


扩散模型(DDPM)助力凝聚多肽的结构搜索
©️ Copyright 2023 @ Authors
作者:胡家鸣 📨 杨珺婷 📨
院校:西湖大学 工学院
**特别鸣谢** 西湖大学工学院助理研究员 汪嘉琪 提供了分子动力学数据用于本案例
参加过什么比赛:第三届 DeepModeling Hackathon 比赛
获得过什么奖项 : 第三届 DeepModeling Hackathon 大赛中获得AI4Lifescience赛道二等奖
推荐环境:
共享协议:本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
在生物系统中,单个大分子可以自组装成各种各样的超结构,在生命系统中发挥作用。控制此类系统形成的大多数分子相互作用是非共价的,其可逆性赋予了分子结构对外部刺激做出反应的能力。其中,蛋白质构成了一类特别多样化的自组装材料。举例来说,细胞运动和对表面的牵引力受到细胞骨架蛋白自我组装能力的显著调节;这些蛋白质的可逆自组装能够严格调节细胞的伸展和收缩,从而促进运动;其组装体网络还为许多活性过程提供能量,包括细胞迁移、细胞内内吞囊泡和其他膜结合细胞器的运动,以及特定细菌和病毒病原体的细胞间运输。
在天然和合成蛋白质自组装的研究中,人们发现尽管自然界中功能材料的构建单元通常是具有多达几百个氨基酸残基的蛋白质序列,但更短的氨基酸序列也可以表现出极其复杂的自组装行为。为此,人们通过仿生肽序列(包括肽两亲物、脂肽以及与其他分子的缀合物),来设计、预测和合成可自组装的多功能分子,形成了蓬勃发展的肽仿生领域,旨在设计出具有与天然产品相当或更好功能的合成材料。
在众多肽仿生自组装材料中,肽水凝胶由于其生物相容性、低免疫原性和与细胞外基质的相似性,引起了人们的极大关注。水凝胶是由固定水的自组装基质形成的软材料,研究人员认为水凝胶能够良好地模仿很多自然系统,如水母体、角膜、细胞核中浓缩的染色质等。到目前为止,肽水凝胶已广泛应用,包括材料科学、生物医学和半导体。然而,目前的设计能力尚达不到对新型肽水凝胶日益增长的需求,因为目前使用的技术仍然依赖于源自天然蛋白质的氨基酸序列、肽领域的专家知识或偶然的实验室发现。因此,从头肽水凝胶设计和准确的水凝胶形成预测对于建设水凝胶多肽的设计数据库至关重要。

在此方面,粗粒化分子动力学(CGMD)已被广泛用于模拟肽的自组装。然而,由于多肽设计空间十分巨大,对于n-肽来说,每个氨基酸残基都有20余种选择,则仅肽链序列就有种,且还有丰富的二级、三级结构,因此直接进行CGMD模拟十分昂贵且低效。
为此,基于已知的多肽水凝胶,利用机器学习的方法预测生成新的凝聚多肽结构,成为一个十分有潜力的研究方向。
材料结构预测类任务的主要困难在于寻找稳定的结构。虽然材料结构的设计空间非常之大(可以想像,一个材料通常由多个原子构成,而每个原子又都可以放在三维空间的各个位置),但能够稳定存在的材料结构只是其中的很小一部分,即被限制在所有可能的排列的低维子空间内,这主要包括以下要求:1) 原子坐标必须处于量子力学定义的局部能量最小值;2) 全局稳定性还要求结构遵守各种原子类型之间复杂而独特的键合偏好;3)对跨越周期边界的3D结构与相互作用进行编码,并满足排列、平移、旋转和周期不变量。目前,机器学习用于对于3D周期材料的生成预测已有多种解决方案,包括但不限于以下分类:
- 材料图表示学习(Material graph representation learning)。图神经网络在材料性能预测中发挥了重要作用。Xie, Grossman(2018)首次将它们应用于周期材料的表征学习,后来通过包括Schutt等人在内的许多研究得到了加强(2018)。
- 量子力学搜索(Quantum mechanical search)。预测未知材料的结构需要非常昂贵的随机搜索和QM模拟(Oganov等人, 2019). 现有技术的方法包括随机采样(Pickard&Needs,2011)、进化算法等,但它们通常成功率较低,即使在相对较小的问题上也需要大量计算。
- 材料生成模型(Material generative models)。已有的材料生成模型主要关注两种不同的方法。第一种方法将材料视为3D体素图像,但将图像解码回原子类型和坐标的过程往往导致有效性低,并且模型不是旋转不变的(Hoffmann等人,2019;Noh等人,2019年;Court等人,2020;Long等人,2021)。第二种方法直接将原子坐标、类型和晶格编码为向量(Ren等人,2020年;Kim等人,2020;Zhao等人,2021),但模型通常不会对任何欧几里德变换保持不变。另一种相关方法是从QM力训练力场,然后应用学习到的力场,通过最小化能量来产生稳定的材料,这种方法在概念上类似于扩散模型的解码器,但它需要额外的、昂贵的力场数据。
- 分子构象的产生和蛋白质折叠(Molecular conformer generation and protein folding)。通过扩散过程生成3D原子结构的解码器与用于生成分子构象异构体的扩散模型密切相关(Shi等人,2021;Xu等人,2021)。扩散模型不依赖于像分子图这样的中间表示,而是直接逐个原子的生成3D分子。
在众多算法模型中,扩散模型(Denoising Diffusion Probabilistic Models, DDPM)是近两年兴起的一种生成型人工智能模型,在图片生成等领域与传统的生成变分自编码器(Variational autoencoder,VAE)、生成对抗性网络(Generative adversarial network,GAN)相比有着不俗的性能。基于E(3)等变的图表示的扩散模型等已经在小分子上显示出有效性。
目前,上述各类方法主要针对无机晶体、蛋白质等体系,针对凝聚多肽(多肽水凝胶)的结构预测工作尚未见诸报道。本课题旨在基于前人工作,使用DDPM学习Gromacs分子动力学计算得到的多肽结构数据,构建其2D投影表示,利用DDPM网络进行学习并预测生成更多稳定的凝聚多肽体系。
主要参考:
- Denoising Diffusion Probabilistic Models(DDPM)
- The Annotated Diffusion Model
- What are Diffusion Models?
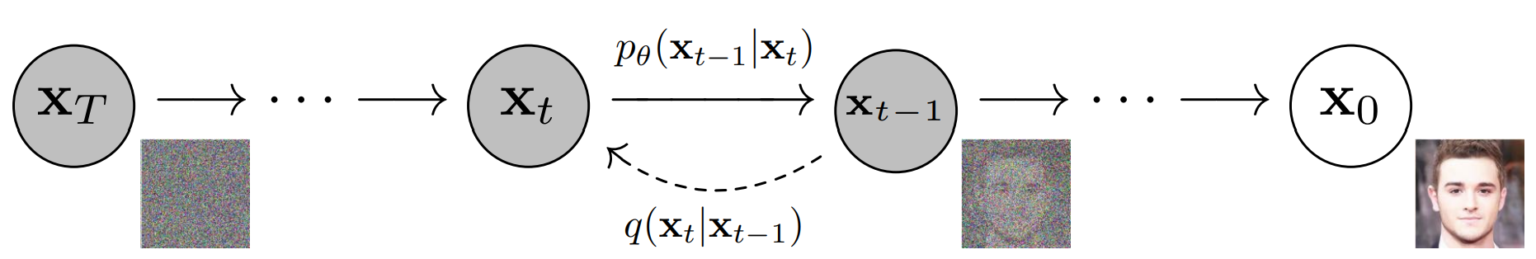
采用的数据是约16000个四肽水溶液体系的结构(实际训练中采样800~2000个)。每个结构都经过粗粒化分子动力学(CGMD)优化弛豫。其中“粗粒化“是指分子动力学力场采用了Martini粗粒化分子动力学力场,它一般将四个重原子用一个粒子(bead)代替;环状分子中两到三个重原子用一个粒子代替;四个水分子用一个粒子代替,若考虑可极化作用则用三个粒子代替,下文中我们所称的”原子“就是这些粗粒化的粒子bead。20种常见氨基酸的粗粒化表示如图

计算的流程如下图,先生成300个四肽短肽链,随机分布在格子中,然后充满水分子,再在常温下进行分子动力学模拟,最终得到弛豫好的结构,去除水分子、离子后即可得到水溶相四肽的结构,以Gromacs软件包的结构文件.gro格式存储。

下面展示了一些优化好的结构示例,绝大部分结构经过弛豫后,四肽小分子都会发生团聚现象,因而也称为凝聚多肽。可以从这些.gro文件获取凝聚多肽的2D投影表示(见另一篇Bohrium notebook),它具有图片的格式,可以直接输入DDPM进行训练。

值得注意的是,虽然这16000个多肽水溶液结构中,有的多肽是分散的、有的是凝聚的,但重点是它们都是经过可靠的分子动力学优化弛豫而来,因此可以认为都是稳定合理、符合物理规律的结构。这对于我们关注的生成任务,即让扩散模型去学习“一个稳定的多肽水溶液到底长什么样”从而使它能“自己设计”新的稳定的多肽水溶液体系,是最重要的。
向前扩散过程即按照一定顺序(扩散时间步)依次向图片添加弱高斯噪声。对某个时间步,被加噪的图片为,则即为加上一个方差为(为单位张量)、均值为()的条件高斯分布(conditional Gaussian distribution),记为。对于扩散时间步,设置的分布(variance schedules)对神经网络学习逆向解噪很重要。实际计算中可以通过标准高斯分布\(\mathbf{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})\)计算得到\(X_t = \sqrt{1 - \beta_t} X_{t-1} + \sqrt{\beta_t} \mathbf{\epsilon}\)。根据DDPM原文的设置,对于数值范围的图片数据,我们设置,,,并采用线性方差序列(linear schedule)。较大的意味着更精细的扩散时间步划分,有助于减小生成图片的信噪比。
由于高斯分布的优良性质,从扩散到并不需要真的依次计算,因为多个高斯分布的乘积还是高斯分布,所以这一过程等价于一个均值为,方差为的高斯分布
有了以上定义,我们可以定义q_sample函数从初始无噪声的图片x_start得到任意时间步t的噪声图像
让我们通过一个例子来看看高丝噪声对图片的影响,可以看到在第200步噪声时,图片已经几乎无法辨认。



根据对向前扩散过程的讨论,如果我们能训练一个神经网络denoise_model,它知道每一步添加的噪声“长什么样”,那就可以通过它一步步从完全无序的高斯噪声中还原出一副有序的图片,我们称之为向后扩散过程,记为. 因此,评价denoise_model的好坏,就是要看它预测的噪声predicted_noise和实际向前扩散的噪声x_noisy之间的差异是否够小,据此我们可以定义训练神经网络的损失函数p_loss如下
类似地,我们可以像向前扩散函数q_sample类似地定义向后扩散函数p_sample,只是此时扩散的均值和方差都由我们要训练的神经网络model预测
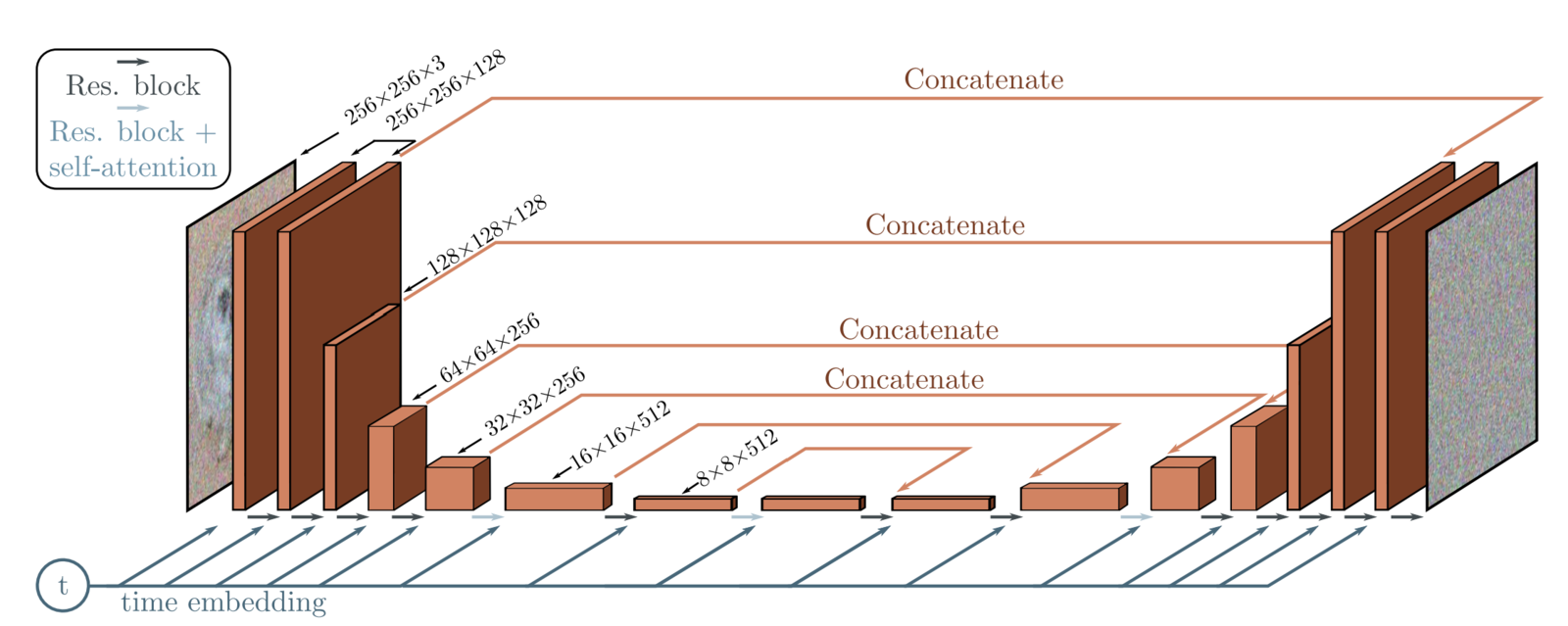
在DDPM中,作者采用一种能够自编码-解码的“U形”神经网络U-net来学习如何逆向解噪。U-net的输入是加噪时间步的和对应的图片,输出的解噪后的图片和解噪时间步。它由5个部分组成:
- 编码模块(Encoder blocks):构成网络的前半部分,共3~4层,每一层都包括一系列,它能够“取其精华、去其糟粕”,将一张图片不断“压缩”,提取特征;
- 瓶颈模块(Bottleneck blocks):连接编码模块和解码模块;
- 解码模块(Decoder blocks):构成网络的后半部分,于编码模块层数相同,将特征图不断“扩容”读取特征;
- 自注意力模块(Self attention modules)
- 时间编码模块(Sinusoidal time embeddings)
为了直观理解,我们可以看看embedding向量具体长什么样。

首先定义两个辅助函数
2. 特征提取模块
接着定义U-net的核心:特征提取模块,其中包括:
"升级版卷积模块“ConvNext
下/上采样模块:分别用2D卷积操作
nn.Conv2D和转置卷积操作nn.ConvTranspose2d实现。传统的卷积操作能够不断提取图片的特征进行编码,而通过转职卷积操作“解释”特征进行解码。前者通过下采样函数Downsample调用pytorch的实现,后者通过上采样函数Upsample调用pytorch的2D[]实现。对于不熟悉卷积的同学不要紧,这里和这两张动图都可以直观展示:


3 自注意力模块
自注意力模块(Self attention block)是著名的Transformer架构的组成部分, DDPM采用了两个attention的变体:regular multi-head self-attention 和linear attention variant. 后者的内存和计算时间需求随着序列长度线性增长,因而比平方增长的常规attention更加高效。
4 组归一化模块
在卷积/attention层之间还加入了组归一化(group normalization)
5 组建U-net网络
定义了各组成模块后,我们根据以下顺序依次搭建U-net网络。网络的输入是一个训练图片batch(batch_size, num_channels, height, width)+噪声(batch_size, 1) ,输出用于解噪的逆噪声(batch_size, num_channels, height, width)。网络结构为:
- 输入:加噪图片和加噪时间步被送入一个卷积层,其中加噪时间步转换为对应的embedding向量
- 编码:经过多层编码模块进行编码。每一个编码模块包含2个ConvNeXT模块 + 1个组归一化 + 1个自注意力模块 + 残差连接 + 下采样模块
- 瓶颈:“平级处理”,由1个卷积层+1个attention层+1个卷积层构成
- 解码:经过多层解码模块进行编码。每一个编码层包含2个ConvNeXT模块 + 1个组归一化模块 + 1个自注意力模块 + 残差连接 + 上采样模块
- 输出:ConvNeXT模块+一个卷积层输出
定义训练参数,其中image_size即对应2D投影表示的空间分辨率
导入数据,这里选择预先保存的凝聚多肽2D投影图
实例化U-net网络,对于小体量训练,我们只选取了3层编码/解码层
如果需要,载入之前的训练权重
<All keys matched successfully>
用pytorch的常用格式进行训练,其中学习率lr需要根据训练情况适当调节,这里简单的进行手动调节,分别在前期、中期和后期采用1e-3,1e-4,1e-5
Loss: 0.008132042363286018 Loss: 0.0077656847424805164 Loss: 0.011988483369350433
--------------------------------------------------------------------------- KeyboardInterrupt Traceback (most recent call last) Cell In[19], line 10 8 epochs = 10 9 for epoch in range(epochs): ---> 10 for step, batch in enumerate(dataloader): 11 optimizer.zero_grad() 14 batch = batch[0].to(device) File /opt/conda/lib/python3.8/site-packages/torch/utils/data/dataloader.py:634, in _BaseDataLoaderIter.__next__(self) 631 if self._sampler_iter is None: 632 # TODO(https://github.com/pytorch/pytorch/issues/76750) 633 self._reset() # type: ignore[call-arg] --> 634 data = self._next_data() 635 self._num_yielded += 1 636 if self._dataset_kind == _DatasetKind.Iterable and \ 637 self._IterableDataset_len_called is not None and \ 638 self._num_yielded > self._IterableDataset_len_called: File /opt/conda/lib/python3.8/site-packages/torch/utils/data/dataloader.py:678, in _SingleProcessDataLoaderIter._next_data(self) 676 def _next_data(self): 677 index = self._next_index() # may raise StopIteration --> 678 data = self._dataset_fetcher.fetch(index) # may raise StopIteration 679 if self._pin_memory: 680 data = _utils.pin_memory.pin_memory(data, self._pin_memory_device) File /opt/conda/lib/python3.8/site-packages/torch/utils/data/_utils/fetch.py:51, in _MapDatasetFetcher.fetch(self, possibly_batched_index) 49 data = self.dataset.__getitems__(possibly_batched_index) 50 else: ---> 51 data = [self.dataset[idx] for idx in possibly_batched_index] 52 else: 53 data = self.dataset[possibly_batched_index] File /opt/conda/lib/python3.8/site-packages/torch/utils/data/_utils/fetch.py:51, in <listcomp>(.0) 49 data = self.dataset.__getitems__(possibly_batched_index) 50 else: ---> 51 data = [self.dataset[idx] for idx in possibly_batched_index] 52 else: 53 data = self.dataset[possibly_batched_index] File /opt/conda/lib/python3.8/site-packages/torchvision/datasets/folder.py:231, in DatasetFolder.__getitem__(self, index) 229 sample = self.loader(path) 230 if self.transform is not None: --> 231 sample = self.transform(sample) 232 if self.target_transform is not None: 233 target = self.target_transform(target) File /opt/conda/lib/python3.8/site-packages/torchvision/transforms/transforms.py:95, in Compose.__call__(self, img) 93 def __call__(self, img): 94 for t in self.transforms: ---> 95 img = t(img) 96 return img File /opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs) 1496 # If we don't have any hooks, we want to skip the rest of the logic in 1497 # this function, and just call forward. 1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks 1499 or _global_backward_pre_hooks or _global_backward_hooks 1500 or _global_forward_hooks or _global_forward_pre_hooks): -> 1501 return forward_call(*args, **kwargs) 1502 # Do not call functions when jit is used 1503 full_backward_hooks, non_full_backward_hooks = [], [] File /opt/conda/lib/python3.8/site-packages/torchvision/transforms/transforms.py:361, in Resize.forward(self, img) 353 def forward(self, img): 354 """ 355 Args: 356 img (PIL Image or Tensor): Image to be scaled. (...) 359 PIL Image or Tensor: Rescaled image. 360 """ --> 361 return F.resize(img, self.size, self.interpolation, self.max_size, self.antialias) File /opt/conda/lib/python3.8/site-packages/torchvision/transforms/functional.py:490, in resize(img, size, interpolation, max_size, antialias) 488 warnings.warn("Anti-alias option is always applied for PIL Image input. Argument antialias is ignored.") 489 pil_interpolation = pil_modes_mapping[interpolation] --> 490 return F_pil.resize(img, size=output_size, interpolation=pil_interpolation) 492 return F_t.resize(img, size=output_size, interpolation=interpolation.value, antialias=antialias) File /opt/conda/lib/python3.8/site-packages/torchvision/transforms/_functional_pil.py:250, in resize(img, size, interpolation) 247 if not (isinstance(size, list) and len(size) == 2): 248 raise TypeError(f"Got inappropriate size arg: {size}") --> 250 return img.resize(tuple(size[::-1]), interpolation) File /opt/conda/lib/python3.8/site-packages/PIL/Image.py:2192, in Image.resize(self, size, resample, box, reducing_gap) 2184 self = Image.reduce(self, factor, box=reduce_box) 2185 box = ( 2186 (box[0] - reduce_box[0]) / factor_x, 2187 (box[1] - reduce_box[1]) / factor_y, 2188 (box[2] - reduce_box[0]) / factor_x, 2189 (box[3] - reduce_box[1]) / factor_y, 2190 ) -> 2192 return self._new(self.im.resize(size, resample, box)) KeyboardInterrupt:
查看Loss随着学习过程的变化。由于载入了之前训练过的模型,此时loss在很低的数值附近震荡、缓慢下降。
如有必要,存储训练模型的权重
模型直接输出的结果需要经过2项后处理:
- reshape: 将(batch_size, channels, height, width)转换为(batch_size, height, width, channels)方便图片显示
- rescale: 由于一个格子中大部分区域都没有原子分布,因此2D投影表示中的众数对应着空无原子的区域。有鉴于此,我们将生成的图片中灰度小于众数的位置处的数值都取为众数,以人工消除散落的原子噪声.为了节约运行时间,只对最后5个时间步运行这个操作,通过调用
plt.hist获得像素值的统计分布来确定众数.
查看生成数据的统计分布。第一张图original image是训练数据中某个batch的分布(数值已重新平移),可以看到最小值处分布有最多的像素点,这是因为大部分原子都凝聚在一起,投影表示图中大部分区域都没有原子,对应着像素值最小的点;第二张图是生成的一个batch在逆扩散初始时刻t=T的像素分布,可以看到其几乎就是高斯噪声;第三张图是该batch逆扩散至末态t=0的像素分布,此时已经和训练集分布有着接近的特征。
通过调用我们post在另一篇notebook“Gromacs分子动力学结构数据的2D表示”的函数接口,可以将生成的图片还原成伪3D的.gro文件并通过OVITO的软件可视化
下图展示了生成结果的一个例子,包括从t=T步逆扩散至t=0步的伪3D结构和2D投影表示

最后我们可以存储模型权重以备之后调用
也可以生成逆扩散过程的gif动画,更形象的演示DDPM逆向解噪的过程。
- 我们将分子动力学优化好的凝聚多肽水溶液体系的结构数据,映射到图片格式的2D投影表示,送入DDPM进行训练、生成。
- 现阶段进行了没有元素分辨能力的单通道尝试,结果表明DDPM可以成功学习到凝聚多肽的形貌特征,并生成新的凝聚多肽结构的2D投影表示,及其还原的伪3D表示。
- 我们另外测试了2D投影表示+肽链序列共同学习的方案,和3D粗粒化网格方案,但没有取得好的效果。
- 下一步可以扩展对元素的分辨能力,并增加投影表示的分辨率
为了确保比赛作品的完成度,我们小组采用同一套DDPM网络、两个投影表示方式并行推进的方式进行分工。胡家鸣负责难度相对较小的2D投影表示部分,结果已呈现于提交的notebook文档;杨珺婷负责风险更高的3D表示的尝试,因训练结果不佳,所以不再赘述。


huangjm@dp.tech