


快速开始 seaborn|入门 seaborn 数据可视化

©️ Copyright 2023 @ Authors
作者:阙浩辉 📨
日期:2023-05-09
共享协议:本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
🎯 本教程旨在快速掌握使用 Seaborn 进行数据可视化的范式周期。
一键运行,你可以快速在实践中检验你的想法。
丰富完善的注释,对于入门者友好。
在 Bohrium Notebook 界面,你可以点击界面上方蓝色按钮 开始连接,选择 bohrium-notebook 镜像及任何一款节点配置,稍等片刻即可运行。
目标
入门 seaborn 进行数据可视化。
在学习本教程后,你将能够:
- 绘制统计估计、分布表示、分类数据的图表
- 使用 seaborn 对复杂数据集进行多元视图绘制
- 使用 seaborn 默认的绘图主题以及自定义你的主题
阅读该教程【最多】约需 15 分钟,让我们开始吧!

1 认识 seaborn
在这一部分,你会了解什么是 seaborn,在 Bohrium 中使用 seaborn,验证安装并查看版本。

1.2 安装 seaborn
本教程是一个 Bohrium Notebook。Python 程序可直接在浏览器中运行,Bohrium 已安装 seaborn。
要按照本教程进行操作,请点击本页顶部的按钮,在 Bohrium Notebook 中运行本笔记本。
你可以点击界面上方蓝色按钮
开始连接,选择bohrium-notebook镜像及任何一款计算机型,稍等片刻即可运行。若要运行笔记本中的所有代码,请点击左上角“ 运行全部单元格 ”。若要一次运行一个代码单元,请选择需要运行的单元格,然后点击左上角 “运行选中的单元格” 图标。
如果你的 Bohrium 镜像尚未安装 seaborn, 最方便的方法是通过 pip 安装:
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple Requirement already satisfied: seaborn in /opt/conda/lib/python3.8/site-packages (0.11.2) Requirement already satisfied: scipy>=1.0 in /opt/conda/lib/python3.8/site-packages (from seaborn) (1.7.3) Requirement already satisfied: pandas>=0.23 in /opt/conda/lib/python3.8/site-packages (from seaborn) (1.5.3) Requirement already satisfied: numpy>=1.15 in /opt/conda/lib/python3.8/site-packages (from seaborn) (1.22.4) Requirement already satisfied: matplotlib>=2.2 in /opt/conda/lib/python3.8/site-packages (from seaborn) (3.7.1) Requirement already satisfied: packaging>=20.0 in /opt/conda/lib/python3.8/site-packages (from matplotlib>=2.2->seaborn) (23.0) Requirement already satisfied: pyparsing>=2.3.1 in /opt/conda/lib/python3.8/site-packages (from matplotlib>=2.2->seaborn) (3.0.9) Requirement already satisfied: contourpy>=1.0.1 in /opt/conda/lib/python3.8/site-packages (from matplotlib>=2.2->seaborn) (1.0.5) Requirement already satisfied: kiwisolver>=1.0.1 in /opt/conda/lib/python3.8/site-packages (from matplotlib>=2.2->seaborn) (1.4.4) Requirement already satisfied: python-dateutil>=2.7 in /opt/conda/lib/python3.8/site-packages (from matplotlib>=2.2->seaborn) (2.8.2) Requirement already satisfied: importlib-resources>=3.2.0 in /opt/conda/lib/python3.8/site-packages (from matplotlib>=2.2->seaborn) (5.2.0) Requirement already satisfied: fonttools>=4.22.0 in /opt/conda/lib/python3.8/site-packages (from matplotlib>=2.2->seaborn) (4.38.0) Requirement already satisfied: cycler>=0.10 in /opt/conda/lib/python3.8/site-packages (from matplotlib>=2.2->seaborn) (0.11.0) Requirement already satisfied: pillow>=6.2.0 in /opt/conda/lib/python3.8/site-packages (from matplotlib>=2.2->seaborn) (9.4.0) Requirement already satisfied: pytz>=2020.1 in /opt/conda/lib/python3.8/site-packages (from pandas>=0.23->seaborn) (2022.7) Requirement already satisfied: zipp>=3.1.0 in /opt/conda/lib/python3.8/site-packages (from importlib-resources>=3.2.0->matplotlib>=2.2->seaborn) (3.14.0) Requirement already satisfied: six>=1.5 in /opt/conda/lib/python3.8/site-packages (from python-dateutil>=2.7->matplotlib>=2.2->seaborn) (1.16.0) WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
如果你需要使用更特定于你的平台或包管理器的安装方法,你可以在这里查看更完整的安装说明。
0.11.2
seaborn 是我们在这个简单示例中唯一需要导入的库。为了方便使用,使用 sns 作为缩写。
在幕后,seaborn 使用 matplotlib 来绘制其情节。对于交互式工作,建议在 matplotlib 模式下使用 Jupyter/IPython 界面,否则当您想查看绘图时,您必须调用 matplotlib.pyplot.show()。
这一步 matplotlib rcParam 系统,并且会影响所有 matplotlib 绘图的外观,即使您不使用 seaborn 制作它们。除了默认主题之外,还有其他几个选项,您可以独立地控制图的样式和缩放,以便在演示文稿上下文中快速转换您的工作(例如,制作一个版本的图,当在演讲期间投影时,字体可读)。如果您喜欢 matplotlib 默认设置或喜欢其他主题,则可以跳过此步骤并仍然使用 seaborn 绘图函数。
--2023-03-27 21:46:35-- https://raw.githubusercontent.com/mwaskom/seaborn-data/master/tips.csv Resolving ga.dp.tech (ga.dp.tech)... 10.255.255.41 Connecting to ga.dp.tech (ga.dp.tech)|10.255.255.41|:8118... connected. Proxy request sent, awaiting response... 200 OK Length: 9729 (9.5K) [text/plain] Saving to: ‘tips.csv’ tips.csv 100%[===================>] 9.50K --.-KB/s in 0.04s 2023-03-27 21:46:35 (258 KB/s) - ‘tips.csv’ saved [9729/9729]
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 239 | 29.03 | 5.92 | Male | No | Sat | Dinner | 3 |
| 240 | 27.18 | 2.00 | Female | Yes | Sat | Dinner | 2 |
| 241 | 22.67 | 2.00 | Male | Yes | Sat | Dinner | 2 |
| 242 | 17.82 | 1.75 | Male | No | Sat | Dinner | 2 |
| 243 | 18.78 | 3.00 | Female | No | Thur | Dinner | 2 |
244 rows × 7 columns
大多数文档中的代码将使用load_dataset()函数快速访问示例数据集。这些数据集没有什么特别之处:它们只是pandas dataframe,我们可以使用pandas.read_csv()加载它们或手动构建它们。文档中的大多数示例将使用pandas dataframe指定数据,但是seaborn对其接受的数据结构非常灵活。

这个图显示了使用单个调用seaborn函数relplot()在”tips“数据集中的五个变量之间的关系。请注意,我们仅提供了变量的名称和它们在图中的作用。与直接使用matplotlib时不同,不需要使用颜色值或标记代码来指定图形元素的属性。在幕后,seaborn处理了从数据框中的值到matplotlib理解的参数的转换。这种声明性方法使您可以专注于要回答的问题,而不是控制matplotlib的细节。
--2023-03-27 21:46:38-- https://raw.githubusercontent.com/mwaskom/seaborn-data/master/dots.csv Resolving ga.dp.tech (ga.dp.tech)... 10.255.255.41 Connecting to ga.dp.tech (ga.dp.tech)|10.255.255.41|:8118... connected. Proxy request sent, awaiting response... 200 OK Length: 25742 (25K) [text/plain] Saving to: ‘dots.csv’ dots.csv 100%[===================>] 25.14K --.-KB/s in 0.04s 2023-03-27 21:46:38 (660 KB/s) - ‘dots.csv’ saved [25742/25742]
| align | choice | time | coherence | firing_rate | |
|---|---|---|---|---|---|
| 0 | dots | T1 | -80 | 0.0 | 33.189967 |
| 1 | dots | T1 | -80 | 3.2 | 31.691726 |
| 2 | dots | T1 | -80 | 6.4 | 34.279840 |
| 3 | dots | T1 | -80 | 12.8 | 32.631874 |
| 4 | dots | T1 | -80 | 25.6 | 35.060487 |
| ... | ... | ... | ... | ... | ... |
| 843 | sacc | T2 | 300 | 3.2 | 33.281734 |
| 844 | sacc | T2 | 300 | 6.4 | 27.583979 |
| 845 | sacc | T2 | 300 | 12.8 | 28.511530 |
| 846 | sacc | T2 | 300 | 25.6 | 27.009804 |
| 847 | sacc | T2 | 300 | 51.2 | 30.959302 |
848 rows × 5 columns

请注意,size和style参数在散点图和线图中都有使用,但它们会以不同的方式影响两个可视化效果:在散点图中更改标记区域和符号,而在线图中更改线宽和虚线。我们不需要记住这些细节,让我们专注于图的总体结构和我们想要传达的信息。
--2023-03-27 21:46:40-- https://raw.githubusercontent.com/mwaskom/seaborn-data/master/fmri.csv Resolving ga.dp.tech (ga.dp.tech)... 10.255.255.41 Connecting to ga.dp.tech (ga.dp.tech)|10.255.255.41|:8118... connected. Proxy request sent, awaiting response... 200 OK Length: 38329 (37K) [text/plain] Saving to: ‘fmri.csv’ fmri.csv 100%[===================>] 37.43K --.-KB/s in 0.09s 2023-03-27 21:46:41 (416 KB/s) - ‘fmri.csv’ saved [38329/38329]
| subject | timepoint | event | region | signal | |
|---|---|---|---|---|---|
| 0 | s13 | 18 | stim | parietal | -0.017552 |
| 1 | s5 | 14 | stim | parietal | -0.080883 |
| 2 | s12 | 18 | stim | parietal | -0.081033 |
| 3 | s11 | 18 | stim | parietal | -0.046134 |
| 4 | s10 | 18 | stim | parietal | -0.037970 |
| ... | ... | ... | ... | ... | ... |
| 1059 | s0 | 8 | cue | frontal | 0.018165 |
| 1060 | s13 | 7 | cue | frontal | -0.029130 |
| 1061 | s12 | 7 | cue | frontal | -0.004939 |
| 1062 | s11 | 7 | cue | frontal | -0.025367 |
| 1063 | s0 | 0 | cue | parietal | -0.006899 |
1064 rows × 5 columns

当估计统计值时,seaborn将使用bootstrapping来计算置信区间,并绘制代表估计不确定性的误差线1。
seaborn中的统计估计超出了描述性统计。例如,可以通过使用lmplot()来包含线性回归模型(及其不确定性)来增强散点图1。

2.2.2 分布表示
统计分析需要了解数据集中变量的分布。seaborn函数displot()支持多种可视化分布的方法,包括传统的直方图和计算密集的核密度估计。

seaborn 还推广一些强大但不太普遍的技术,例如计算和绘制数据的经验累积分布函数

2.2.3 分类数据的图表
几种专门的seaborn绘图类型是面向可视化分类数据的。它们可以通过catplot()访问。这些图表提供不同级别的细化。在最细的级别上,您可能希望通过绘制“swarm”图来查看每个观察结果:这是一种散点图,它沿着分类轴调整点的位置,以便它们不重叠。”
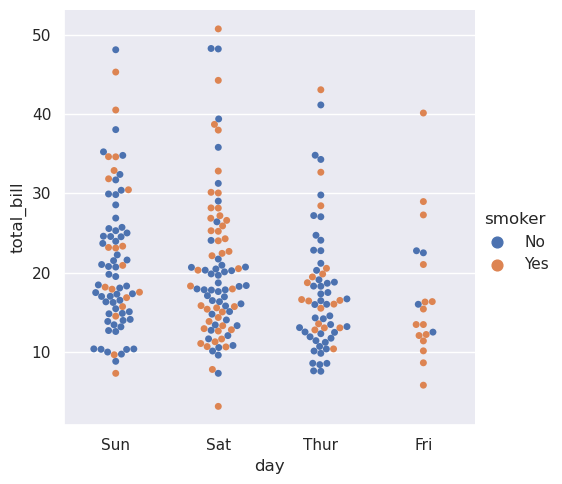
或者,您可以使用核密度估计来表示从中抽样的点的基础分布

或者,您可以仅在每个嵌套类别中显示均值及其置信区间

2.3 复杂数据集的多元视图
一些 seaborn 函数结合多种绘图类型,以快速提供数据集的信息摘要。其中之一,jointplot(),专注于单个关系。它绘制两个变量之间的联合分布以及每个变量的边际分布:
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | |
|---|---|---|---|---|---|---|---|
| 0 | Adelie | Torgersen | 39.1 | 18.7 | 181.0 | 3750.0 | MALE |
| 1 | Adelie | Torgersen | 39.5 | 17.4 | 186.0 | 3800.0 | FEMALE |
| 2 | Adelie | Torgersen | 40.3 | 18.0 | 195.0 | 3250.0 | FEMALE |
| 3 | Adelie | Torgersen | NaN | NaN | NaN | NaN | NaN |
| 4 | Adelie | Torgersen | 36.7 | 19.3 | 193.0 | 3450.0 | FEMALE |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 339 | Gentoo | Biscoe | NaN | NaN | NaN | NaN | NaN |
| 340 | Gentoo | Biscoe | 46.8 | 14.3 | 215.0 | 4850.0 | FEMALE |
| 341 | Gentoo | Biscoe | 50.4 | 15.7 | 222.0 | 5750.0 | MALE |
| 342 | Gentoo | Biscoe | 45.2 | 14.8 | 212.0 | 5200.0 | FEMALE |
| 343 | Gentoo | Biscoe | 49.9 | 16.1 | 213.0 | 5400.0 | MALE |
344 rows × 7 columns

另一个函数 pairplot() 则采用更广泛的视角:分别显示所有成对关系和每个变量的联合和边际分布:



当你准备分享或发布你的作品时,你可能想要以比默认值更好的方式来打磨图形。seaborn 允许多个级别的自定义。它定义了多个内置主题,适用于所有图形,它的函数具有标准化的参数,可以修改每个绘图的语义映射,并且其他关键字参数传递到底层的 matplotlib 艺术家,允许更多的控制。一旦你创建了一个图,它的属性可以通过 seaborn API 和通过下降到 matplotlib 层进行精细调整来修改:

3 与 matplotlib 的关系
seaborn 与 matplotlib 的集成允许您在 matplotlib 支持的许多环境中使用它,包括笔记本中的探索性分析、GUI 应用程序中的实时交互以及多种栅格和矢量格式的归档输出。
虽然您可以仅使用 seaborn 函数来提高生产力,但完全定制您的图形需要一些 matplotlib 的概念和 API 知识。seaborn 新用户的学习曲线之一是知道何时下降到 matplotlib 层是必要的,以实现特定的自定义。另一方面,从 matplotlib 来的用户会发现他们的许多知识都可以转移。
Matplotlib 有一个全面而强大的 API;几乎可以更改图形的任何属性以满足您的喜好。seaborn 的高级接口和 matplotlib 的深度可定制性的组合将允许您快速探索数据,并创建可以定制为出版质量最终产品的图形。
Received message. seaborn 与 matplotlib 的集成允许您在 matplotlib 支持的许多环境中使用它,包括笔记本中的探索性分析、GUI 应用程序中的实时交互以及多种栅格和矢量格式的归档输出。 虽然您可以仅使用 seaborn 函数来提高生产力,但完全定制您的图形需要一些 matplotlib 的概念和 API 知识。seaborn 新用户的学习曲线之一是知道何时下降到 matplotlib 层是必要的,以实现特定的自定义。另一方面,从 matplotlib 来的用户会发现他们的许多知识都可以转移。 Matplotlib 有一个全面而强大的 API;几乎可以更改图形的任何属性以满足您的喜好。seaborn 的高级接口和 matplotlib 的深度可定制性的组合将允许您快速探索数据,并创建可以定制为出版质量最终产品的图形。
总结
在本教程中,您学习了在 seaborn 的一些基础方法。
具体而言,您了解到:
- 根据简单示例快速进行 seaborn 绘图
- 绘制统计估计、分布表示、分类数据的图表
- 使用 seaborn 对复杂数据集进行多元视图绘制
- 如何使用 seaborn 默认的绘图主题以及自定义你的主题
你有什么问题吗? 欢迎与我们联系 bohrium@dp.tech 。



