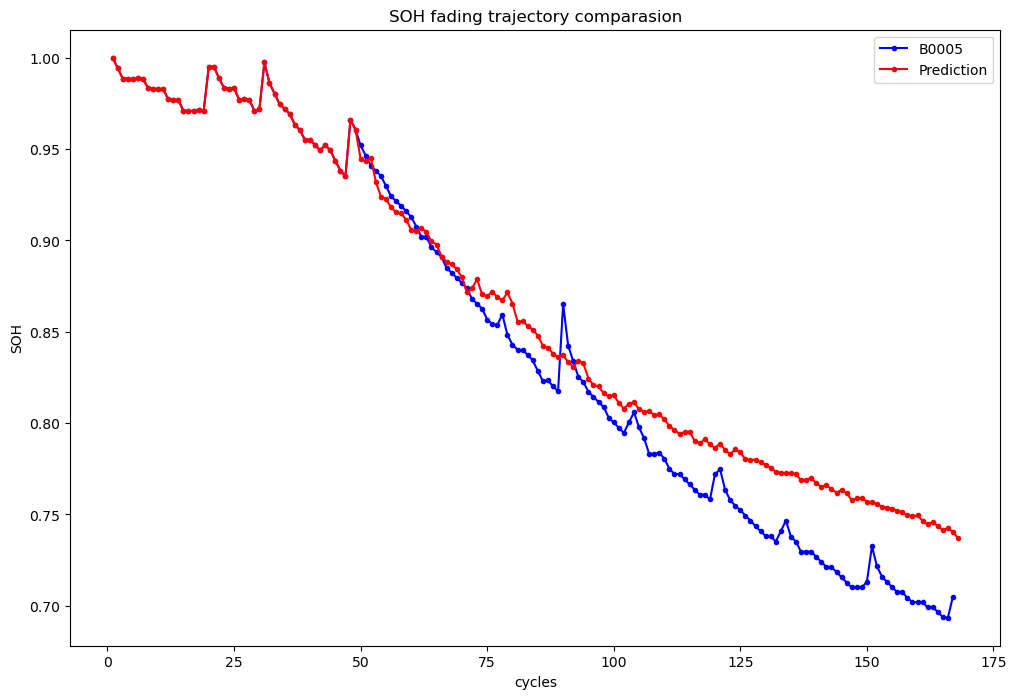
B0005 | RMSE:0.0518
将预测数据和目标曲线作在一张图上比较