


Diffusion Models初探:你还是不懂扩散模型的基本原理?
摘要:本文介绍并实现了一维扩散模型的前向和反向过程,验证了一维扩散模型前反向过程的一致性;并进一步提出了两个朴素模型,最近邻与最大似然模型,以验证一维扩散模型正确性。
一、简介
深度扩散模型(Diffusion Models)是一类基于深度学习的生成模型,近年来在图像和文本生成方面取得了很大的进展。
它的基本思想是从完整的信号开始,逐步向添加噪声的方向进行,每一步只对信号做很小的改变。然后,利用深度神经网络从添加了噪声的信号中恢复原始完整的信号。 具体来说,深度扩散模型包含一个Forward过程和一个Backward过程:
Forward过程:逐步将原始数据加入噪声,得到添加了不同程度噪声的数据序列。
Backward过程:使用神经网络从加噪的数据中逐步恢复更清晰的数据,最终输出质量高的新样本。
同时,宋飏等人的工作将此类扩散模型与伊藤扩散(Ito Diffusion)的前向与反向随机微分方程联系在一起,他们证明DDPM是伊藤过程的一种随机离散(当然这也是模型最初取名叫Diffusion Models的题中之义),并提出另外的几种随机过程的构建形式。
本Bohrium Notebook将初探Diffusion Model的前向与反向过程,验证两个过程之间的等价性。
二、伊藤扩散与DDPM(前向过程)
根据定义,伊藤扩散由以下的SDE定义:
其中为漂移项,为扩散项。 而当我们取时,上述的随机微分方程转为
这便定义了扩散模型的前向过程:如果我们在的边界条件下解此随机微分方程,将得到每个时刻的概率分布
,其中
(得到的具体过程可以参考Simo Särkkä and Arno Solin: Applied Stochastic Differential Equations, Section 5.5)
这意味着,每个时刻下的分布都是以缩放后的为均值的某个高斯分布。因此,我们可以将其写为确定性的均值与随机性的方差两部分:
其中为标准高斯分布的随机变量。 而当我们对照DDPM的前向过程
就会发现,选取合适的与后,两者是完全一致的! 这为我们分析DDPM模型的dynamics提供了很重要的帮助。
当然,上述的还可以写为任意一个给定的的函数:
如果我们令,那么我们将得到
不难验证这与DDPM的step-wise forward过程
是一致的。
三、实现一个前向过程
前向过程的形式还是十分简单的。我们构建一个函数,并将其作为参数进行的线性组合即可。
这里我们使用一个形式的,这样相当于在diffusion model中使用立方的。
接下来我们构造一个代表数据分布的、初始的分布,例如80%的+1和20%的-1。我们打印出数据分布的均值,约为0.6:
real mean value: 0.5704
下面,我们构造一个step-wise的前向过程,将t在[0,1]区间内离散100份。
((1001, 5000), (1001,))
最后,我们将得到的trajectory画出来:
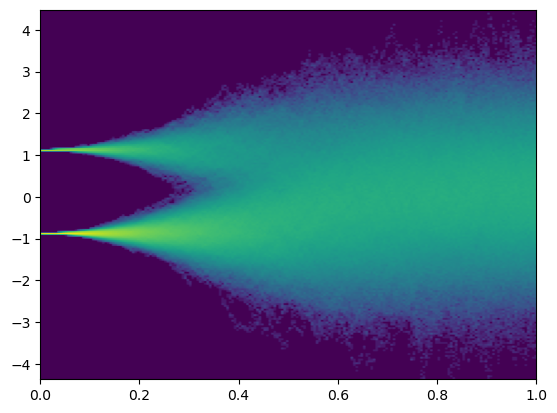
可以看到,正向的SDE可以正确的将在{-1, 1}支撑的两点分布平滑的过渡到N(0,1)的高斯分布。
四、反向SDE与实现
借由Fokker-Planck-Kolmogorov公式,我们可以推知反向过程应该服从的SDE:
此处为反向的Wiener过程。
代入系数进行化简后,我们可以得到反向过程的形式:
因为我们显式得到了,因此对应的score function 也可以显示计算:
因此我们可以实现以下的反向过程并打印出最终的均值:
backward mean value: 0.5704
可以看到,预测的和真实的的均值是相同的。
最终,我们画出反向SDE的图像,可以看到和正向的SDE图像相一致。
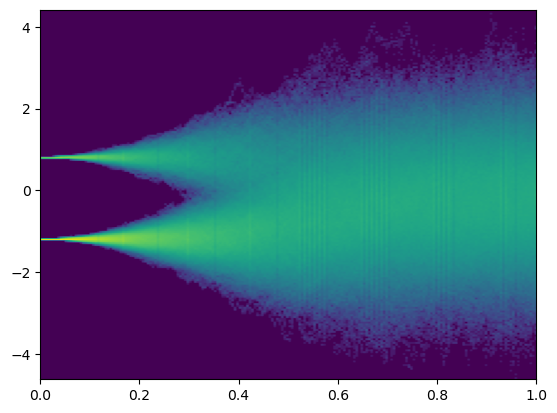
五、为反向过程引入噪音
最后,如果我们用不相关的噪声,污染每步用于计算score function的以模拟模型训练的不足呢?我们定义以下的反向过程:
然后测试noise=0.1和1.0的两种情况:
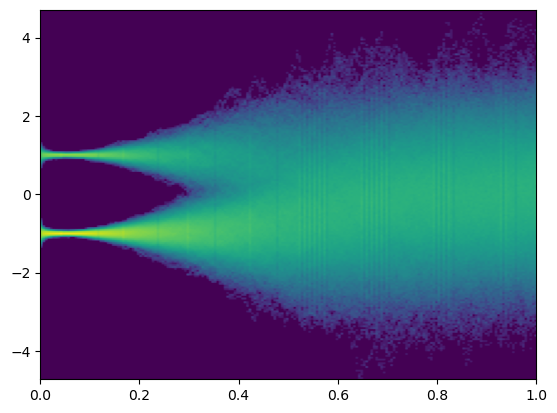
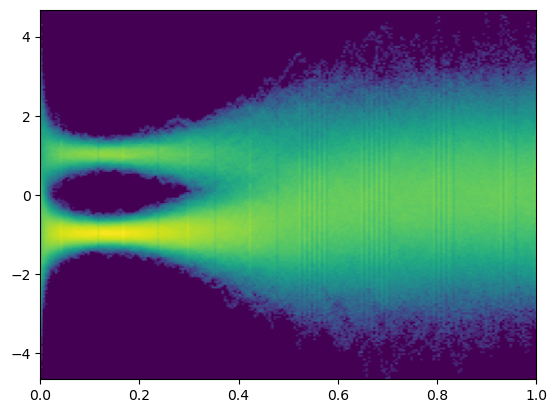
可以看到,在噪音较小时,反向的SDE仍可以有效地复原;但随着噪音增大,这样的复原便不再可行。
六、利用Nearest Neighbor构建最简单的模型
在四、五中,我们都是利用已知的标签来计算score function;而当他们未知时,我们就需要用模型学习反向过程,这将极大地增大完全复现反向SDE的难度。
下面我们将利用Nearest Neighbor的思路构建一个最简单的模型,即当时,我们认为,反之为。
让我们看看结果:
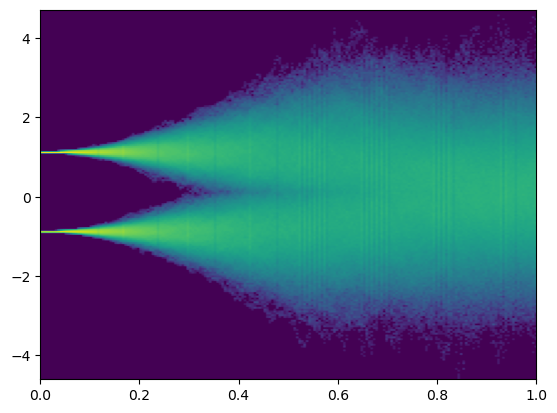
可以看到,反向的SDE的图像似乎和正向的还是很像的;但是最终预测的的分布和真实不同:均值从约0.6降至了0。这是因为此分类器并未考虑本身的先验分布,而是贪心的将样本分给最近的峰值。
七、构建一个MLE模型
进一步的,我们发现,既然我们已知与,那么我们可以通过贝叶斯公式构建一个更好的MLE模型:
比较与:
此处为生成时选取的的比例。
注意到当且仅当
即
我们由此得到了一个MLE分类器。
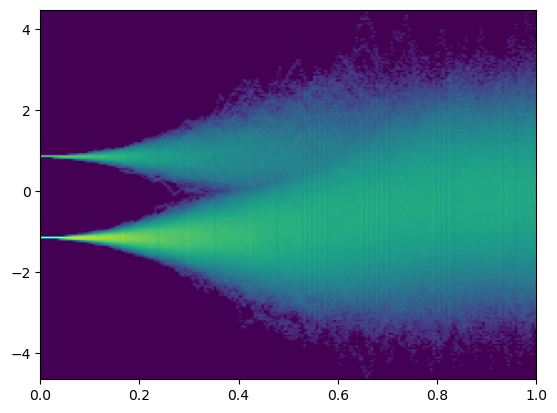
可以看到,通过考虑部分的prior分布,均值部分得到了修正。



