


Uni-QSAR
1. 前言
QSAR全称为“定量构效关系(Quantitative Structure-Activity Relationship)”,是一种通过数学模型来描述化合物结构与其生物活性之间关系的方法。QSAR方法已经广泛应用于药物设计、环境毒理学、化学品安全评估等领域。一般来说,QSAR方法主要包括以下步骤:收集和整理活性数据和分子结构信息,选择和提取特征描述符,建立统计模型,验证和评估模型的预测能力。
Hermite平台的Uni-QSAR模块提供了QSAR的功能,您只需提交Smile格式的分子式和分子活性/性质信息,即可方便快速地进行基于机器学习和深度学习方法的QSAR模型构建并获得预测结果。
2. 使用方法
2.1 入口
- 左侧通用菜单栏Menu → Function → Molecule Recommendation → Uni-QSAR。
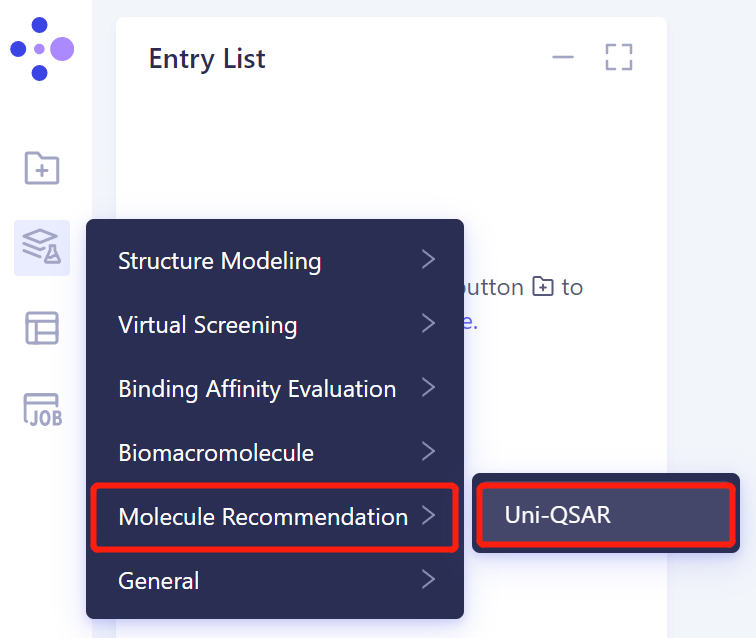
弹出如下界面,选择所需进行的任务类型:
Build Model:建模;
Make Prediction:在已有模型的基础上,对未知数据进行预测。
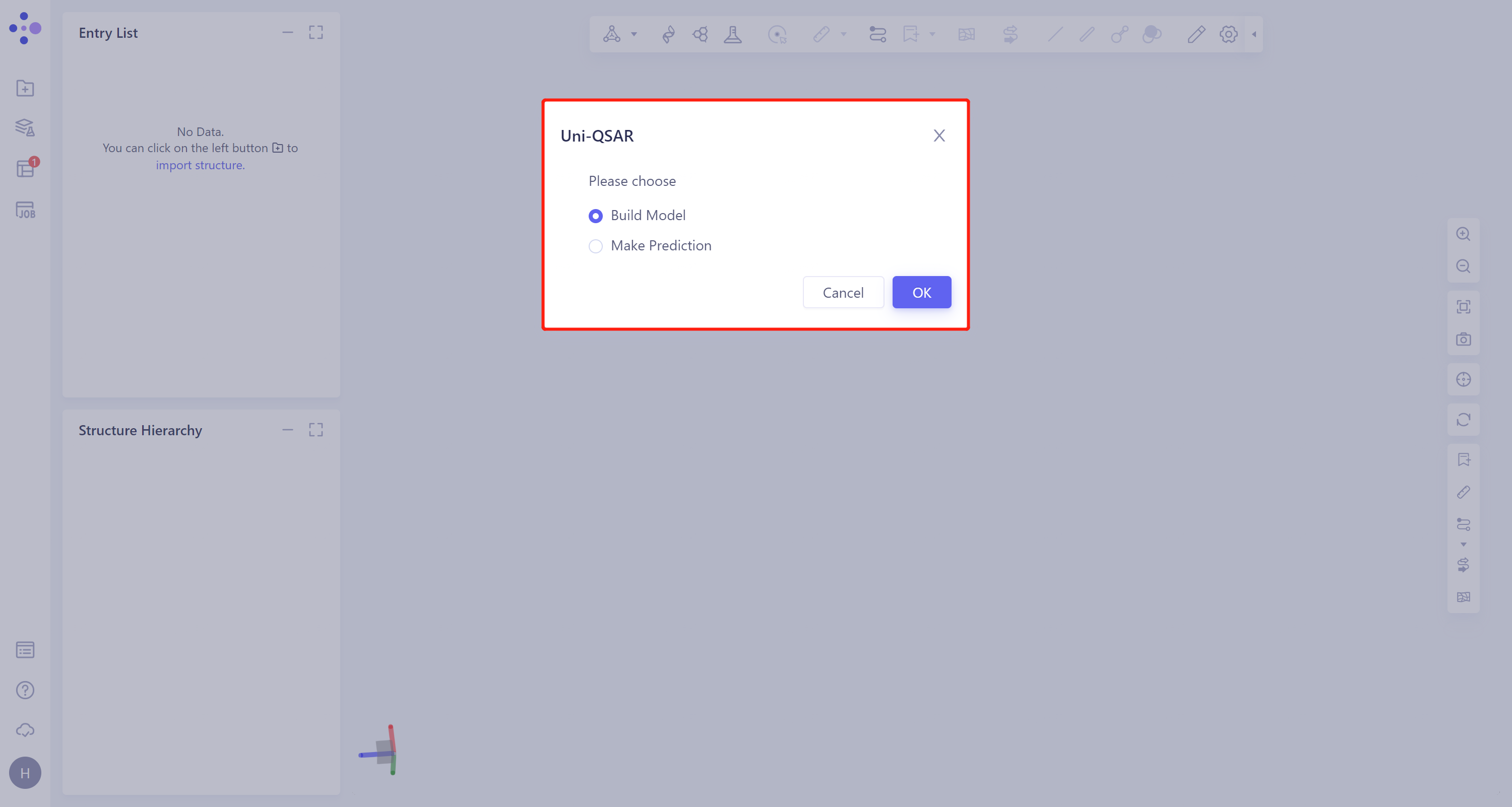
2.2 Build Model
- 右侧出现Uni-QSAR的操作框(红框内所示),整体界面如下:
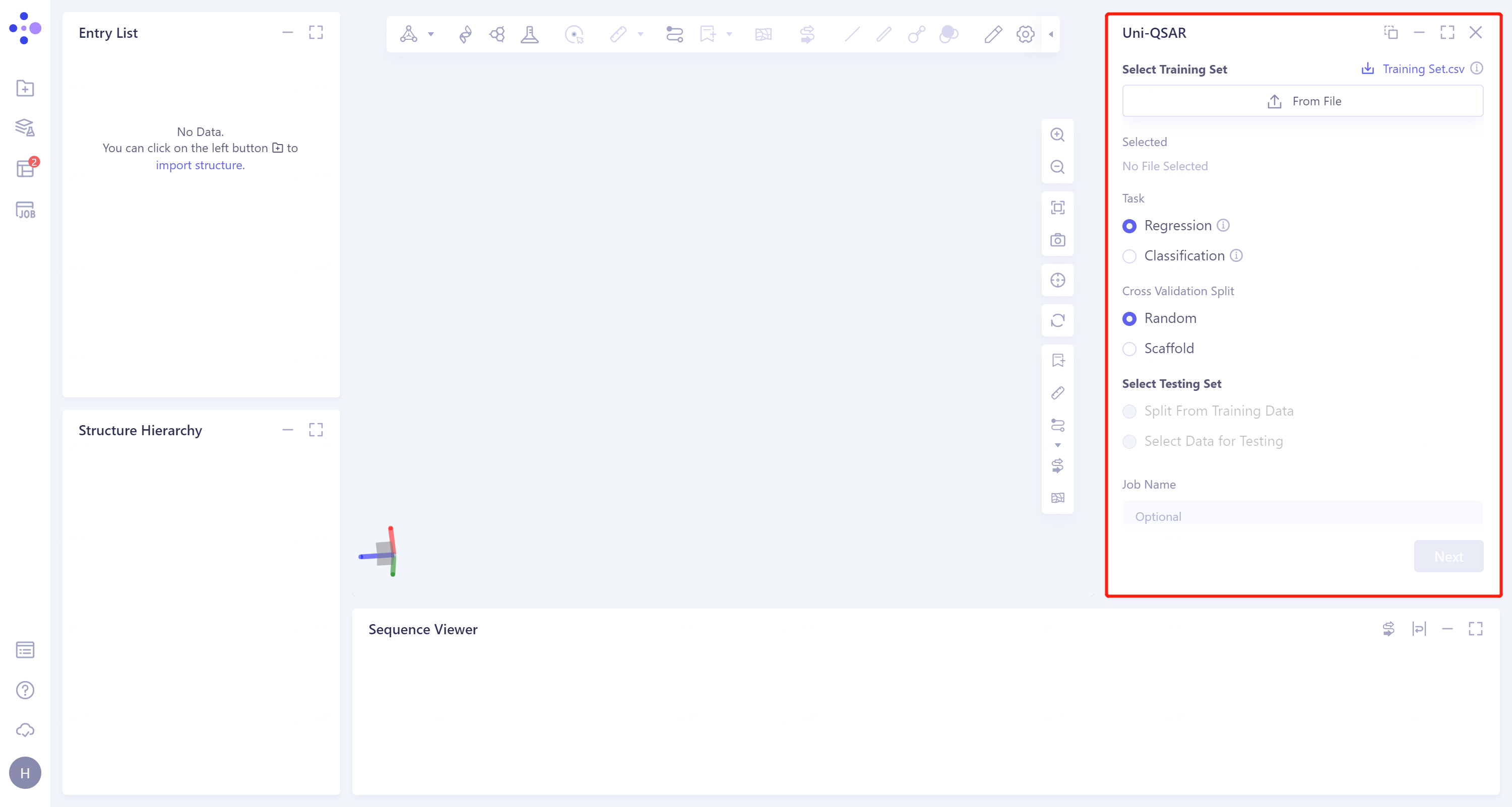
Select Data for Training:选择训练集。需要使用规范化的格式:第一列为ID,第二列为SMILES格式的分子,第三列及以后为目标性质或其他数据。
Task:
Regression:回归任务,当所需预测的性质数据为连续型数据时,勾选该选项。
Classification:分类任务,当所需预测的性质数据为非连续型数据时,勾选该选项。
Cross Validation split:训练集的交叉验证拆分方式。
Random:随机拆分(如下图);
Scaffold:骨架拆分是基于分子的骨架(具有理想性质的基本分子结构)对训练集进行拆分,拆分出的数据集中的分子在结构上更不同(如下图)。
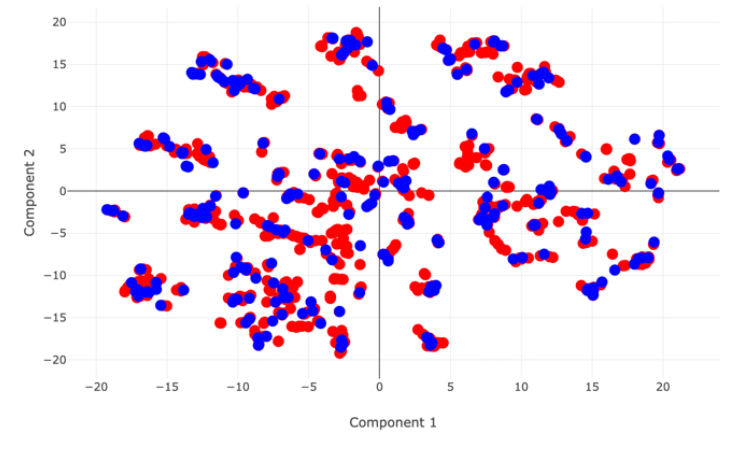 Random split时两个数据集的PCA分布 |
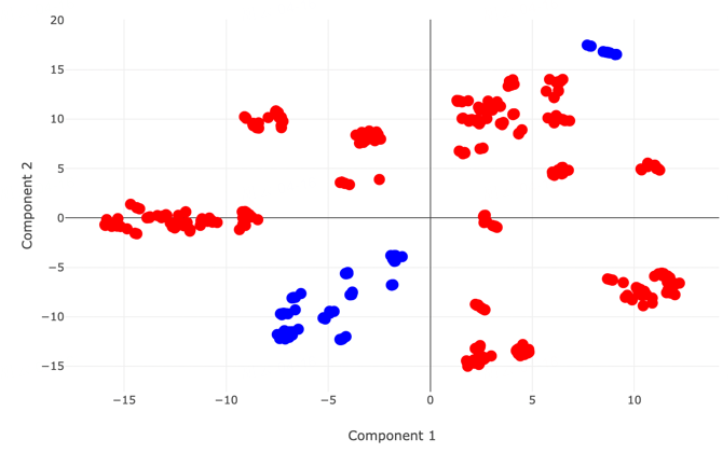 Scaffold split时两个数据集的PCA分布 |
Select Test Set:选择测试集,格式与训练集格式一致,测试集的选择有两种方式:
Split From Training Data:从训练集数据中划分出来一部分用作测试集;
Select Data for Test:上传本地测试集。
Job Name处对该任务进行命名。
Next下一步。
Properties Setting:在该窗口处选择需要进行训练预测的性质;
Calculation:确认计算花费;
Submit提交任务。
2.3 Make Prediction
该步骤根据已训练好的模型预测分子性质。
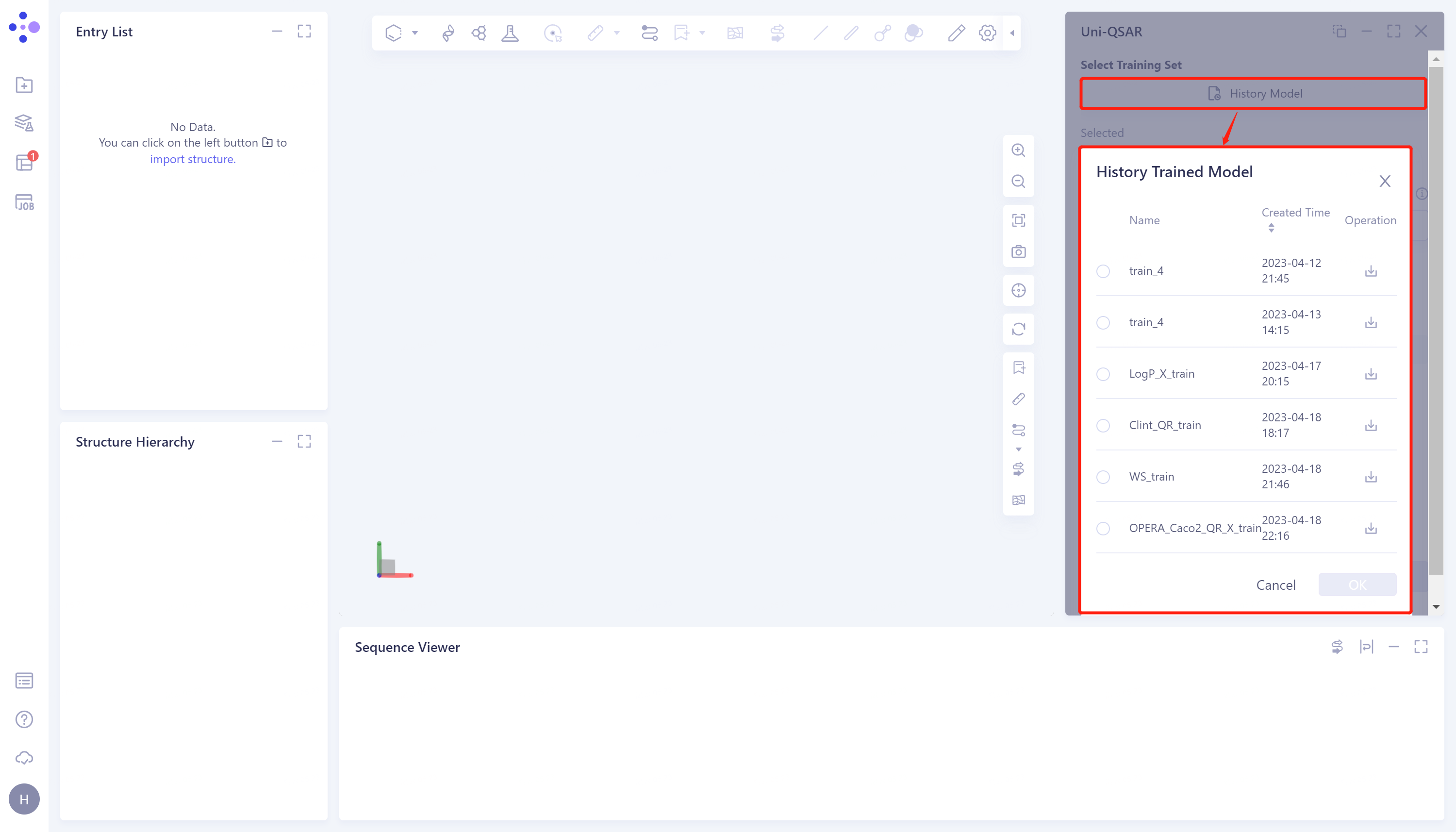
Select Training Set:下方点击History Model上传已训练好的模型。
Select Data for Predicted:下方点击From File上传本地文件,格式与训练集格式一致,但该处的性质需无数据(仅保留列头)。
Job Name处对该任务进行命名。
Submit提交任务。
3. 结果分析
3.1 入口
左侧通用菜单栏Menu Job → 找到所需任务。
- 可以通过搜索Job Name找到该任务,也可以通过Job Type的筛选找到。
3.2 结果展示
3.2.1 Build Model
- 选择需要查看的任务,点击Operation列中的Download下载该任务的结果。
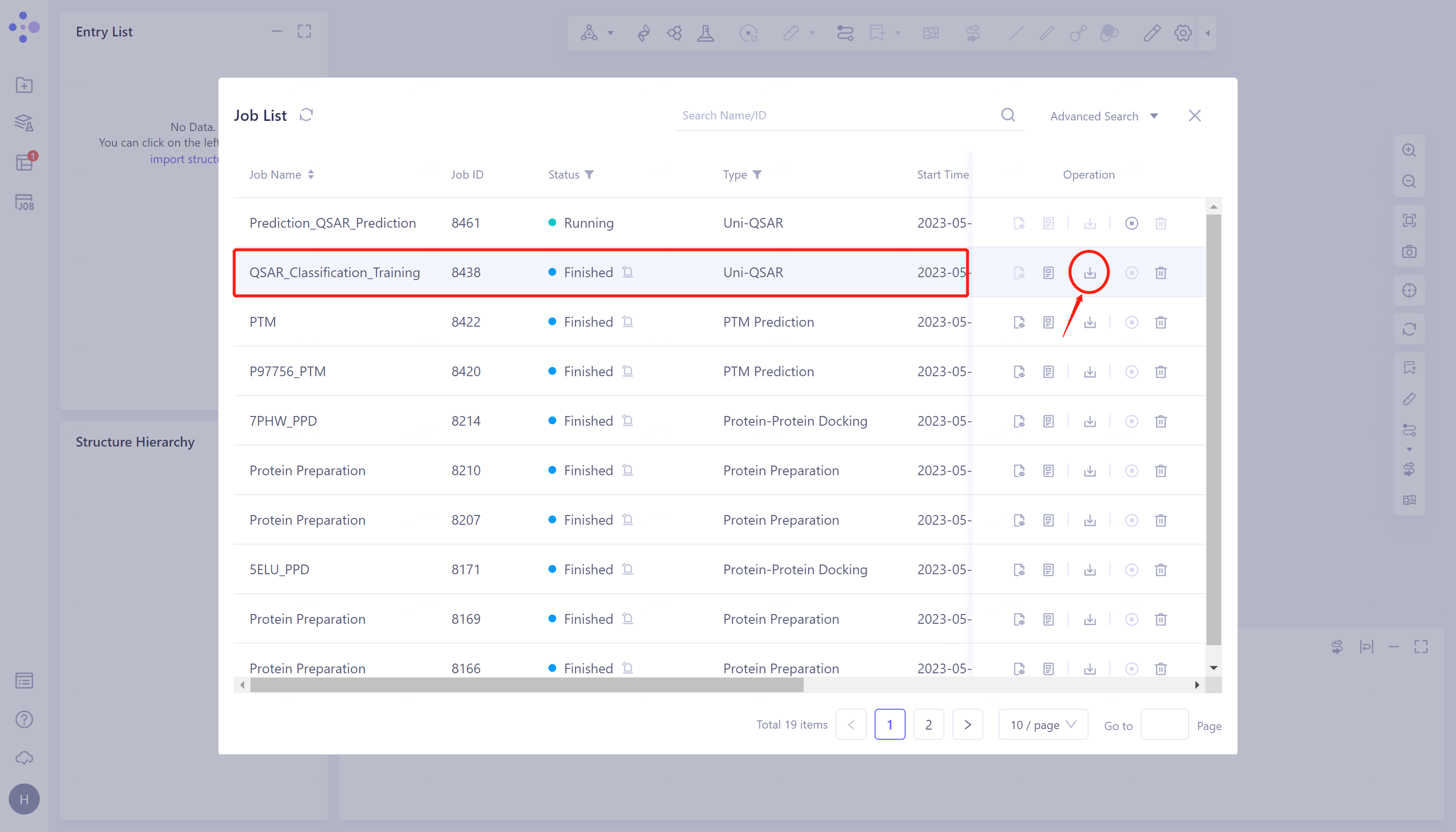
- 下载的为.zip格式的压缩文件包,包含五个文件:训练集数据(training_data.csv)、测试集数据(testing_data.csv)、训练集交叉验证结果文件(validation_metrics_result.csv)、测试集结果文件(teesting_metrics_result.csv)和日志文件(QSAR.txt)。

分类模型评价指标:
AUROC:AUROC(Area Under the Receiver Operating Characteristic Curve)表示分类器能够正确分类正样本和负样本的能力。ROC曲线是以真阳性率(TPR)为纵坐标,假阳性率(FPR)为横坐标,根据分类器的不同阈值画出的曲线。AUROC就是ROC曲线下的面积,取值范围在0.5到1之间,取值越大,分类器的性能越好。当类别均衡时使用 AUROC 较好。
AUPRC:AUPRC(Area Under the Precision-Recall Curve)表示分类器在正例预测上的性能。Precision-Recall曲线是以召回率(Recall)为纵坐标,精确率(Precision)为横坐标,根据分类器的不同阈值画出的曲线。AUPRC就是Precision-Recall曲线下的面积,取值范围在0到1之间,取值越大,分类器的性能越好。当类别极其不均衡时使用 AUPRC 较好。
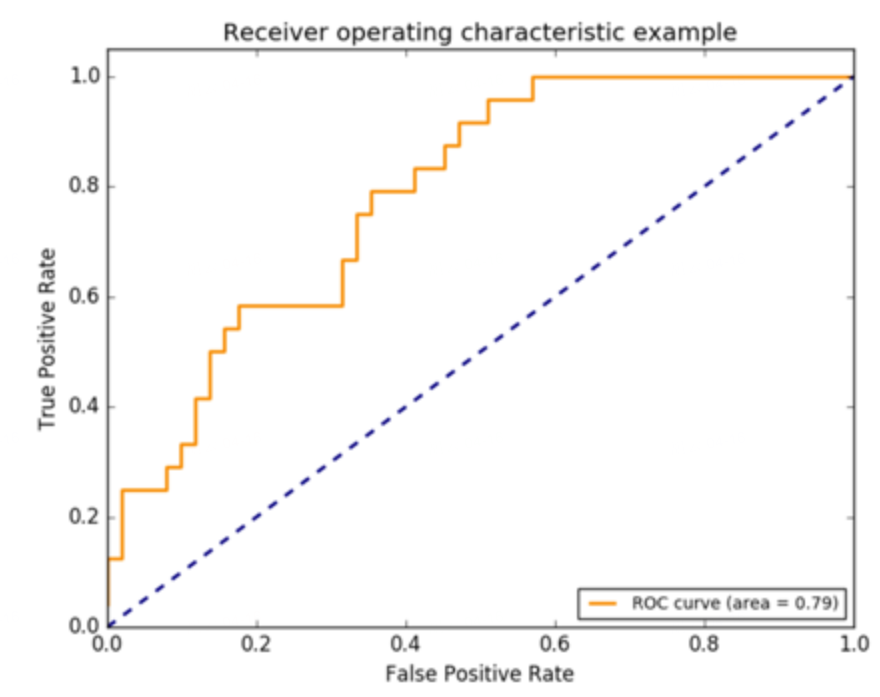
ROC曲线
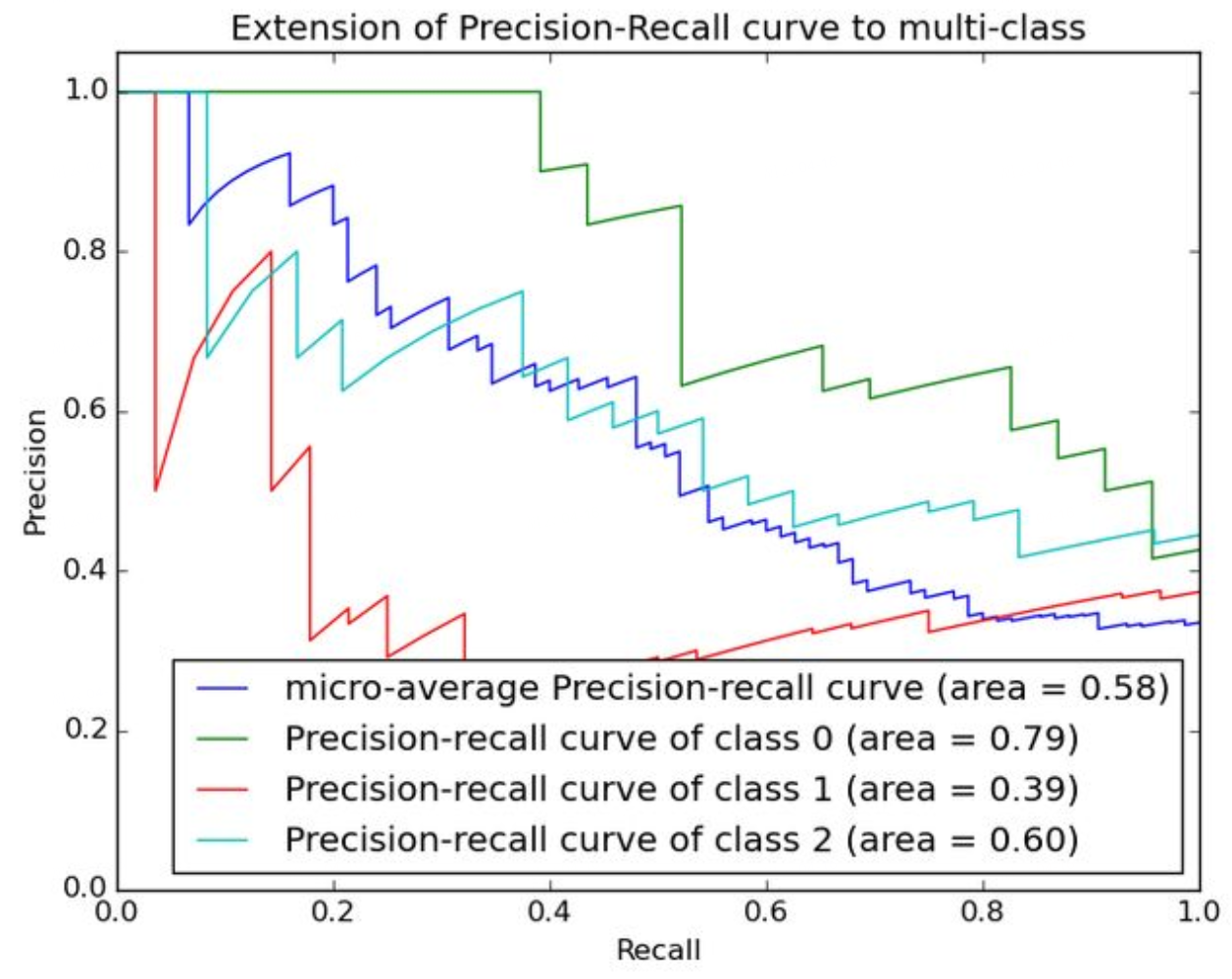
PR曲线
AUC:AUC是Area under curve的首字母缩写,AUC是一个模型评价指标,只能用于二分类模型的评价。AUC就是ROC曲线下的面积,衡量学习器优劣的一种性能指标。
log_loss:对数损失(logistic loss)是对预测概率的似然估计,衡量的是预测概率分布和真实概率分布的差异性,取值越小越好。与AUC不同,logloss对预测概率敏感。
ACC:准确率。
F1 score:
MCC:MCC本质上是一个描述实际分类与预测分类之间的相关系数,它的取值范围为[-1,1],取值为1时表示对受试对象的完美预测,取值为0时表示预测的结果还不如随机预测的结果,-1是指预测分类和实际分类完全不一致。
precision:精确率,查准率,预测的正样本中被正确预测的比例(越大越好)。
Recall:召回率,查全率,正样本中被预测出来是正的比例(越大越好)。
cohen_kappa:kappa系数是用在统计学中评估一致性的一种方法,可用来进行多分类模型准确度的评估,这个系数的取值范围是[-1,1],实际应用中,一般是[0,1],这个系数的值越高,则代表模型实现的分类准确度越高。
f1_bst:同F1_score。
acc_bst:同ACC。
注:TN —— 正确预测为阴性的样品数;TP —— 正确预测为阳性的样品数;FN —— 错误预测为阴性的样品数;TP —— 错误预测为阳性的样品数。
回归模型评价指标:
- MAE:平均绝对值误差,计算每一个样本的预测值和真实值的差的绝对值,然后求和再取平均值。用于评估预测结果和真实数据集的接近程度,其值越小说明拟合效果越好。
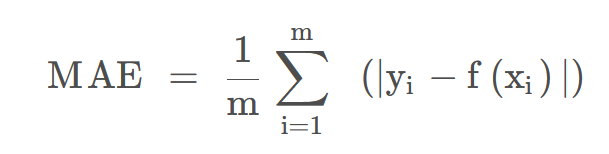
- MSE:均方误差,该指标计算的是拟合数据和原始数据对应样本点误差的平方和的均值,其值越小说明拟合效果越好。
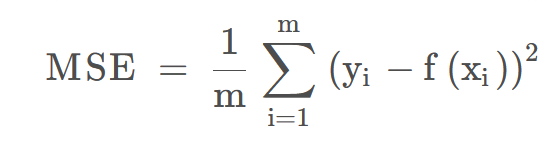
- R²:可决系数,可决系数值一般在0~1之间。越接近于1,说明模型的预测效果越好,越接近于0,说明模型的预测效果越差。
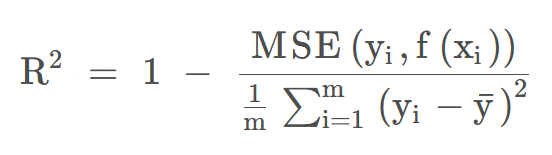
spearmanr:spearmanr的rank相关系数是衡量两个变量之间关联的强度和方向的度量。它是一种非参数度量,用于评估不遵循正态分布的两个变量之间的关系,或者当变量之间的关系不是线性的。spearmanr的取值范围从-1到1,0表示没有相关性,1表示一个完美的正相关,-1表明一个完全的负相关。
pearsonr:Pearson相关系数衡量两个数据集之间的线性关系,范围在-1和+1之间,0表示没有相关性,-1或+1的相关性意味着一种精确的线性关系。
RMSE:均方根误差就是在均方误差的基础上再开方,其值越小说明拟合效果越好。
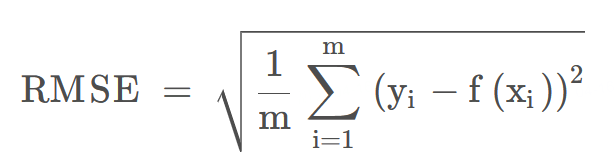
3.2.2 Make Prediction
- 选择需要查看的任务,点击Operation列中的Download下载该任务的结果。
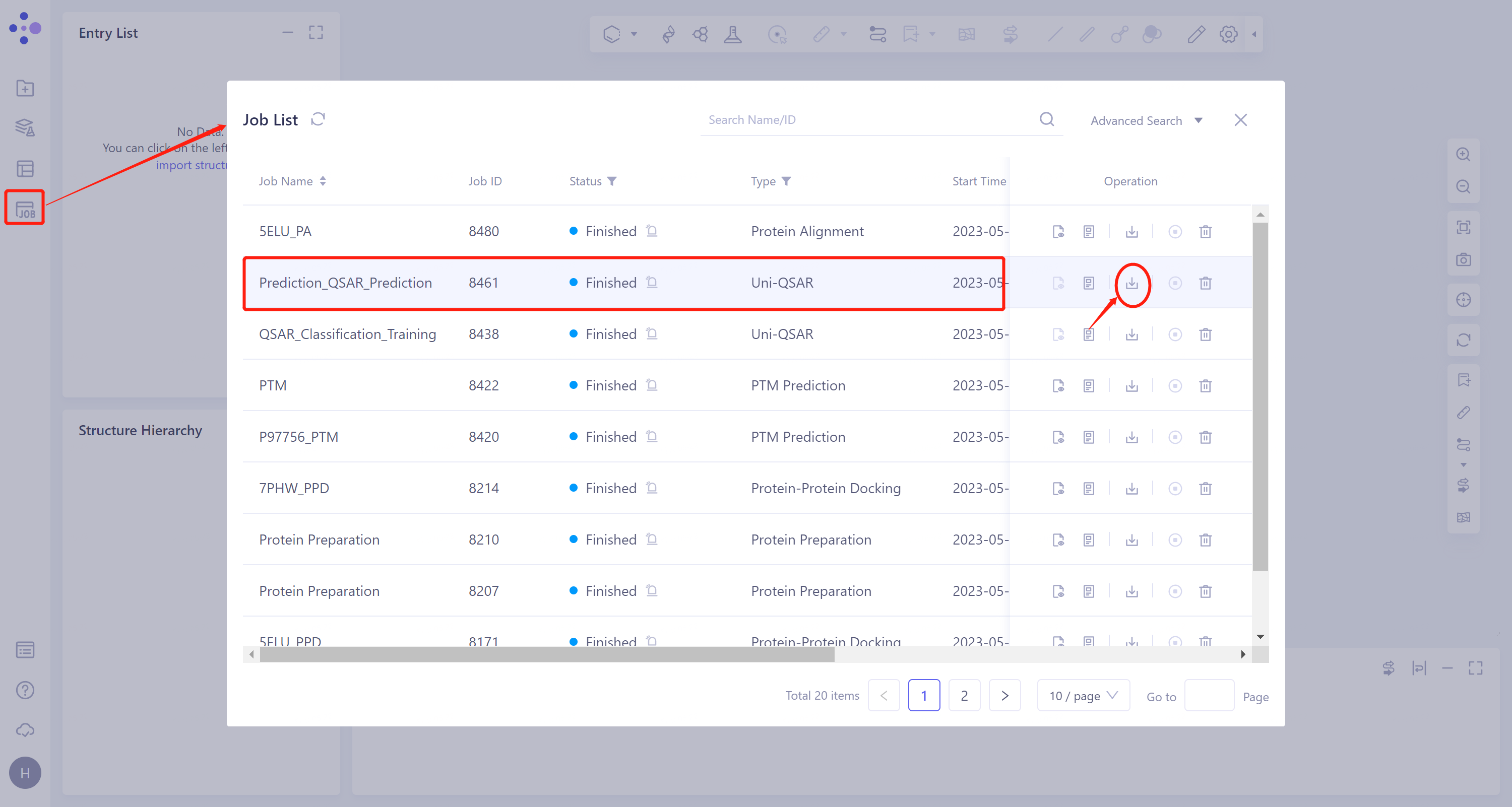
下载的为.zip格式的压缩文件包,包含两个文件:预测结果文件(predicted_data.csv)和日志文件(QSAR.txt)。
- predicted_data.csv文件中,predict_TARGET列记录了提交的分子的性质预测值/分类结果。


