


细看成岭又成峰——分子动力学轨迹的主成分分析

作者: Wentao Guo guowentao@dp.tech
推荐镜像:bohrium-notebook
推荐计算资源:CPU
内容:本教程主要介绍 1.主成分分析(PCA, Principal Component Analysis) 2.通过主成分分析提取动力学轨迹的几何变化信息
使用方式: 您可在 Bohrium Notebook 上直接运行。您可以点击界面上方蓝色按钮
开始连接,选择bohrium-notebook镜像及任何一款节点配置,稍等片刻即可运行。如您遇到任何问题,请联系 bohrium@dp.tech 。共享协议: 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
什么是主成分分析(PCA)?
主成分分析(PCA, Principal Component Analysis)是一种用于分析和简化数据集的统计技术,常用于降低数据的维度。它由卡尔·皮尔逊在1901年发明,是特征分析中最简单的多元统计方法之一。
PCA的核心其实就是两个字:降维.举个简单的例子,当我们在山峰的一侧观察的时候,眼睛(或相机)所接收到的信息就是由山峰投影在二维平面上的画面.这个降低维度的过程往往意味着信息的损耗.苏东坡在游览庐山时曾有感而发:
“横看成岭侧成峰,远近高低各不同”.
后人常对这《题西林壁》诗词进行深入的文学以及哲学分析,但这句话其实非常生动直接地体现了降维这一过程导致的结果:从一个投影面观察庐山时,山脚下不同位置游览者所看到的只能是“岭”或者是“峰”.但庐山的真面目,也就是完整的三维信息,即不仅仅是“岭”,也并不仅限于“峰”.
这里就自然而然的引发了一个有趣的思考:有没有一种观察角度,让我能以二维的形式,最大程度地获取庐山三维的信息呢? 看到这里的你其实已经充分理解了主成分分析的核心思想: 将原始高维数据投影至低维子空间数据的同时,最大程度地保留(与任务相关的)数据的信息 这种投影所基于的就是数据中最重要的特征,这些特征被称作主成分(PC, principal compotens),它们代表着原始数据中变化最大的方向.直观理解,主成分分析即是通过数学来抓取数据的特征,找到主成分(们)以便于后续的对数据进行操作和分析.
回到庐山的例子,根据主成分的信息,我们期待找到一个最好的观察庐山的(投影)角度 —— 在这个方向上我所看到的庐山的投影,能让我即看到“岭”,又看到”峰“,甚至能够在量化的角度上去描述庐山更像”岭“还是更像”峰“.
下面让我们一起欣赏一下庐山的3D建模图,你有没有发现从正面来看确实是长长山岭,而从侧面看就是险峻的山峰了?
如何实现主成分分析(PCA)?
作为一种重要的数据处理以及分析手段,很多学科都把主成分分析(PCA)作为必修内容,尤其以数学、数据驱动专业(统计学、计算机科学、数据科学等)为背景的同学想必对这一概念已了然于胸.由于其强大的普适性和直观性,主成分分析的功能在很多程序语言中都被打包为可直接调用的工具(比如python中的sklearn,R中的PCA功能).
下面我们会以公式和python代码结合的形式来对葡萄酒数据进行主成分分析,以帮助不熟悉的同学快速地理解主成分分析的具体操作.在这个过程中我们会使用sklean自带的wine数据集,通过对不同环境下产生的三种葡萄酒信息进行降维,以观察他们在13个属性上的差异(酒精浓度、苹果酸浓度、颜色强度、色调、脯氨酸浓度等).除了这13个属性外,数据中还保留了每一瓶酒的类别,我们会通过不同的颜色来区分这三类酒.该数据集中包含178瓶酒(样本)的信息.
样本数目为: 178 变量数目为: 13
数据载入后,我们还需要一些前处理(preprocess)操作:标准化每个变量,使他们的均值为0,方差为1.
对数据的预操作(如归一化,标准化)可以使后续数据的分析更好.在PCA的任务下,标准化可以帮助我们解决:
- 量纲问题:数据集中的各个特征可能具有不同的单位和量纲,如长度单位可能是米、厘米等,重量单位可能是千克、克等。这些不同的单位在进行PCA时可能会导致某些特征对结果的影响过大。通过标准化,我们可以消除这种量纲带来的影响,使得各个特征具有相同的尺度。
- 方差问题:不同特征的方差可能差别很大,如果不进行标准化处理,那么方差较大的特征将主导PCA的结果,导致方差较小的特征被忽略。标准化后,所有特征的方差都变为1,从而避免了这个问题。
- 性能问题:标准化后的数据更容易满足很多算法(如梯度下降法)的假设和要求,从而能够提高模型的性能。
- 效率问题:标准化后的数据分布更为集中,有利于提高计算效率,加快PCA的计算速度。
我们首先引入方差的概念以帮助大家定量化地理解什么是“信息量”
在PCA中,信息量就是数据的多样性。比如对于一个全中国大学生的数据集合,数据集中第一个变量为大学生的年龄,第二个变量为大学生的高考分数.显然,我们能在第二个变量中获得的更多的信息量,因为大学生年龄相似(数据分散性小),但是高考分数不尽相同(数据分散性大)。
回到方差,我们从一维(单一变量)数据开始并逐渐拓展到多维(多变量)数据.
根据定义,我们可以通过求数据点与平均值的差的平方的均值来计算一维数据的方差(variance):
但是根据我们的预处理操作,数据标准化后,因为平均值被平移至0,数据的方差也被标准化为1,那么对于每一个变量来说:
其中n为样本的总数,在这个例子中,
为了描述不同之间变量的相关性,我们这里引用协方差(covariance)来描述:
根据定义,每一对变量(这里以变量,为例,你可以想象为酒的酸度和甜度)的协方差计算公式:
方差是协方差的一种特殊情况,即当两个变量是相同的情况。
那么为什么分母从变成了呢?简单来说,当前个值可以自由地放飞自我的时候,最后一个,也就是第个值必须老老实实地配合前个值来满足均值的前提要求.因此第个数据没有信息量,它由前个值和均值所决定,如果我们除以而非,那么方差/协方差会比样本真实的情况偏小,当样本较大时,我们会将近似为.这其中其实暗含“有偏”和“无偏”的概念,感兴趣的朋友可以点击超链接自行探索.
那么怎么储存每一对协方差信息呢?这里我们利用协方差矩阵来表示:
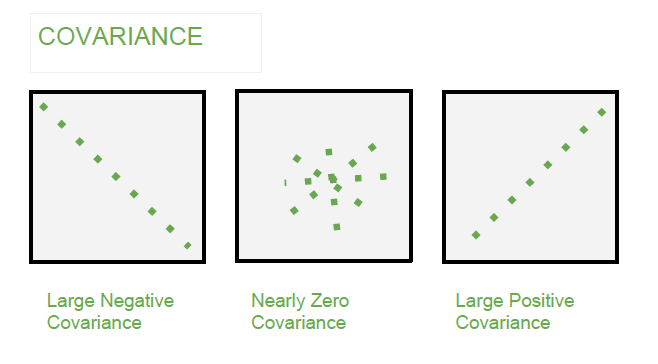
如果两变量的协方差为0,那么意味着他们线性不相关(正交),协方差的绝对值越大,说明两变量的线性相关性越强(如下图)
为了让主成分,也就是新变量能够保留更多的原始信息,我们需要主成分之间的线性相关性尽可能小.为了让降维后变量的线性相关性尽可能小,我们需要让每对不同变量的协方差为0,即让他们相互正交.那么现在我们的目标就变得更加清晰:我们需要通过一种变换方式令数据的协方差矩阵除对角以为的其他元素化为0,即矩阵对角化,从而得到新的主成分(们).
协方差矩阵的形状 (13, 13)
下面就是见证奇迹的时刻——我们会将协方差矩阵的对角化
假设我们新的协方差矩阵为,原方差矩阵为,投影前的矩阵为,投影后的矩阵为,那么:
根据协方差矩阵的表达式,我们可以得知它是一个实对称矩阵(以主对角线为对称轴,各元素对应相等的矩阵,根据),因为方差/协方差非负.根据线性代数,实对称矩阵具有一个非常重要的特性:一个行列的实对称矩阵一定可以找到个正交特征向量,而这些特征向量通过堆叠组成矩阵,而则是一个对角化的矩阵.根据上面的公式,我们可以自然而然的联系和.因此,我们将协方差对角化的问题转化为对的特征值分解问题.通过求解协方差矩阵的特征值(对角元素)与特征向量(P)来得到新的成分.
注意操作到这里的时候我们只是把原变量线性变换为相互正交的变量(成分),并没有确定哪些是更重要的变量(主成分).
特征值的数目: 13 特征值: [0.10396199 0.16972374 0.22706428 0.25232001 0.29051203 0.35046627 0.55414147 0.64528221 0.85804868 0.92416587 1.45424187 2.51108093 4.73243698] 特征向量矩阵的形状: (13, 13)
之后,我们将特征向量按其对应的特征值从大到小排列.
排序后的特征值: [4.73243698 2.51108093 1.45424187 0.92416587 0.85804868 0.64528221 0.55414147 0.35046627 0.29051203 0.25232001 0.22706428 0.16972374 0.10396199]
那么特征值怎么能够代表特征向量对于协方差大小的贡献呢?
根据矩阵乘法的定义,我们知道:
在这个过程中,运算可以被看作是一种投影,即将二维矩阵的每一个元素变换到以向量所代表的空间去,而C即是投影的结果.在这个过程中,只要A比B的维度小,那么投影出的C便实现了对B的降维.而C中元素值的大小就是将B投影后的标量大小.当我们在对角化协方差矩阵的时候,其中矩阵乘法的部分恰恰符合投影的思路——协方差矩阵投影后,标量越大的特征值对应着特征向量的方向方差越大.
假设我们的特征值为,特征向量为,总方差为,那么满足:
在我们的例子中总方差为
同时,我们用更通用的解释方差explained variance来度量数据集中多少变化可以归因于每个主成分(特征向量).
根据特征值的大小,我们将提取最靠前的K个特征向量(主成分!)以构成投影的子空间.
为了能够直观的看到降维后的数据,我们选择维度=2,也就是保留特征值第一大和第二大的特征向量.
特征值的和: 13.073446327683616
我们将提取最靠前的K个特征向量以构成投影的子空间.为了能够直观的看到降维后的数据,我们选择维度=2,也就是保留特征值第一大和第二大的特征向量
通过绘图我们可以可视化对样本变量降维的结果.

图一是根据前三个变量(酒精浓度、苹果酸含量、含灰量)画出的所有样本分布,可以看出三种酒之间并没有明显的边界,但在空间上它们的确有所区分.
如果将数据直接投影在两种变量空间上:如图2酒精浓度和苹果酸含量,图3酒精浓度,含灰量,我们可以发现在牺牲其他维度信息后,数据的特征几乎完全不能够被保留.
图四则是将样本投影在第一特征向量(主成分PC1)和第二特征向量(主成分PC2)的数据结果.可以看出在方差最大(PC1)和第二大(PC2)方向的投影下,样本的信息被保留的很好——三种酒在空间中的分布区域有着明显的分别.通过这一过程,高维的样本信息通过有效压缩被三维生物(我们)直观地感受.
除此以外,我们还可以通过分解所得到的特征向量和特征值得到其他信息:
- 特征值决定了解释的总方差的比例:所有特征值的总和表示数据集中的总方差。每个特征值与特征值总和的比例表示由相应主成分解释的总方差的比例。
- 特征向量决定了数据集的坐标系,排在最前面的特征向量给出了样本数据变化最大的方向
- 特征向量提供了对特征重要性的洞察:特征向量包含原始特征的系数们,而这些系数的大小可以指示每个特征对主成分的贡献或重要性.
下面让我们看一看主成分的具体形式,以观察我们如何对于原始特征进行重构,以及特征值们对原数据方差的描述占比,并观察特征值的累积贡献度.
第1的主成分为: [-0.1 0.5 0.2 -0. -0.3 -0.2 0.1 -0.4 0.5 0.2 0.2 0.3 0. ] 方差描述占比: 0.36 第2的主成分为: [ 0.2 0.2 -0.1 0.5 0. -0.5 -0.4 -0.1 -0.1 -0.3 -0.1 -0.1 0. ] 方差描述占比: 0.19 第3的主成分为: [ 0. 0.3 -0.6 -0.2 -0.1 -0.2 0.1 0.2 -0.3 -0. 0.5 0. -0.1] 方差描述占比: 0.11 第4的主成分为: [ 0.2 -0. -0.6 0.1 0.1 0.1 0.3 -0.4 0.2 0.1 -0.5 0.1 0.1] 方差描述占比: 0.07 第5的主成分为: [-0.1 0.3 -0.1 -0.4 0.7 -0. -0.3 0.2 0.3 0.1 -0.1 -0.1 0.1] 方差描述占比: 0.07 第6的主成分为: [-0.4 0.1 -0.1 0.2 -0.1 0.1 0. 0.4 0.3 -0.3 -0.3 0.3 -0.5] 方差描述占比: 0.05 第7的主成分为: [-0.4 -0. -0.2 0.2 -0.1 0. 0.1 0.2 0. -0.2 0. 0. 0.8] 方差描述占比: 0.04 第8的主成分为: [ 0.3 0. -0.2 -0.2 -0.5 0.3 -0.6 0.2 0.2 0.2 -0.1 -0. 0.1] 方差描述占比: 0.03 第9的主成分为: [-0.3 0. -0.1 0.4 0.1 0.5 -0.4 -0.4 -0.2 0.1 0.2 0.1 -0.1] 方差描述占比: 0.02 第10的主成分为: [ 0.1 0.5 0.1 0.1 -0.1 0.4 0.2 0. 0.1 -0.3 -0. -0.6 -0. ] 方差描述占比: 0.02 第11的主成分为: [-0.3 -0.3 -0.1 -0.4 -0.2 -0.1 -0.2 -0.4 0.1 -0.5 0. -0.3 -0.1] 方差描述占比: 0.02 第12的主成分为: [-0.4 -0.2 -0.2 0.2 -0.1 -0.3 0. 0.1 0.1 0.5 -0. -0.6 -0.2] 方差描述占比: 0.01 第13的主成分为: [-0.3 0.4 0.1 -0.2 -0.2 -0.1 -0.1 -0.1 -0.6 0.2 -0.5 0.1 0. ] 方差描述占比: 0.01

特征向量里面的值表示该特征向量在原始数据空间的坐标轴上的投影,以及原始数据特征是如何通过线性组合构成其对应的特征。例如PC1的值为
从这组数中我们可以得到信息:第一主成分中不包含第4和第13个变量(他们的系数为0),相对地,有一些变量具有较大的权重,如第2个(0.5),和第9个(0.5).因此,我们可以通过特征向量来识别那些特征在这一主成分有更大的权重和贡献.
可以看出由上到下对数据分散性的描述比率逐渐减小至0.01.除此以外,只需要前五个特征向量的信息,就可以描述数据百分之八十的特征.
值得一提的是,PCA可以通过不同的角度理解,如投影、重构、可区分、旋转坐标系等.笔者选择了一个易于理解、拆分的角度来分步介绍.这里我们也提供一些优质的PCA相关科普,感兴趣的读者可以参考๐•ᴗ•๐:
算法理论02 主成分分析PCA: https://zhuanlan.zhihu.com/p/343182129 【机器学习】降维——PCA: https://zhuanlan.zhihu.com/p/77151308
如何通过主成分分析(PCA)分析分子轨迹数据?
场景一:分子结构变化
分子的运动轨迹可以看作是一个非常典型的高维数据场景.在分子动力学模拟中,分子内的每一个原子都被其在x,y,z三个方向上的坐标所表示.那么对于一个含N个原子的分子来说,每个原子都可以在x,y,z三个维度上移动,那么对于整个分子来说,它的总自由度(degree of freedom)为:
对于化学场景来说,我们更关注分子的变化,那么这时我们可以将平移、转动这种并不会改变分子整体结构和能量的自由度(我们也称之为约束)去除,以下公式表示:
其中F表示自由度的数量,N表示原子数,D表示分子中的约束数。
因此,轨迹处理的第一步就是通过计算质心的位移和转动角动量来移除分子整体的平移和转动部分,从而只关注分子结构的变化.
对于非线性分子,我们需要扣除三个方向的平动和转动,因为他们并不会改变分子的内部结构(3N-6),。而对于线性分子,他们只有两个转动自由度的约束(3N-5).分子自由度的数量对于描述和理解分子的行为和性质非常重要.这里暗含一些分子信息的等变性与不变性,感兴趣的朋友一键直达BN*当我们说起神经网络的等变性,我们在谈论什么*
拿简单的乙醇分子()来说,虽然结构简单,但是它的总自由度为,扣除约束的自由度为,这意味着在分子的轨迹每一帧中(frame),这一样本有含有>20维信息.对于柔性大体系运动轨迹(如蛋白模拟),轨迹数据的信息量非常大.通过主成分分析,复杂的反应轨迹可以被降维,保留结构随时间变化的主要成分,并去除非关键原子的移动(也可想象为噪声),从而帮助研究人员更好的了解有机化学、生物化学等分子结构变化的和运动行为.
下面让我们实践一个简单反应的主成分分析过程——丙二醛的分子内氢转移过程(来源: Chem. Sci.,2019, 10, 9954)).
下图是轨迹的内禀反应坐标(intrinsic reaction coordinate,由福井谦一提出)——从过渡态(反应需要跨越的能垒结构)以固定步长沿梯度下降方向到达两侧反应物和产物的连续轨迹.
图中灰色的大球代表C原子,红色的大球代表O原子,而白色的小球代表H原子.

首先我们需要读入轨迹文件 malonaldehyde_IRC.xyz 分子轨迹xyz文件是一种常见的文件格式,用于存储和表示分子模拟或实验的分子结构和动力学轨迹数据。该文件以文本形式存储,通常使用.xyz作为文件扩展名。
分子轨迹xyz文件的基本结构如下:
- 第一行是一个整数,表示分子中原子的数量(N)。
- 第二行是一个注释行,可以包含有关该轨迹的额外信息,如模拟时间、温度等。
- 从第三行开始,每行包含一个原子的信息,按照特定的格式排列。每行包括四个字段:原子名称、原子的x坐标、原子的y坐标和原子的z坐标。
--2023-07-24 12:41:47-- https://dp-public.oss-cn-beijing.aliyuncs.com/community/malonaldehyde_IRC.xyz Resolving ga.dp.tech (ga.dp.tech)... 10.255.254.37, 10.255.254.18, 10.255.254.7 Connecting to ga.dp.tech (ga.dp.tech)|10.255.254.37|:8118... connected. Proxy request sent, awaiting response... 200 OK Length: 13725 (13K) [chemical/x-xyz] Saving to: ‘malonaldehyde_IRC.xyz.1’ malonaldehyde_IRC.x 100%[===================>] 13.40K --.-KB/s in 0.04s 2023-07-24 12:41:47 (364 KB/s) - ‘malonaldehyde_IRC.xyz.1’ saved [13725/13725]
下面我们将使用sklearn的PCA功能对轨迹数据(xyz文件)进行主成分分析.注:如果你已有GROMACS或其他分子动力学package跑出的轨迹(包含拓扑信息,可被mdtraj读取,如h5文件),则可以直接调用python的mdtraj package丝滑PCA.考虑到本文的篇幅以及科普的重心为PCA及其在动力学轨迹中的代表场景,我们不会在本篇详细介绍这些package如何使用.为了让读者有更好的体验,我们将推出其他BN来实例化如何以Bohrium为平台,通过不同力场工具生成分子动力学轨迹并调用常见的python功能包来进行轨迹的数据分析. ๐•ᴗ•๐
第一主成分方差描述占比: 0.9392176170862856 第二主成分方差描述占比: 0.05972972785437694


从图中我们可以看出,第一主成分(PC1)描述了93.9%的方差,而PC2占6.0%。由于这些成分捕获了反应过程中几何变化99%以上的总方差,因此我们的可以得到结论——重要的分子运动信息成功被这个二维子空间捕获(由于我们并没有祛除转动和平动的自由度,原来的空间根据总自由度的计算公式为维!)。为了更好的观察主成分所代表的原子运动,原文作者根据PC1和PC2特征向量重构分子的三维结构(PathReducer通过将PC转换回全维空间来生成分子几何的笛卡尔坐标,从而用PC重建结构,详情请点击原文链接),并将最大的两主成分根据当前帧和下一帧的变化,将原子运动方向投影回结构上,我们将会观察到这样的结果:

最重要的主成分(PC1)对应于H原子在两个O之间的运动以及两个C–C键的交替单键和双键特征。第二个最重要的主成分(PC2)主要对应于O的向内运动.因此,我们能够得知在H转移反应的过程中,H的位移为主体,约占93%,与此同时,两侧氧原子和氢原子的前后振动移动占比约6%,体现在左右两侧的氧原子先靠近,后远离的运动特征.同时我们也捕捉到了H原子在分子平面外的抛物线转移轨迹.
如果我们不使用PCA的主成分而是仅仅根据“经验主成分”——两侧O-H键的长短变化——来描述这一转移过程的话,我们会得到:

恭喜你!经过场景一你已经实现了对于简单分子结构变化轨迹的主成分分析,达成了“小试牛刀”的成就!
在下一个场景中,让我们一起level up,感受一个更加复杂,更特别,也更小众的化学场景
场景二:动力学效应
除了在反应轨迹、柔性大体系的分子轨迹中的应用外,主成分分析也适用于涉及动力学效应的有机反应轨迹的分析.
那么什么是 动力学效应(dynamic effect) 呢? 我们要先从传统过渡态理论谈起——
根据过渡态理论(Transition State Theory, TST,参考文献见附录),在化学反应进行过程中,反应物分子通过克服能垒的方式,经过过渡态形成新的化学键和解离旧的化学键,最终转变为产物。一般来说,过渡态结构代表单步或单位反应的结构变化.下图是一个二维的示意图:
 而我们刚刚经历过的场景一就是一个典型的越过能垒,H从左侧传递到右侧的过程.
而我们刚刚经历过的场景一就是一个典型的越过能垒,H从左侧传递到右侧的过程.
然而根据我们之前的介绍,分子的变化实际上是一个高维场景,三维势能面比二维势能线能更好地描述反应如何根据能量变化.
为了更好的理解过渡态理论和势能面,我们下面会通过两个函数来塑造“人工势能面”以直观的理解和感受它们.

在这个“人工势能面”中,我们定义了两个反应坐标X和Y, 和一个Z轴代表能量.沿着X从小到大的方向,分子从反应物到达一阶鞍点过渡态之后落入产物势阱.
然而对于一些特殊的反应,反应势能面可能并非这样简单,比如同一个过渡态可能会导向多个产物,再比如在原子经过过渡态后的动量使其在稳定前就已经越过之后的其他过渡态,又或者这两种效应同时存在.这种不能被传统过渡态理论解释的现象,被称为动力学效应(dynamic effect).
下面是一个具有后过渡态分叉(post-transition state bifurcation, PTSB,动力学效应的一种)性质的势能面: 当分子从左侧反应物势阱通过过渡态后,会进入较平坦的区域,之后随机落入两个产物势阱中.这种效应对于解释反应的选择性提供了新的可能,也为反应设计提出新的问题和挑战.比如PTSB可以介导酶催化等反应,也可以影响碳正离子重排反应的过程,为萜类化合物的合成提供新的视角.

图上的势能面两侧是完全对称的,也就是说如果只考虑势能面本身,从左侧经过过渡态进入势能面的分子落入两侧势阱的概率应各百分之五十.对于这类反应,如果只用一条动力学轨迹模拟来描述从反应物到某一产物的过程,那么另一产物的生成信息就被掩盖掉了.在这种情况下,只有反复从过渡态向两侧跑动力学轨迹才能够观察到分岔路径产生多于一种产物的现象.而这也是为什么类似的效应被冠以“动力学”之名——
多种产物之间的选择性不能通过对比过渡态的高低所决定,只有通过从同一过渡态多次反复收集反应的轨迹才能预测其不同产物的生成概率.
具有动力学效应的反应往往涉及到多个键的断裂与形成,比如下面这个反应的过渡态只有H5从C4转移至C1的特征,但当H位移后,部分轨迹通过C1-C4键(蓝色)的形成生成新的四元环,而其他轨迹则发生了C2-O3键(红色)断裂从而生成两个碎片 (来源:J. Am. Chem. Soc. 2022, 144, 17219−17231)

图中的反应物中的“冒号”处其实链接着一个金属催化剂,由于对反应影响不大,我们将其简化了.
由于涉及的反应原子众多,这类反应的势能面很难由特定的键长、键角、二面角、配位数等几何参数以二维或三维的形式直观地描述 —— 例如轨迹的分歧具体在哪个位置,是距离过渡态较远还是较近?分子运动的模式是更倾向于哪一侧产物?
这时候PCA就可以闪亮登场了!通过PCA我们可以提取轨迹的重要几何特征来帮助我们回答上面的问题.
以下的xyz文件中包含这一反应的九条动力学轨迹,其中有五条生成了蓝色产物P1,四条生成了红色产物P2.我们将对前五个原子(C1,C2,O3,C4,H5)的原子坐标进行主成分分析并投影轨迹.
--2023-07-24 12:41:49-- https://dp-public.oss-cn-beijing.aliyuncs.com/community/PTSB_trajs.xyz Resolving ga.dp.tech (ga.dp.tech)... 10.255.254.7, 10.255.254.37, 10.255.254.18 Connecting to ga.dp.tech (ga.dp.tech)|10.255.254.7|:8118... connected. Proxy request sent, awaiting response... 200 OK Length: 2096255 (2.0M) [chemical/x-xyz] Saving to: ‘PTSB_trajs.xyz.1’ PTSB_trajs.xyz.1 100%[===================>] 2.00M --.-KB/s in 0.09s 2023-07-24 12:41:50 (22.9 MB/s) - ‘PTSB_trajs.xyz.1’ saved [2096255/2096255]
方差解释比率 (PC1): 0.3847 方差解释比率 (PC2): 0.2803
可以看出对于这种涉及多个键的形成与断裂的轨迹并像之前的H转移体系一样直观——前两个PC加起来也只能描述约66%的分子结构变化信息,这体现了轨迹的信息复杂性.下面让我们看一看轨迹们投影在PC1和PC2向量空间的结果:

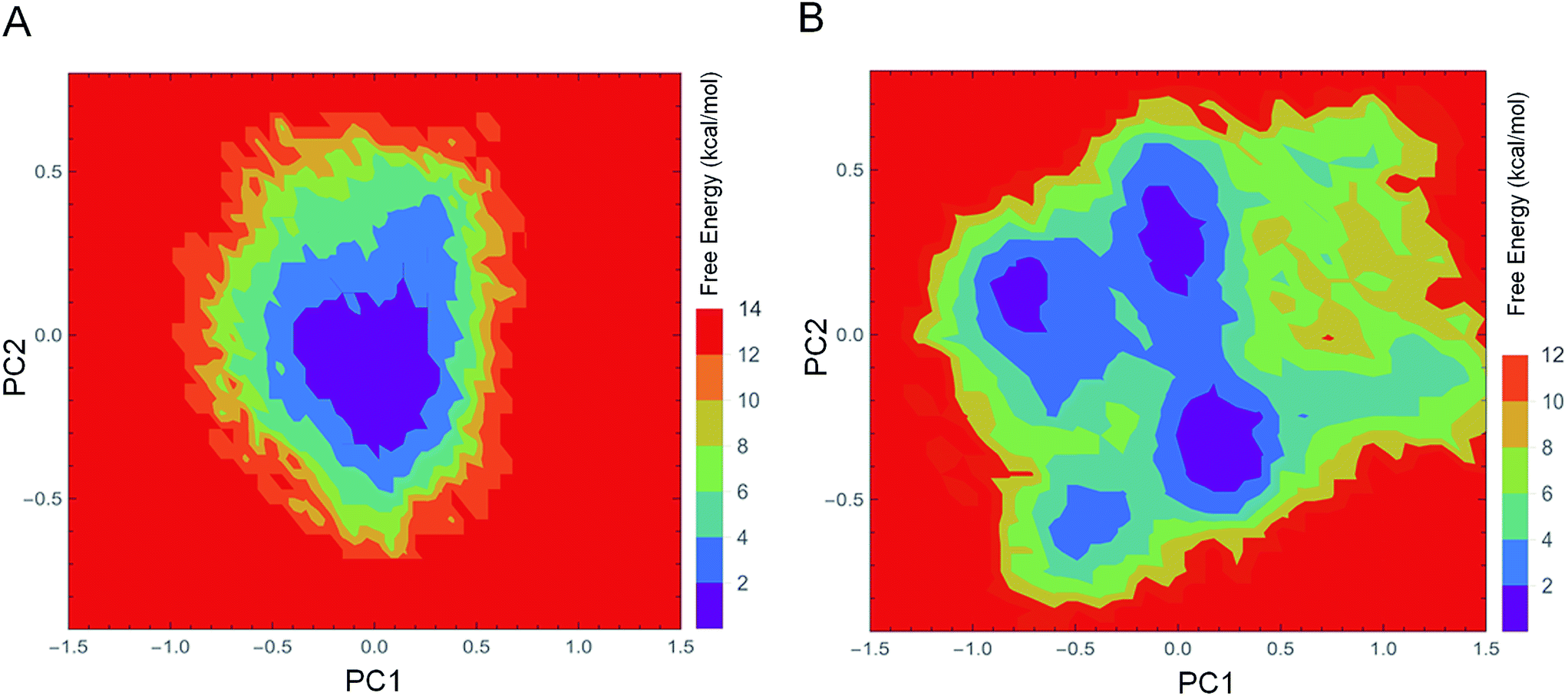
打个响指,把结构也加入到图中(为了让原子尽可能大,只可视化了1-5号原子):

从这张图上可以看出PCA处理后的结果可以清楚地区分两种不同产物的轨迹而保留它们从反应物到过渡态再到分岔点的相似性:
- P1在投影后位于画布的右侧,P2位于画布的左上侧,而反应物位于画布的左下角.
- 两种轨迹在画布的中心有着明显的分岔点,并且分岔发生地较早,距离过渡态不远
- 因为反应物->过渡态->P1在图中处于一致的方向上,因此从原子运动的角度来看应倾向于生成P1
那么PCA的结果是否有局限性呢? 答案是:当然有局限性!
基于结构变化的投影结果只能体现原子运动方向的主要特征(原子的速度,动量,运动方向),并没有任何势能面形状的信息(比如:生成P1的通道斜率更大还是生成P2的通道斜率更大?).因此,在确认了PC后我们可以通过构建2D自由能势/能面的来可视化能量如何影响分岔效应.
恭喜你!你已经成功完成了场景二,在一个更复杂的反应机理下运用PCA提取轨迹的主要信息.这篇BN马上就要结束啦,让我们一起进入最后的部分吧.
结语
主成分分析(PCA)通过计算数据的协方差矩阵的特征向量来确定数据中最具信息量的方向以实现用于从高维数据中提取主要特征。在化学和生物学领域,动力学轨迹主成分分析用于识别和描述分子的主要运动模式和重要结构变化。比如——动力学轨迹PCA可以帮助揭示分子内部的协同运动、折叠和解折叠过程、重要域的大尺度运动等,从而为理解分子的功能和性质提供洞察和见解。主成分分析在构建势能面方面也具有一定的应用,帮助研究者选择合适的2D维度来可视化更多的信息。
需要注意的是,标准主成分分析以及基于标准主成分分析的降维方法们(如稀疏主成分分析spare PCA)具体的应用和结果取决于数据的质量、特征提取的方式以及拟合模型的选择和精度。因此,在具体的研究中,需根据实际情况综合考虑和优化PCA的应用方法。
回到开篇的例子,现在你不仅可以帮助百年前的东坡通过主成分分析来找到最好的观赏庐山的角度,还可以将PCA运用到酒水分析、分子动力学轨迹,甚至更多你感兴趣的场景中了!
附录
- 过渡态理论与过渡态搜索:
Truhlar, Donald G., Bruce C. Garrett, and Stephen J. Klippenstein. "Current status of transition-state theory." The Journal of physical chemistry 100.31 (1996): 12771-12800.https://doi.org/10.1021/jp953748q
Laidler, Keith J., and M. Christine King. "The development of transition-state theory." J. phys. Chem 87.15 (1983): 2657-2664.http://www.srneclab.cz/lectures/MC260P87/supp/lecture8b.pdf
Peng, Chunyang, and H. Bernhard Schlegel. "Combining synchronous transit and quasi‐newton methods to find transition states." Israel Journal of Chemistry 33.4 (1993): 449-454.https://onlinelibrary.wiley.com/doi/abs/10.1002/ijch.199300051
Weinan, E., Weiqing Ren, and Eric Vanden-Eijnden. "String method for the study of rare events." Physical Review B 66.5 (2002): 052301. https://doi.org/10.1103/PhysRevB.66.052301
- 内禀反应坐标:
Fukui, Kenichi. "The path of chemical reactions-the IRC approach." Accounts of chemical research 14.12 (1981): 363-368.http://dx.doi.org/10.1021/ar00072a001
Taketsugu, Tetsuya, and Mark S. Gordon. "Dynamic reaction path analysis based on an intrinsic reaction coordinate." The Journal of chemical physics 103.23 (1995): 10042-10049.https://doi.org/10.1063/1.470704
- 动力学效应:
Ussing, Bryson R., Chao Hang, and Daniel A. Singleton. "Dynamic effects on the periselectivity, rate, isotope effects, and mechanism of cycloadditions of ketenes with cyclopentadiene." Journal of the American Chemical Society 128.23 (2006): 7594-7607. https://doi.org/10.1021/ja0606024
Carpenter, Barry K. "Energy disposition in reactive intermediates." Chemical Reviews 113.9 (2013): 7265-7286. https://doi.org/10.1021/cr300511u
Jayee, Bhumika, and William L. Hase. "Nonstatistical reaction dynamics." Annual Review of Physical Chemistry 71 (2020): 289-313.https://doi.org/10.1146/annurev-physchem-112519-110208
Tantillo, Dean J. "Beyond transition state theory—Non-statistical dynamic effects for organic reactions." Advances in Physical Organic Chemistry. Vol. 55. Academic Press, 2021. 1-16.https://doi.org/10.1016/bs.apoc.2021.06.001






AnguseZhang
AnguseZhang
Wentao
Charmy Niu