


第13章:命令行和Spyder
到目前为止,我们一直在通过IPython环境运行所有的Python脚本,无论是在Jupyter笔记本还是Python解释器中。运行Python代码的第三种方法是将其保存为文本文件,并从计算机的或Jupyter的终端运行代码。这种方法的优点是它对于较大的脚本更实用,对于执行重复性任务(如重新格式化仪器数据)更方便。您将需要访问终端来运行您的Python脚本,具体内容如下。
13.1 浏览终端
终端是用于macOS和类unix系统(如Linux和BSD家族)的命令行界面,允许用户执行广泛的任务,从安装和运行软件到文件管理。如果你使用的是Linux或Mac,请从应用程序启动终端;如果你使用的是Windows,你可能需要先激活Bash命令行才能继续。或者,如果你使用的是JupyterLab版本的Jupyter,您可以从启动器菜单打开终端窗口(参见第0.2节,图2)。在第13.2节中,你将学习如何从终端运行Python脚本,但在运行脚本之前,你需要能够浏览文件系统并找到Python脚本。本节是通过终端浏览文件系统的简要入门。
13.1.1 目录名称和内容
当您打开终端时,你会看到如下所示的行,其中Comp是您的计算机名称,Me是你的帐户用户名。在$符号后面是您键入命令的地方。
Comp:~Me$
从这里,你可以浏览文件系统。首先,你需要知道当前正在查看文件系统的哪个位置。这就是所谓的当前工作目录,可以通过命令pwd(打印工作目录)来确定。
$ pwd
/Users/Me
这意味着我们当前位于用户Me的主目录中。要查看目录的内容,我们可以使用ls命令列出其内容。
$ ls
Applications Documents Movies
Public Downloads Music
anaconda Desktop Library
Pictures seaborn-data
你可能会在终端中看到一些文件,而在手动查看文件夹时看不到这些文件。这是正常现象。计算机通常包含诸如图标之类的项目的不可见文件,通常最好不要更改或删除这些不可见文件。
13.1.2 更改目录
要更改当前工作目录,请使用cd命令。这可以通过一次进入一个目录或提供完整路径名(如/Users/Me/Documents/Scripts/)来逐步使用。
$ cd Desktop
这只允许用户导航到文件夹。要退出文件夹,使用cd ..(空格加两个句点)。
$ cd ..
终端中当然还可以做更多的事情,但这足以作为您找到并运行脚本的基础,正如我们下面将要做的那样。
13.2 运行脚本
现在您已经了解了终端命令行的基本知识,我们可以运行第一个脚本了。打开您选择的文本编辑器。如果您在常规的文字处理器(如Word、LibreOffice、Pages等)中编写Python代码,请小心,因为它可能会在生成的文本文件中保存额外的格式。更好的选择是使用第3.5节中介绍的Spyder,或者(最简单的)从JupyterLab启动器中选择Python文件。在一个新文件中编写一些Python代码,然后将其另存为名为first_script.py的文本文件。.py扩展名并不对文件做任何事情,它只是向其他软件指示这个文本文件是一个Python脚本。在这个演示中,我将在我的文本文件中包含以下代码。
import random
rng = np.random.default_rng()
rdn = rng.integers(0,100)
print(rdn)
接下来,打开终端并导航至包含上述脚本文件的目录(即文件夹),然后在终端中输入以下内容。
$ python first_script.py
66
你刚刚从命令行运行了你的第一个脚本!输出内容只包括您在Python脚本中打印的内容。在命令行中运行脚本和在Jupyter笔记本中运行Python代码之间的一个关键区别是,当从命令行运行时,如果您想要显示某个内容,您需要使用print()函数明确指示这个操作。相比之下,Jupyter笔记本会自动打印未分配给变量的计算结果。
运行上述文件的另一种方法是提供带有完整(绝对)路径的文件,如下所示。
$ python /Users/Me/Desktop/first_script.py
98
这似乎要输入很多内容。一个方便的快捷方式是输入python,然后加上一个空格,接着将文件拖放到终端窗口中。这将导致文件路径和名称自动粘贴到终端窗口中。
$ python /Users/Me/Desktop/first_script.py
65
13.3 额外输入
在从命令行运行脚本时,您可能希望能够在Python脚本中包含额外的输入或信息。这可能以用户输入或额外文件的形式出现。以下是实现这一目标的方法,使您的脚本更具交互性。
13.3.1 用户输入
如果你希望用户能够输入值,Python提供了一个input()函数,提示用户提供信息。例如,如果我们想要编写一个根据氢和碳原子数量计算简单烃分子的分子量的脚本,允许用户输入氢和碳原子数量而不是修改脚本本身会很有帮助。input()函数内的参数是在用户前面提示输入的内容。需要注意的是,input()函数将用户输入作为字符串提供。由于我们期望得到整数,因此在计算分子的分子量之前,我们需要将这些字符串转换为整数,如下所示。
H = input('H = ')
C = input('C = ')
MW = int(H) * 1.01 + int(C) * 12.01
print(MW)
将上述脚本保存在名为MW.py的文本文件中并运行它。在计算并打印分子量之前,您会被提示提供氢和碳的数量。
$ python MW.py
H = 4
C = 1
16.05
13.3.2 sys.argv
允许用户提供额外信息的另一种方法是在调用脚本的同一行中提供所有所需信息。例如,当运行上述烃分子量脚本时,您可能希望它看起来像下面这样。
$ python MW.py 4 1
16.05
我们可以指示 Python 使用 sys 模块中的 argv() 函数来获取脚本文件名后面的信息。此函数将所有在python之后的信息作为一个列表,可以通过索引进行访问。上面的输入从 sys.argv 生成以下列表。
['MW.py', '4', '1']
现在只需要索引并将字符串转换为整数,如下所示。
import sys
H = sys.argv[1]
C = sys.argv[2]
MW = int(H) * 1.01 + int(C) * 12.01
print(MW)
现在我们可以按照以下方式运行脚本。
$ python MW.py 8 3
44.11
上述方法非常适合接受文件名和扩展名,因为它们可以更容易地拖到终端中而不是输入。这种方法的缺点是用户需要知道要向脚本提供哪些信息以及按照什么顺序。这类似于函数中关键字参数和位置参数之间的区别。
13.4 在 Jupyter 中运行 .py 文件
作为将外部 .py 文件中的 Python 脚本和 Jupyter 笔记本相结合的一种方法,可以使用 %run 魔术命令在 Jupyter 笔记本中运行这些 Python 脚本。例如,假设我们在名为 的文件中有以下代码。
pt1 = (1,5,9)
pt2 = (9, 0, 3)
def distance(coord1, coord2):
x1, y1, z1 = coord1
x2, y2, z2 = coord2
return ((x1 - x2)**2 + (y1 - y2)**2 + (z1 - z2)**2)**0.5
我们可以使用以下命令在 Jupyter 笔记本中运行此代码。就像我们之前看到的,除非另有说明,否则 Jupyter 认为引用的文件与 Jupyter 笔记本位于同一目录中。
--2023-09-06 23:08:26-- https://bohrium-example.oss-cn-zhangjiakou.aliyuncs.com/notebook/SciCompforChemists/notebooks/chapter_13/dist.py Resolving ga.dp.tech (ga.dp.tech)... 10.255.254.18, 10.255.254.37, 10.255.254.7 Connecting to ga.dp.tech (ga.dp.tech)|10.255.254.18|:8118... connected. Proxy request sent, awaiting response... 200 OK Length: 174 [application/octet-stream] Saving to: ‘dist.py’ dist.py 100%[===================>] 174 --.-KB/s in 0s 2023-09-06 23:08:26 (26.3 MB/s) - ‘dist.py’ saved [174/174]
(1, 5, 9)
11.180339887498949
现在已经执行了 文件,这些变量和函数在 Jupyter 笔记本中就像在 Jupyter 代码单元格中运行的代码一样可用。
13.5 Spyder
虽然使用文本编辑器编写脚本工作得很好,但你可能希望拥有 Jupyter 笔记本的一些功能,例如根据语法自动对文本进行颜色编码并提供轻松访问函数文档字符串的功能。为了找回这些功能,您可以使用集成开发环境(IDE)。有很多可以选择的,但在这里我们将介绍 Spyder(Scientific Python Development Environment),因为它专门针对科学应用程序,并附带 Python 的 Anaconda 安装。
有两种方法可以启动 Spyder。第一个是在终端中键入 spyder。
$ spyder
第二种方法是在 Anaconda Navigator 中按 Spyder 的启动按钮(图 1)。后一种方法通常较慢,因为它需要首先启动 Navigator。

图 1 Anaconda Navigator 应用程序启动器窗口的屏幕截图。
启动 Spyder 后,你将看到一个分为三个窗口的界面(图 2)。左边的窗口是一个文本编辑器,用于编写代码。与 Jupyter 笔记本一样,它根据语法对您的 Python 代码进行颜色编码,并提供文档字符串和有用的通知。要运行这里编写的代码,您可以将其另存为文本文件并按照上述方式运行,或者可以按窗口顶部的运行按钮(►)。后一种方法在脚本开发阶段特别方便,因为它允许您在不在 Spyder 和终端之间跳转的情况下快速测试和修改脚本。右下角的较小窗口是一个 Python 终端,您可以在其中测试代码并在 Spyder 内运行代码时查看代码的输出。右上角的窗口可用作文件导航器和变量浏览器,具体取决于您选择的选项卡。在图 2 中,它是一个变量浏览器,显示内存中的每个变量及其包含的内容。这是调试代码的强大工具,因为它允许您快速查看代码在执行什么操作以及哪些地方无法正常工作。
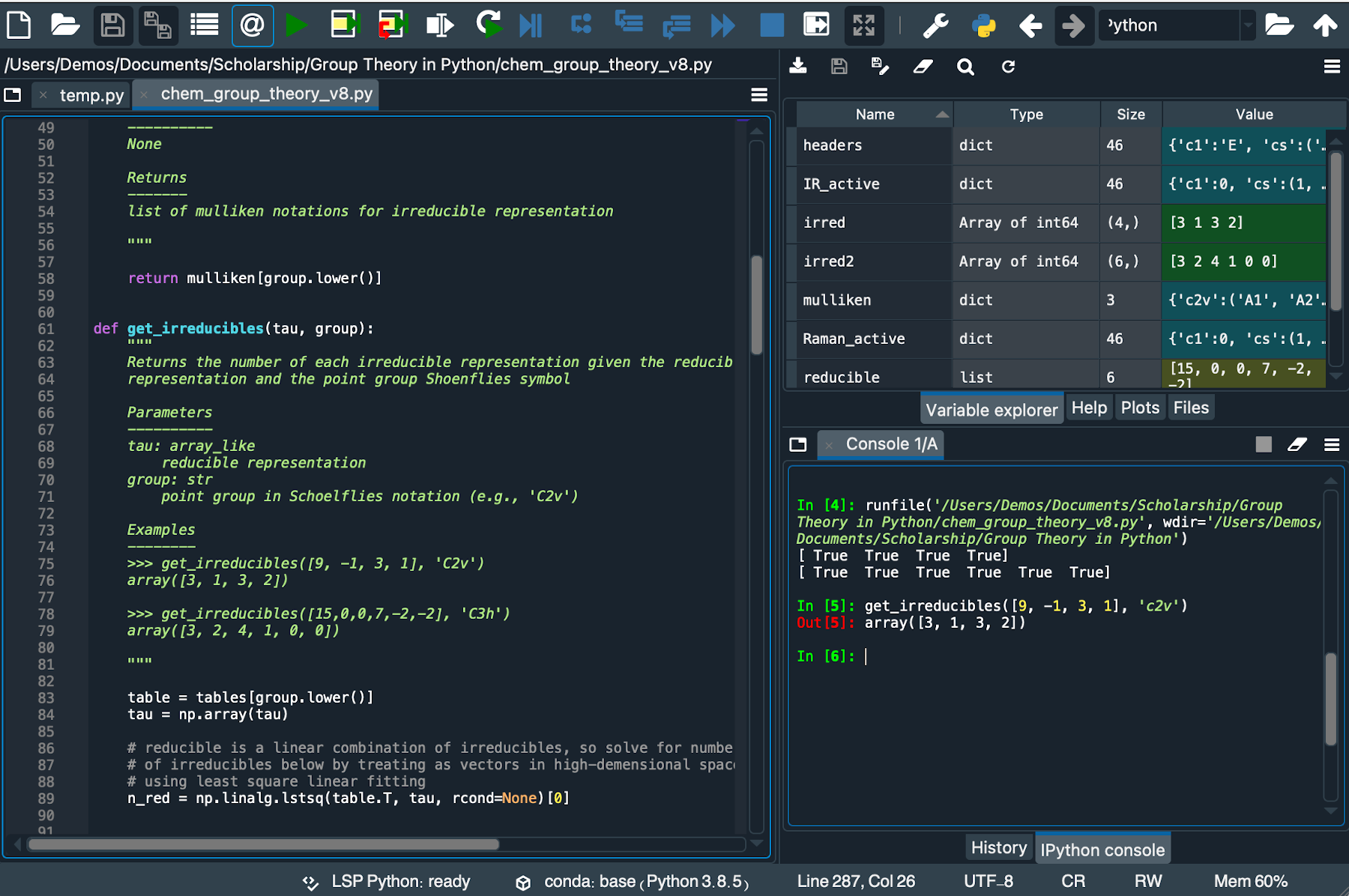
图 2 Spyder 界面,包括文本编辑器(左)、变量浏览器(右上)和解释器(右下)。
那么何时应该使用 Jupyter 笔记本,何时应该使用 Spyder 呢?这个决定通常是个人喜好的问题,但如果您正在进行交互式数据分析,Jupyter 笔记本通常是更好的选择。如果您需要与他人共享分析和结果,这尤其正确。如果您正在编写大量代码,Spyder 可能是更好的环境选择。举个例子,如果您希望从外部数据集中执行复杂的信息挖掘,然后分析生成的信息,您可能希望在 Spyder 中编写数据挖掘代码,然后在 Jupyter 笔记本中运行数据分析。
推荐阅读
- Spyder 官网。https://www.spyder-ide.org/(免费资源)
练习
- 当氢原子中的电子从高能量轨道放松到低能量轨道时,会释放出波长为 nm 的光子,
如下方程所示。编写并运行一个 Python 脚本,提示用户输入初始和最终的主量子数(n),并打印出发射光的波长(λ)及其单位。
- 在名为 data 的文件夹中,您将找到 A P 转换的合成数据。这两个数据集都是一阶反应的数据。
a) 编写一个 Python 脚本,该脚本接受单个数据文件名,如下所示,并输出数据的速率常数(k)。请在这两个数据集上测试。要让脚本找到文件,它需要位于与数据文件相同的目录中,或者提供文件的绝对路径。
$ python script.py kinetic_data_1.csv
或
$ python script.py /Users/Me/Desktop/kinetic_data_1.csv
b) 修改上述脚本,以打印文件夹中所有数据集的速率常数。该脚本将接受文件夹名称而不是文件名称。请记住使用 第 2.4.1 节中描述的 os 模块。


𝘽𝘼𝙊