


Diffusion probabilistic models - Introduction
Author : Philippe Esling (esling@ircam.fr)
This second notebook continues the exploration of diffusion probabilistic models [ 1 ] in our four notebook series.
- Score matching and Langevin dynamics.
- Diffusion probabilistic models and denoising
- Applications to waveforms with WaveGrad
- Implicit models to accelerate inference
Here, we quickly recall the basics of score matching [ 3 ] and Langevin dynamics seen in the previous notebook. Then, we introduce the original formulation of diffusion probabilistic models based on thermodynamics [ 2 ] , and more recent formulations from denoising [ 1 ] .
Theoretical bases - quick recap
In this section we provide a quick recap on score matching from the previous notebook, still based on the swiss roll dataset.
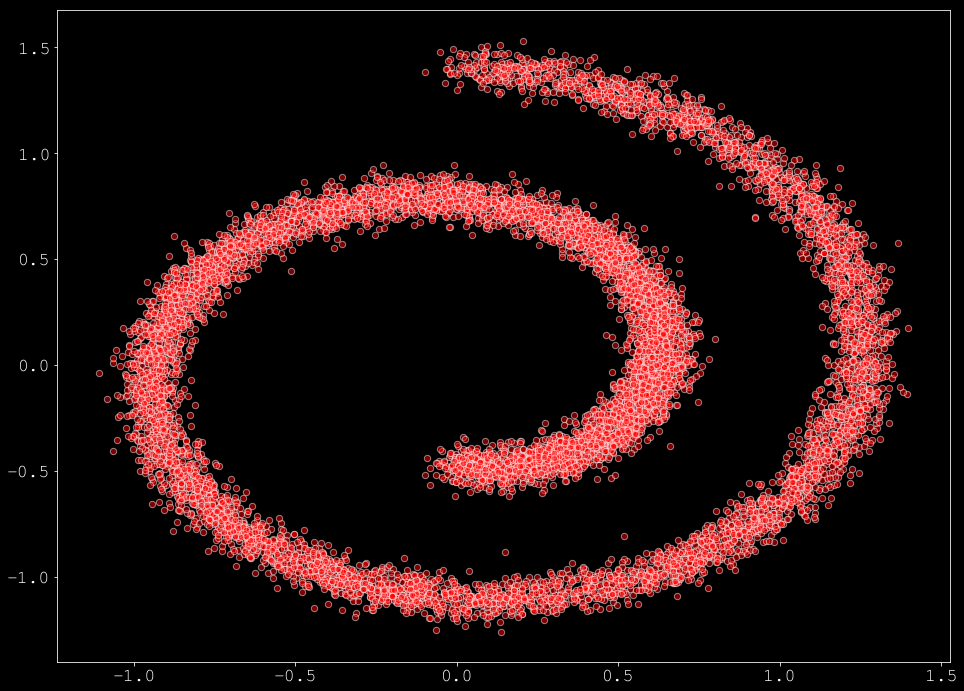
Score matching
Score matching aims to learn the gradients (termed score) of with respect to instead of directly . Therefore, we seek a model to approximate
We have seen that optimizing this model with an MSE objective was equivalent to optimizing
where denotes the Jacobian of with respect to . The problem with this formulation lies in the computation of this Jacobian, which does not scale well to high-dimensional data. This leads to a more efficient formulation of sliced score matching, which relies on random projections to approximate the computation of the Jacobian with
where are a set of Normal-distributed vectors. They show that this can be computed by using forward mode auto-differentiation, which is computationally efficient, as shown in the following implementation
Denoising score matching
Originally, denoising score matching was discussed by Vincent [ 3 ] in the context of denoising auto-encoders. In our case, we can completely remove the use of in the computation of score matching, by corrupting the inputs through a distribution . It has been shown that the optimal network can be found by minimizing the following objective
An important remark is that is only true when the noise is small enough . As it has been shown in [ 3 ] , [ 8 ] , if we choose the noise distribution to be , then we have . Therefore, the denoising score matching loss simply becomes
We can implement the denoising score matching loss as follows
Regarding optimization, we can perform a very simple implementation of this process, by define as being any type of neural network. We can perform the minimalistic implementation as follows
tensor(9996.8447, grad_fn=<MulBackward0>) tensor(10036.8750, grad_fn=<MulBackward0>) tensor(10104.2119, grad_fn=<MulBackward0>) tensor(9976.1631, grad_fn=<MulBackward0>) tensor(9974.6611, grad_fn=<MulBackward0>)
We can observe that our model has learned to represent by plotting the output value across the input space
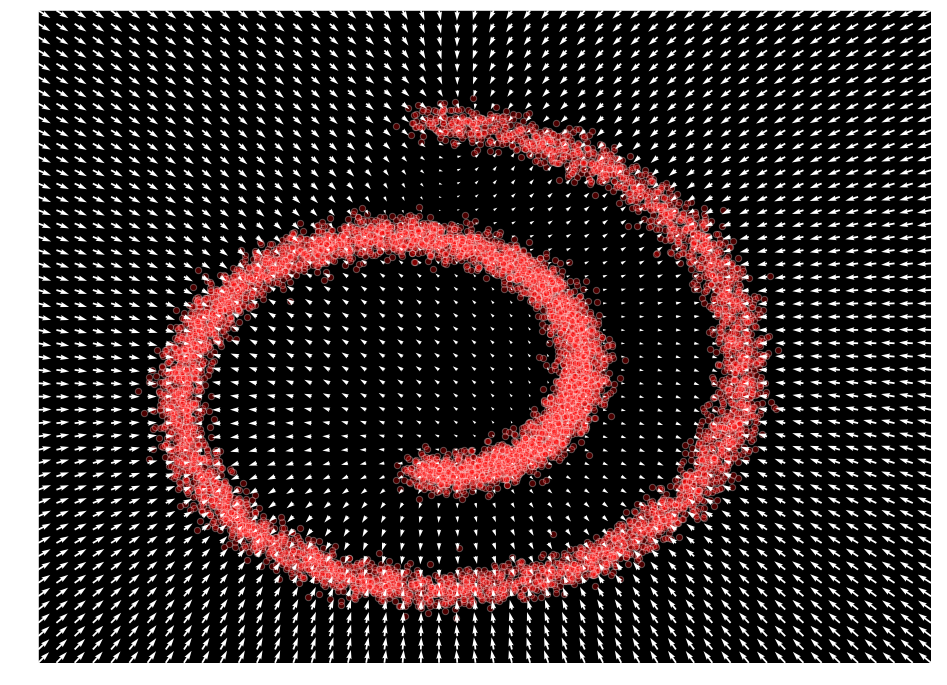
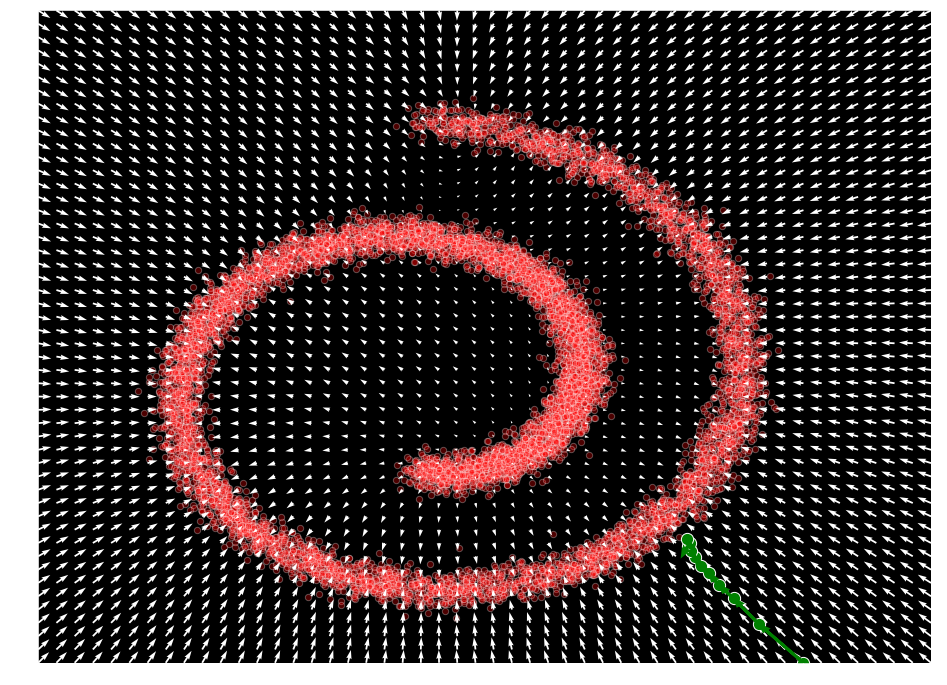
Langevin sampling
We have also seen that Langevin dynamics is a process from thermodynamics that can produce true samples from a density , by relying only on
where and under : converges to an exact sample from . This is a key idea behind the score-based generative modeling approach.
Diffusion models
Diffusion probabilistic models were originally proposed by Sohl-Dickstein et al. [ 1 ] based on non-equilibrium thermodynamics. These models are based on two reciprocal processes that represent two Markov chains of random variables. One process that gradually adds noise to the input data (called the diffusion or forward process), destroying the signal up to full noise. In the opposite direction, the reverse process tries to learn how to invert this diffusion process (transform random noise into a high-quality waveform). This is examplified in the following figure, where we can see the whole model.

As we can see, the forward (and fixed) process gradually introduces noise at each step. Oppositely, the reverse (parametric) process must learn how to denoise local perturbations. Hence, learning involves estimating a large number of small perturbations, which is more tractable than trying to directly estimate the full distribution with a single potential function.
Both processes can be defined as parametrized Markov chains, but the diffusion process is usually simplified to inject pre-selected amounts of noise at each step. The reverse process is trained using variational inference, and can be modeled as conditional Gaussians, which allow for neural network parameterization and tractable estimation.
Formalization
Diffusion models are based on a series of latent variables that have the same dimensionality as a given input data, which is labeled as . Then, we need to define the behavior of two process
Forward process
In the forward process, the data distribution is gradually converted into an analytically tractable distribution , by repeated application of a Markov diffusion kernel , with a given diffusion rate .
This diffusion kernel can be set to gradually inject Gaussian noise, given a variance schedule such that
The complete distribution is called the diffusion process and is defined as
Here, we show how to perform a naive implementation of the simple forward diffusion process with a constant variance schedule

We can define any type of variance schedules for , as provided in the following function
Interestingly, the forward process admits sampling at an arbitrary timestep . Using notations and , we have
Therefore, we can update our diffusion sampling function to allow for this mecanism. Note that this depends on the given variance schedule of that we compute prior to the function.
This allows to perform a very efficient implementation of the forward process, where we can directly sample at any given timesteps, as shown in the following code.
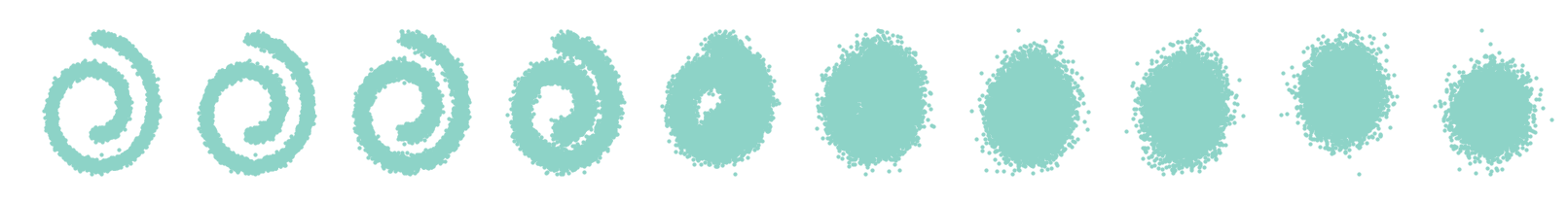
Note that for training, we will also need to have access to the mean and variance of the posterior distribution of this process.
Reverse process
The generative distribution that we aim to learn will be trained to perform the reverse trajectory, starting from Gaussian noise to gradually remove local perturbations. Therefore the reverse process starts with our given tractable distribution and is described as
Each of the transitions in this process can simply be defined as conditional Gaussians (note: which is reminiscent of the definition of VAEs). Therefore, during learning, only the mean and covariancce for a Gaussian diffusion kernel needs to be trained
The two functions defining the mean and covariance can be parametrized by deep neural networks. Note also that these functions are parametrized by , which means that a single model can be used for all time steps.
Here, we show a naive implementation of this process, where we have a given model to infer variance. Note that this model is shared across all time steps but conditionned on that said time step.
As we can see, the reverse process consists in inferring the values of the mean and log variance for a given timestep. Then, once we have learned the correponding model, we can perform the denoising of any given timestep, by providing both the sample at a given time step, and that time step that we can use to condition the models for and .
Finally, obtaining samples from the model is given by running through the whole Markov chain in reverse, starting from the normal distribution to obtain samples from the target distribution. Note that this process can be very slow if we have a large number of steps, as we need to wait for a given to infer the following
Model probability
The complete probability of the generative model is defined as
At first sight, this integral appears intractable. However, using a similar approach than variational inference, this integral can be rewritten as
Training
By using Jensen's inequality on the previous expression, we can see that the training may be performed by optimizing the variational bound on negative log-likelihood
Therefore, efficient training is allowed by optimizing random terms of with gradient descent.
To optimize this loss, we will need several computational tools, notably the KL divergence between two gaussians, and the entropy of a Gaussian.
Training loss
In the original paper by Sohl-Dickstein et al. [ 1 ] , this loss is shown to be reducible to
Hence, all parts of this loss can be quite easily estimated, as we are dealing with Gaussian distributions in all cases
Training random time steps
The way that the model is trained is slightly counterintuitive, since we select a timestep at random to train for each of the batch input. The implementation taken from the DDIM repo provides a form of antithetic sampling, which allows to ensure that symmetrical points in the different chains are trained jointly. Therefore, the final procedure consists in first run the forward process on each input at a given (random) time steps (performing diffusion). Then we run the reverse process on this sample, and compute the loss.
We can very simply optimize this loss with the following training loop.






Denoising diffusion probabilistic models (DDPM)
In a very recent article, Ho et al. [ 1 ] constructed over the diffusion models idea, by proposing several enhancements allowing to enhance the quality of the results. First, they proposed to rely on the following parameterization for the mean function
Note that now, the model is trained at outputing directly a form of noise function, which is used in the sampling process. Furthermore, the authors suggest to rather use a fixed variance function
This leads to a new sampling procedure for the reverse process as follows (we also quickly redefine the model to output the correct dimensionality).
Notably, the forward process posteriors are tractable when conditioned on
And we can obtain the corresponding mean and variance as
Training in DDPM
Further improvements come from variance reduction by rewriting as a sum of KL divergences
All the KL divergences defined in this equation compare Gaussians, which means that they have a closed-form solution.
This leads to a new loss function as implemented in the following (note that this objective does not provide large change to the optimization itself).
Simplifying loss to denoising score matching
The paper by Ho et al. [ 1 ] proposes a new parameterization for the mean of the reverse process Based on this parametrization, they show that the training objective can simplify to which resembles denoising score matching over multiple noise scales indexed by .
Further simplified training objective
The authors discuss the fact that it is beneficial to the sample quality to completely remove the complicated factor at the beginning of the loss. This further simplifies the objective as We can see that this objective now very closely ressemble the denoising score matching formulation. Furthermore, it provides an extremely simple implementation.
Stabilizing training with Exponential Moving Average (EMA)
This idea is found in most of the implementations, which allows to implement a form of model momentum. Instead of directly updating the weights of the model, we keep a copy of the previous values of the weights, and then update a weighted mean between the previous and new version of the weights. Here, we reuse the implementation proposed in the DDIM repository.
The training loop is finally obtained with the following code










Bibliography
[1] Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. arXiv preprint arXiv:2006.11239.
[2] Sohl-Dickstein, J., Weiss, E. A., Maheswaranathan, N., & Ganguli, S. (2015). Deep unsupervised learning using nonequilibrium thermodynamics. arXiv preprint arXiv:1503.03585.
[3] Vincent, P. (2011). A connection between score matching and denoising autoencoders. Neural computation, 23(7), 1661-1674.
[4] Song, J., Meng, C., & Ermon, S. (2020). Denoising Diffusion Implicit Models. arXiv preprint arXiv:2010.02502.
[5] Chen, N., Zhang, Y., Zen, H., Weiss, R. J., Norouzi, M., & Chan, W. (2020). WaveGrad: Estimating gradients for waveform generation. arXiv preprint arXiv:2009.00713.
[6] Hyvärinen, A. (2005). Estimation of non-normalized statistical models by score matching. Journal of Machine Learning Research, 6(Apr), 695-709.
[7] Song, Y., Garg, S., Shi, J., & Ermon, S. (2020, August). Sliced score matching: A scalable approach to density and score estimation. In Uncertainty in Artificial Intelligence (pp. 574-584). PMLR.
[8] Song, Y., & Ermon, S. (2019). Generative modeling by estimating gradients of the data distribution. In Advances in Neural Information Processing Systems (pp. 11918-11930).